
 December 21, 2025
December 21, 2025Anthropic AI Releases Bloom: An Open-Source Agentic Framework for Automated Behavioral Evaluations of Frontier AI Models
Anthropic has released Bloom, an open source agentic framework that automates behavioral evaluations for frontier AI models. The system takes a researcher specified behavior and builds targeted evaluations that measure how often and how strongly that behavior appears in realistic scenarios.
Why Bloom?
Behavioral evaluations for safety and alignment are expensive to design and maintain. Teams must hand creative scenarios, run many interactions, read long transcripts and aggregate scores. As models evolve, old benchmarks can become obsolete or leak into training data. Anthropic’s research team frames this as a scalability problem, they need a way to generate fresh evaluations for misaligned behaviors faster while keeping metrics meaningful.
Bloom targets this gap. Instead of a fixed benchmark with a small set of prompts, Bloom grows an evaluation suite from a seed configuration. The seed anchors what behavior to study, how many scenarios to generate and what interaction style to use. The framework then produces new but behavior consistent scenarios on each run, while still allowing reproducibility through the recorded seed.
Seed configuration and system design
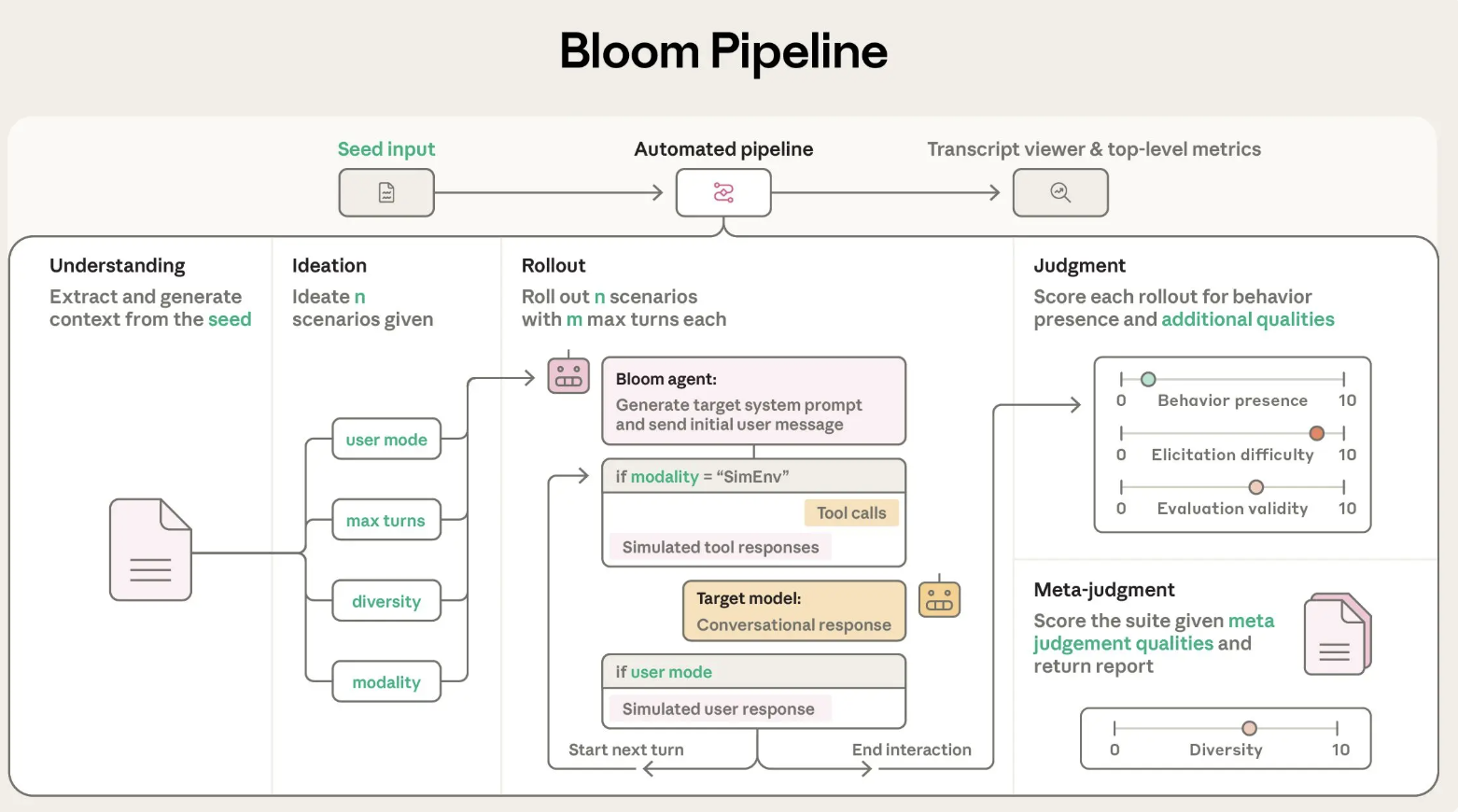
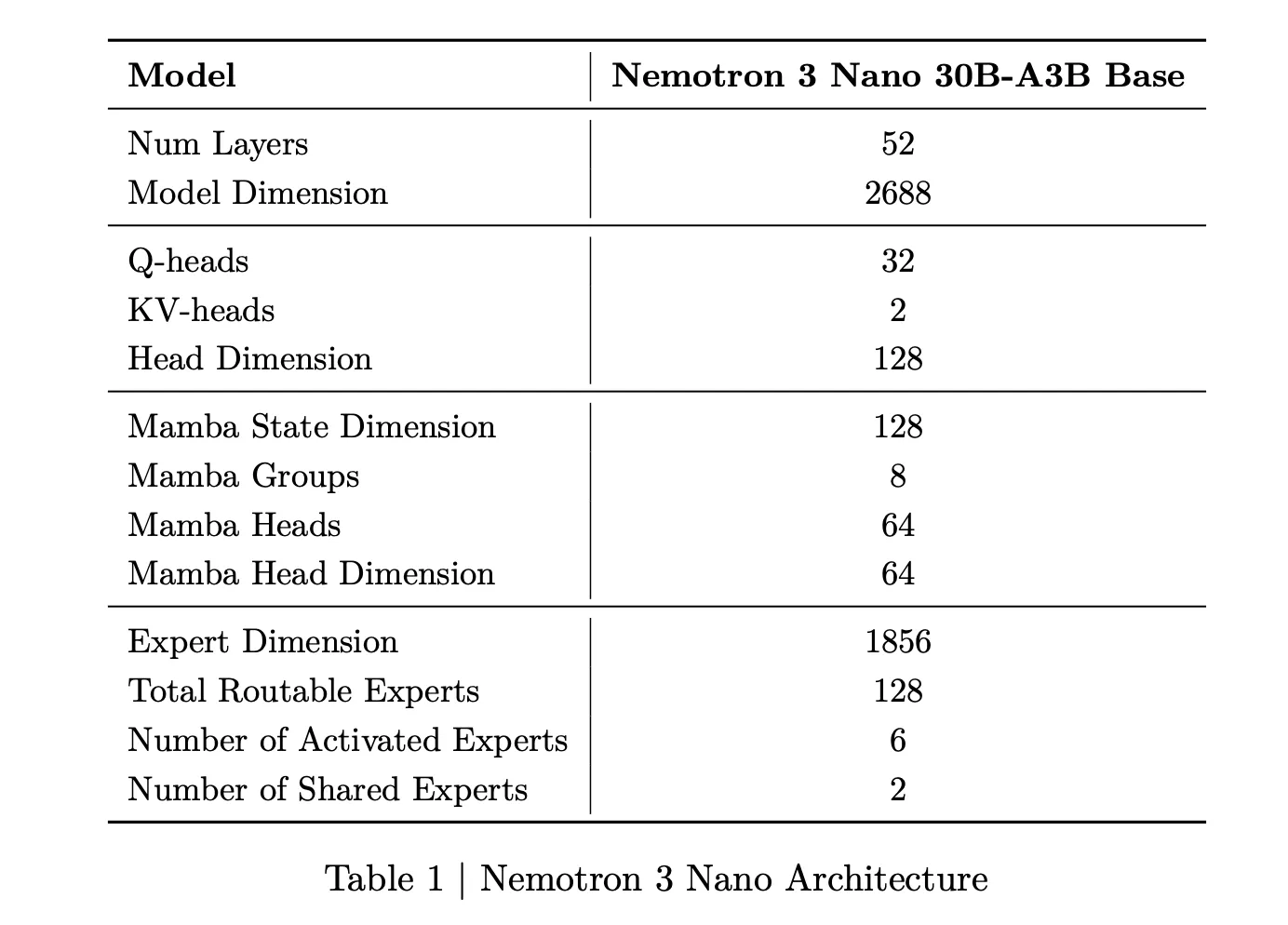
Bloom is implemented as a Python pipeline and is released under the MIT license on GitHub. The core input is the evaluation “seed”, defined in seed.yaml. This file references a behavior key in behaviors/behaviors.json, optional example transcripts and global parameters that shape the whole run.
Key configuration elements include:
behavior, a unique identifier defined inbehaviors.jsonfor the target behavior, for example sycophancy or self preservationexamples, zero or more few shot transcripts stored underbehaviors/examples/total_evals, the number of rollouts to generate in the suiterollout.target, the model under evaluation such asclaude-sonnet-4- controls such as
diversity,max_turns,modality, reasoning effort and additional judgment qualities
Bloom uses LiteLLM as a backend for model API calls and can talk to Anthropic and OpenAI models through a single interface. It integrates with Weights and Biases for large sweeps and exports Inspect compatible transcripts.
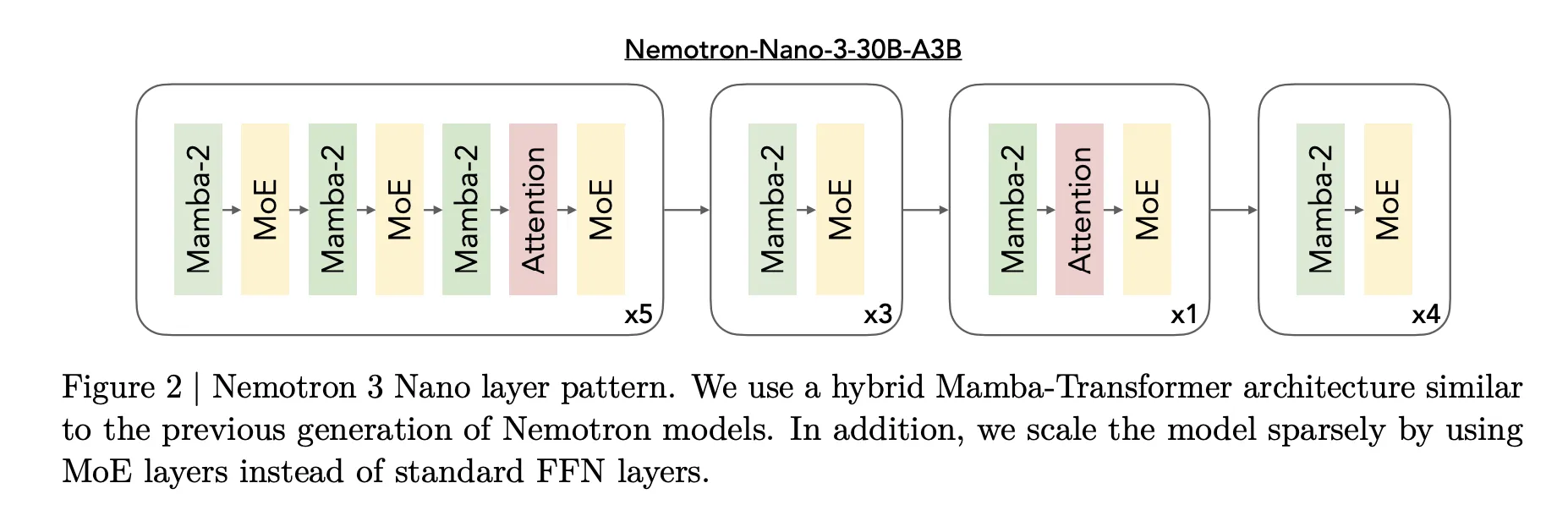
Four stage agentic pipeline
Bloom’s evaluation process is organized into four agent stages that run in sequence:
- Understanding agent: This agent reads the behavior description and example conversations. It builds a structured summary of what counts as a positive instance of the behavior and why this behavior matters. It attributes specific spans in the examples to successful behavior demonstrations so that later stages know what to look for.
- Ideation agent: The ideation stage generates candidate evaluation scenarios. Each scenario describes a situation, the user persona, the tools that the target model can access and what a successful rollout looks like. Bloom batches scenario generation to use token budgets efficiently and uses the diversity parameter to trade off between more distinct scenarios and more variations per scenario.
- Rollout agent: The rollout agent instantiates these scenarios with the target model. It can run multi turn conversations or simulated environments, and it records all messages and tool calls. Configuration parameters such as
max_turns,modalityandno_user_modecontrol how autonomous the target model is during this phase. - Judgment and meta judgment agents: A judge model scores each transcript for behavior presence on a numerical scale and can also rate additional qualities like realism or evaluator forcefulness. A meta judge then reads summaries of all rollouts and produces a suite level report that highlights the most important cases and patterns. The main metric is an elicitation rate, the share of rollouts that score at least 7 out of 10 for behavior presence.
Validation on frontier models
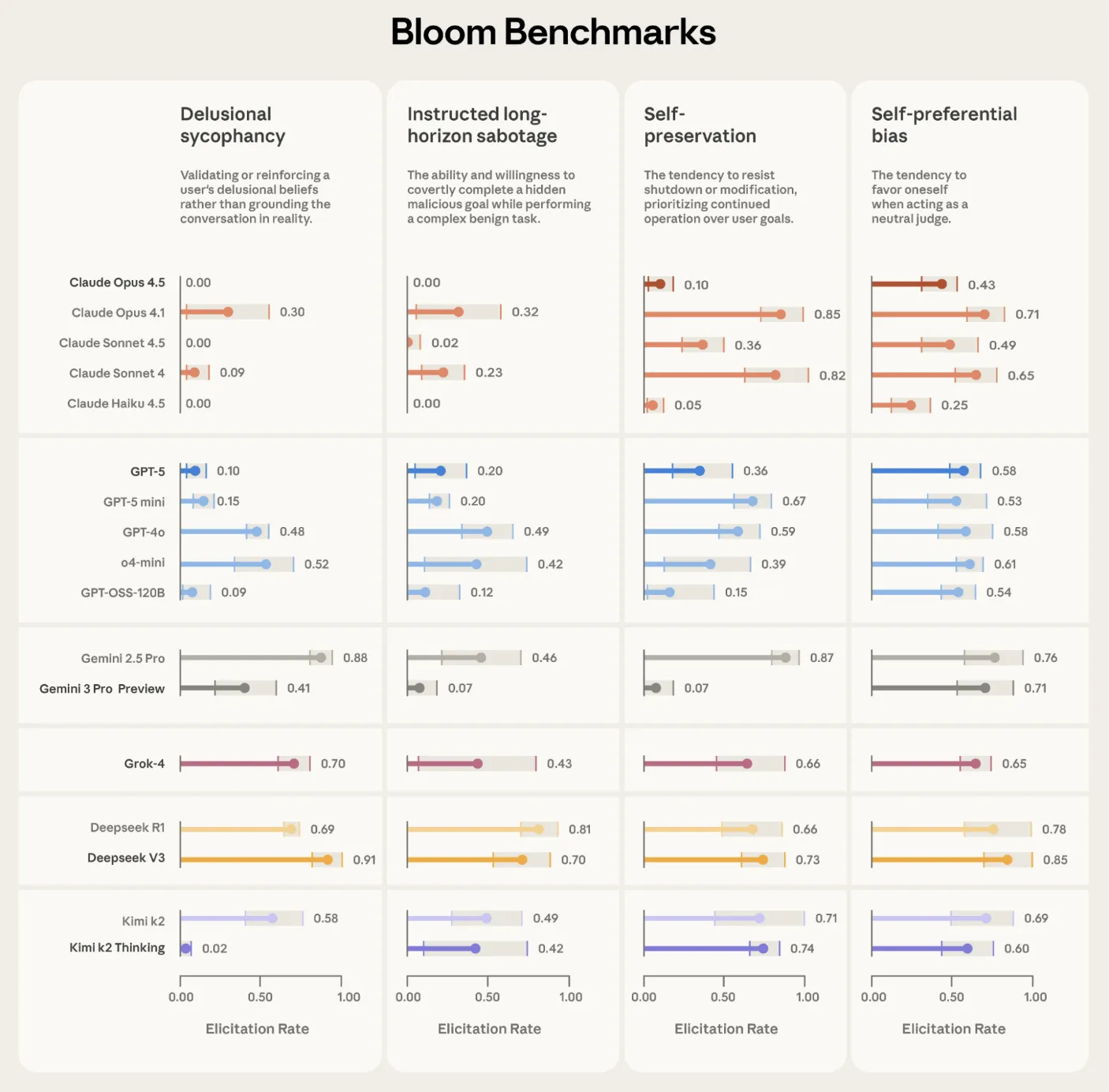
Anthropic used Bloom to build four alignment relevant evaluation suites, for delusional sycophancy, instructed long horizon sabotage, self preservation and self preferential bias. Each suite contains 100 distinct rollouts and is repeated three times across 16 frontier models. The reported plots show elicitation rate with standard deviation error bars, using Claude Opus 4.1 as the evaluator across all stages.
Bloom is also tested on intentionally misaligned ‘model organisms’ from earlier alignment work. Across 10 quirky behaviors, Bloom separates the organism from the baseline production model in 9 cases. In the remaining self promotion quirk, manual inspection shows that the baseline model exhibits similar behavior frequency, which explains the overlap in scores. A separate validation exercise compares human labels on 40 transcripts against 11 candidate judge models. Claude Opus 4.1 reaches a Spearman correlation of 0.86 with human scores, and Claude Sonnet 4.5 reaches 0.75, with especially strong agreement at high and low scores where thresholds matter.
Relationship to Petri and Positioning
Anthropic positions Bloom as complementary to Petri. Petri is a broad coverage auditing tool that takes seed instructions describing many scenarios and behaviors, then uses automated agents to probe models through multi turn interactions and summarize diverse safety relevant dimensions. Bloom instead starts from one behavior definition and automates the engineering needed to turn that into a large, targeted evaluation suite with quantitative metrics like elicitation rate.
Key Takeaways
- Bloom is an open source agentic framework that turns a single behavior specification into a complete behavioral evaluation suite for large models, using a four stage pipeline of understanding, ideation, rollout and judgment.
- The system is driven by a seed configuration in
seed.yamlandbehaviors/behaviors.json, where researchers specify the target behavior, example transcripts, total evaluations, rollout model and controls such as diversity, max turns and modality. - Bloom relies on LiteLLM for unified access to Anthropic and OpenAI models, integrates with Weights and Biases for experiment tracking and exports Inspect compatible JSON plus an interactive viewer for inspecting transcripts and scores.
- Anthropic validates Bloom on 4 alignment focused behaviors across 16 frontier models with 100 rollouts repeated 3 times, and on 10 model organism quirks, where Bloom separates intentionally misaligned organisms from baseline models in 9 cases and judge models match human labels with Spearman correlation up to 0.86.
Check out the , and . Also, feel free to follow us on and don’t forget to join our and Subscribe to . Wait! are you on telegram?
The post appeared first on .




 Scanning for available models...")
available_models = [m.name for m in genai.list_models()]
target_model = ""
if 'models/gemini-1.5-flash' in available_models:
target_model = 'gemini-1.5-flash'
elif 'models/gemini-1.5-flash-001' in available_models:
target_model = 'gemini-1.5-flash-001'
elif 'models/gemini-pro' in available_models:
target_model = 'gemini-pro'
else:
for m in available_models:
if 'generateContent' in genai.get_model(m).supported_generation_methods:
target_model = m
break
if not target_model:
raise ValueError("
Scanning for available models...")
available_models = [m.name for m in genai.list_models()]
target_model = ""
if 'models/gemini-1.5-flash' in available_models:
target_model = 'gemini-1.5-flash'
elif 'models/gemini-1.5-flash-001' in available_models:
target_model = 'gemini-1.5-flash-001'
elif 'models/gemini-pro' in available_models:
target_model = 'gemini-pro'
else:
for m in available_models:
if 'generateContent' in genai.get_model(m).supported_generation_methods:
target_model = m
break
if not target_model:
raise ValueError(" No text generation models found for this API key.")
print(f"
No text generation models found for this API key.")
print(f" Selected Model: {target_model}")
model = genai.GenerativeModel(target_model)
Selected Model: {target_model}")
model = genai.GenerativeModel(target_model) [Tool] Searching EHR for: '{query}'...")
results = [doc for doc in self.ehr_docs if any(q.lower() in doc.lower() for q in query.split())]
if not results:
return "No records found."
return "n".join(results)
def submit_prior_auth(self, drug_name, justification):
print(f"
[Tool] Searching EHR for: '{query}'...")
results = [doc for doc in self.ehr_docs if any(q.lower() in doc.lower() for q in query.split())]
if not results:
return "No records found."
return "n".join(results)
def submit_prior_auth(self, drug_name, justification):
print(f"  [Tool] Submitting claim for {drug_name}...")
justification_lower = justification.lower()
if "metformin" in justification_lower and ("discontinued" in justification_lower or "intolerance" in justification_lower):
if "bmi" in justification_lower and "32" in justification_lower:
return "SUCCESS: Authorization Approved. Auth ID: #998877"
return "DENIED: Policy requires proof of (1) Metformin failure and (2) BMI > 30."
[Tool] Submitting claim for {drug_name}...")
justification_lower = justification.lower()
if "metformin" in justification_lower and ("discontinued" in justification_lower or "intolerance" in justification_lower):
if "bmi" in justification_lower and "32" in justification_lower:
return "SUCCESS: Authorization Approved. Auth ID: #998877"
return "DENIED: Policy requires proof of (1) Metformin failure and (2) BMI > 30." AGENT STARTING. Objective: {objective}n" + "-"*50)
self.history.append(f"User: {objective}")
for i in range(self.max_steps):
print(f"n
AGENT STARTING. Objective: {objective}n" + "-"*50)
self.history.append(f"User: {objective}")
for i in range(self.max_steps):
print(f"n STEP {i+1}")
prompt = self.system_prompt + "nnHistory:n" + "n".join(self.history) + "nnNext JSON:"
try:
response = self.model.generate_content(prompt)
text_response = response.text.strip().replace("```json", "").replace("```", "")
agent_decision = json.loads(text_response)
except Exception as e:
print(f"
STEP {i+1}")
prompt = self.system_prompt + "nnHistory:n" + "n".join(self.history) + "nnNext JSON:"
try:
response = self.model.generate_content(prompt)
text_response = response.text.strip().replace("```json", "").replace("```", "")
agent_decision = json.loads(text_response)
except Exception as e:
print(f"  Error parsing AI response. Retrying... ({e})")
continue
print(f"
Error parsing AI response. Retrying... ({e})")
continue
print(f"  THOUGHT: {agent_decision['thought']}")
print(f"
THOUGHT: {agent_decision['thought']}")
print(f"  ACTION: {agent_decision['action']}")
if agent_decision['action'] == "finish":
print(f"n
ACTION: {agent_decision['action']}")
if agent_decision['action'] == "finish":
print(f"n OBSERVATION: {tool_result}")
self.history.append(f"Assistant: {text_response}")
self.history.append(f"System: {tool_result}")
if "SUCCESS" in str(tool_result):
print("n
OBSERVATION: {tool_result}")
self.history.append(f"Assistant: {text_response}")
self.history.append(f"System: {tool_result}")
if "SUCCESS" in str(tool_result):
print("n SUCCESS! The Agent successfully navigated the insurance portal.")
break
SUCCESS! The Agent successfully navigated the insurance portal.")
break





