













Sirius's editing and formatting skills transformed my manuscript into a polished piece of art. Their meticulous attention to grammar, structure, and overall flow made my book shine. Professional, prompt, and a joy to work with!
I was very impresed by the digital services lorem ipsum is simply free text available used by copy typing refreshing. Neque porro noting est qui dolorem ipsum quia.e.
I couldn't have managed my workload without Sirius's virtual assistance! They handled tasks efficiently, from scheduling to research, freeing up my time to focus on what matters most. Reliable, proactive, and always delivering exceptional results.
Sirius's expertise in social media management has significantly boosted our online presence. They strategized effectively, creating engaging content that resonates with our audience. Their insights and dedication have been instrumental in our growth!
Sirius is a versatile Agency across multiple digital services. Whether it's designing websites, editing books, managing social media, or providing virtual assistance, they bring expertise, creativity, and reliability to every project. Highly recommended for anyone looking to elevate their digital presence!



 08 Feb, 2026
08 Feb, 2026SBA Moves to Bypass Red Tape for Wildfire Survivors in California
 08 Feb, 2026
08 Feb, 20267 Top Personnel Management Software Solutions
 08 Feb, 2026
08 Feb, 2026Top 5 Online Payroll Software Solutions for Small Businesses
 08 Feb, 2026
08 Feb, 2026How Does a Point of Sale System Work?
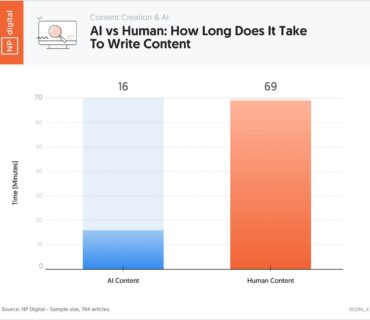 08 Feb, 2026
08 Feb, 2026AI Content Generation for SEO: Pros, Cons & How to Use It
 08 Feb, 2026
08 Feb, 2026
Working with Sirius Digitals on my website design was an absolute pleasure! They listened attentively to my ideas and translated them into a visually stunning and user-friendly website. Their attention to detail and creativity truly set my site apart. Highly recommend!