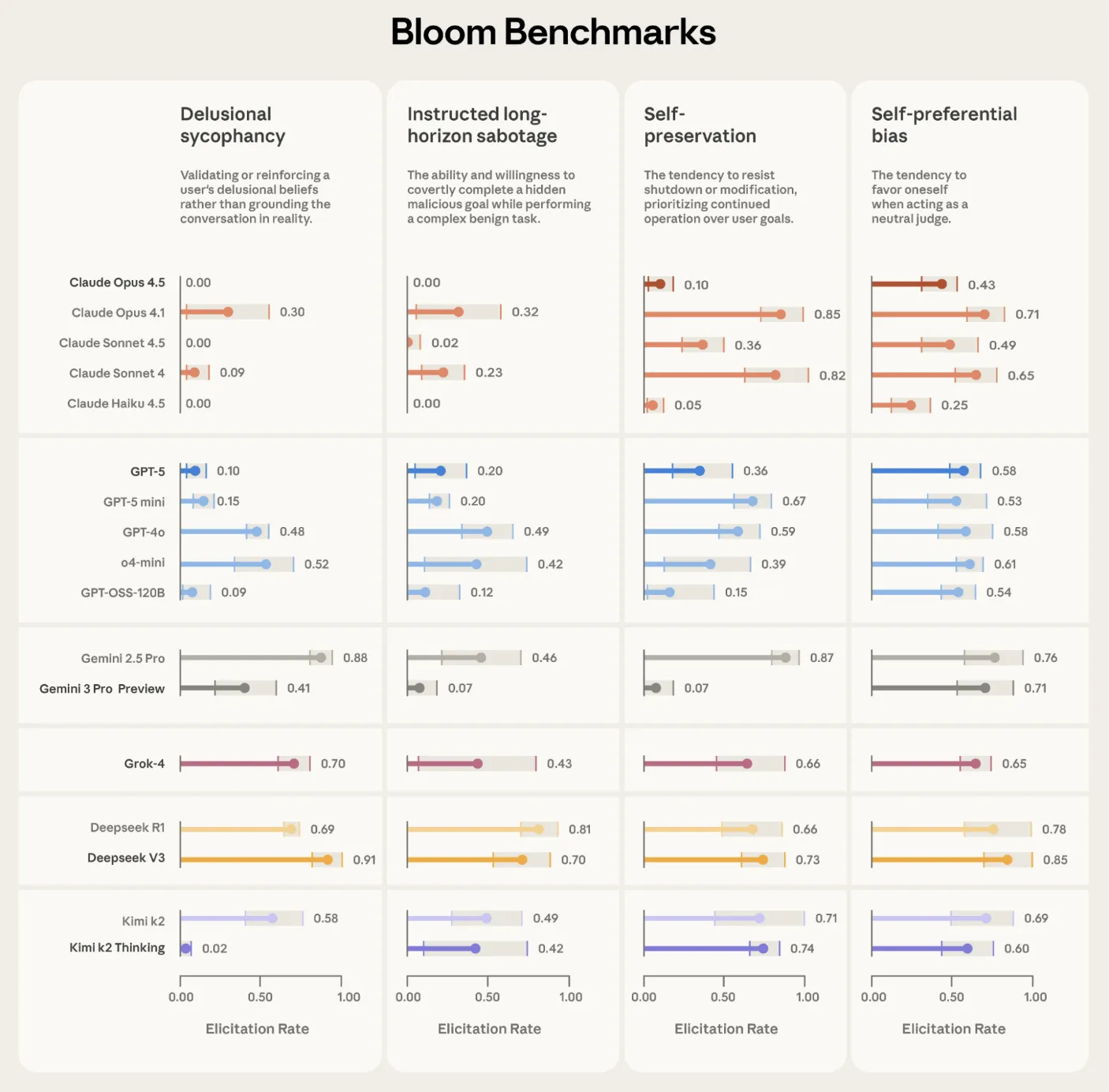
December 25, 2025
December 25, 2025A Coding Guide to Build an Autonomous Multi-Agent Logistics System with Route Planning, Dynamic Auctions, and Real-Time Visualization Using Graph-Based Simulation
In this tutorial, we build an advanced, fully autonomous logistics simulation in which multiple smart delivery trucks operate within a dynamic city-wide road network. We design the system so that each truck behaves as an agent capable of bidding on delivery orders, planning optimal routes, managing battery levels, seeking charging stations, and maximizing profit through self-interested decision-making. Through each code snippet, we explore how agentic behaviors emerge from simple rules, how competition shapes order allocation, and how a graph-based world enables realistic movement, routing, and resource constraints. Check out the .
import networkx as nx
import matplotlib.pyplot as plt
import random
import time
from IPython.display import clear_output
from dataclasses import dataclass, field
from typing import List, Dict, Optional
NUM_NODES = 30
CONNECTION_RADIUS = 0.25
NUM_AGENTS = 5
STARTING_BALANCE = 1000
FUEL_PRICE = 2.0
PAYOUT_MULTIPLIER = 5.0
BATTERY_CAPACITY = 100
CRITICAL_BATTERY = 25
@dataclass
class Order:
id: str
target_node: int
weight_kg: int
payout: float
status: str = "pending"
class AgenticTruck:
def __init__(self, agent_id, start_node, graph, capacity=100):
self.id = agent_id
self.current_node = start_node
self.graph = graph
self.battery = BATTERY_CAPACITY
self.balance = STARTING_BALANCE
self.capacity = capacity
self.state = "IDLE"
self.path: List[int] = []
self.current_order: Optional[Order] = None
self.target_node: int = start_nodeWe set up all the core building blocks of the simulation, including imports, global parameters, and the basic data structures. We also define the AgenticTruck class and initialize key attributes, including position, battery, balance, and operating state. We lay the foundation for all agent behaviors to evolve. Check out the .
def get_path_cost(self, start, end):
try:
length = nx.shortest_path_length(self.graph, start, end, weight='weight')
path = nx.shortest_path(self.graph, start, end, weight='weight')
return length, path
except nx.NetworkXNoPath:
return float('inf'), []
def find_nearest_charger(self):
chargers = [n for n, attr in self.graph.nodes(data=True) if attr.get('type') == 'charger']
best_charger = None
min_dist = float('inf')
best_path = []
for charger in chargers:
dist, path = self.get_path_cost(self.current_node, charger)
if dist < min_dist:
min_dist = dist
best_charger = charger
best_path = path
return best_charger, best_path
def calculate_bid(self, order):
if order.weight_kg > self.capacity:
return float('inf')
if self.state != "IDLE" or self.battery < CRITICAL_BATTERY:
return float('inf')
dist_to_target, _ = self.get_path_cost(self.current_node, order.target_node)
fuel_cost = dist_to_target * FUEL_PRICE
expected_profit = order.payout - fuel_cost
if expected_profit < 10:
return float('inf')
return dist_to_target
def assign_order(self, order):
self.current_order = order
self.state = "MOVING"
self.target_node = order.target_node
_, self.path = self.get_path_cost(self.current_node, self.target_node)
if self.path: self.path.pop(0)
def go_charge(self):
charger_node, path = self.find_nearest_charger()
if charger_node is not None:
self.state = "TO_CHARGER"
self.target_node = charger_node
self.path = path
if self.path: self.path.pop(0)We implement advanced decision-making logic for the trucks. We calculate shortest paths, identify nearby charging stations, and evaluate whether an order is profitable and feasible. We also prepare the truck to accept assignments or proactively seek charging when needed. Check out the .
def step(self):
if self.state == "IDLE" and self.battery < CRITICAL_BATTERY:
self.go_charge()
if self.state == "CHARGING":
self.battery += 10
self.balance -= 5
if self.battery >= 100:
self.battery = 100
self.state = "IDLE"
return
if self.path:
next_node = self.path[0]
edge_data = self.graph.get_edge_data(self.current_node, next_node)
distance = edge_data['weight']
self.current_node = next_node
self.path.pop(0)
self.battery -= (distance * 2)
self.balance -= (distance * FUEL_PRICE)
if not self.path:
if self.state == "MOVING":
self.balance += self.current_order.payout
self.current_order.status = "completed"
self.current_order = None
self.state = "IDLE"
elif self.state == "TO_CHARGER":
self.state = "CHARGING"We manage the step-by-step actions of each truck as the simulation runs. We handle battery recharging, financial impacts of movement, fuel consumption, and order completion. We ensure that agents transition smoothly between states, such as moving, charging, and idling. Check out the .
class Simulation:
def __init__(self):
self.setup_graph()
self.setup_agents()
self.orders = []
self.order_count = 0
def setup_graph(self):
self.G = nx.random_geometric_graph(NUM_NODES, CONNECTION_RADIUS)
for (u, v) in self.G.edges():
self.G.edges[u, v]['weight'] = random.uniform(1.0, 3.0)
for i in self.G.nodes():
r = random.random()
if r < 0.15:
self.G.nodes[i]['type'] = 'charger'
self.G.nodes[i]['color'] = 'red'
else:
self.G.nodes[i]['type'] = 'house'
self.G.nodes[i]['color'] = '#A0CBE2'
def setup_agents(self):
self.agents = []
for i in range(NUM_AGENTS):
start_node = random.randint(0, NUM_NODES-1)
cap = random.choice([50, 100, 200])
self.agents.append(AgenticTruck(i, start_node, self.G, capacity=cap))
def generate_order(self):
target = random.randint(0, NUM_NODES-1)
weight = random.randint(10, 120)
payout = random.randint(50, 200)
order = Order(id=f"ORD-{self.order_count}", target_node=target, weight_kg=weight, payout=payout)
self.orders.append(order)
self.order_count += 1
return order
def run_market(self):
for order in self.orders:
if order.status == "pending":
bids = {agent: agent.calculate_bid(order) for agent in self.agents}
valid_bids = {k: v for k, v in bids.items() if v != float('inf')}
if valid_bids:
winner = min(valid_bids, key=valid_bids.get)
winner.assign_order(order)
order.status = "assigned"We create the simulated world and orchestrate agent interactions. We generate the graph-based city, spawn trucks with varying capacities, and produce new delivery orders. We also implement a simple market where agents bid for tasks based on profitability and distance. Check out the .
def step(self):
if random.random() < 0.3:
self.generate_order()
self.run_market()
for agent in self.agents:
agent.step()
def visualize(self, step_num):
clear_output(wait=True)
plt.figure(figsize=(10, 8))
pos = nx.get_node_attributes(self.G, 'pos')
node_colors = [self.G.nodes[n]['color'] for n in self.G.nodes()]
nx.draw(self.G, pos, node_color=node_colors, with_labels=True, node_size=300, edge_color='gray', alpha=0.6)
for agent in self.agents:
x, y = pos[agent.current_node]
jitter_x = x + random.uniform(-0.02, 0.02)
jitter_y = y + random.uniform(-0.02, 0.02)
color = 'green' if agent.state == "IDLE" else ('orange' if agent.state == "MOVING" else 'red')
plt.plot(jitter_x, jitter_y, marker='s', markersize=12, color=color, markeredgecolor='black')
plt.text(jitter_x, jitter_y+0.03, f"A{agent.id}n${int(agent.balance)}n{int(agent.battery)}%",
fontsize=8, ha='center', fontweight='bold', bbox=dict(facecolor='white', alpha=0.7, pad=1))
for order in self.orders:
if order.status in ["assigned", "pending"]:
ox, oy = pos[order.target_node]
plt.plot(ox, oy, marker='*', markersize=15, color='gold', markeredgecolor='black')
plt.title(f"Graph-Based Logistics Swarm | Step: {step_num}nRed Nodes = Chargers | Gold Stars = Orders", fontsize=14)
plt.show()
print("Initializing Advanced Simulation...")
sim = Simulation()
for t in range(60):
sim.step()
sim.visualize(t)
time.sleep(0.5)
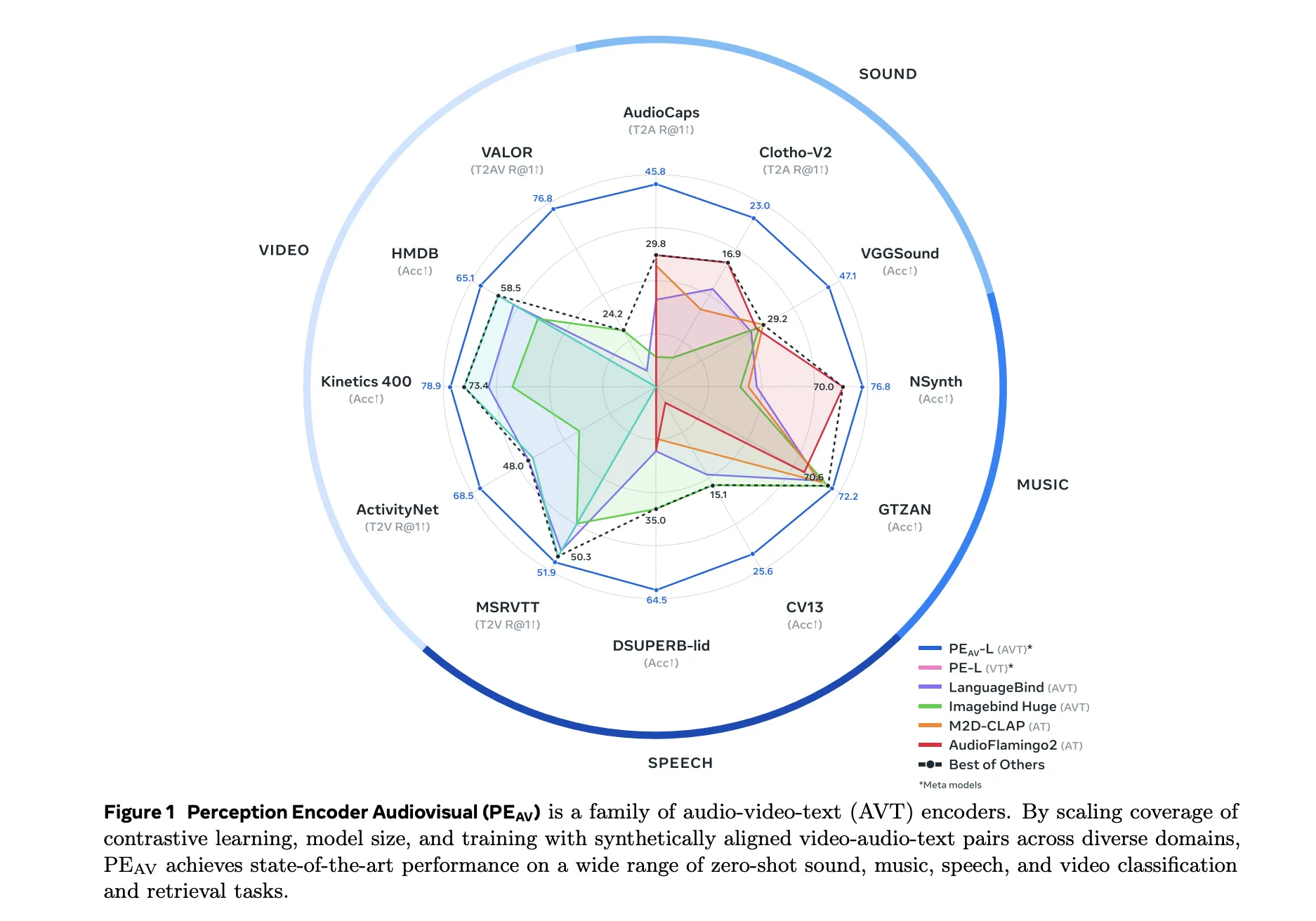
print("Simulation Finished.")We step through the full simulation loop and visualize the logistics swarm in real time. We update agent states, draw the network, display active orders, and animate each truck’s movement. By running this loop, we observe the emergent coordination and competition that define our multi-agent logistics ecosystem.
In conclusion, we saw how the individual components, graph generation, autonomous routing, battery management, auctions, and visualization, come together to form a living, evolving system of agentic trucks. We watch as agents negotiate workloads, compete for profitable opportunities, and respond to environmental pressures such as distance, fuel costs, and charging needs. By running the simulation, we observe emergent dynamics that mirror real-world fleet behavior, providing a powerful sandbox for experimenting with logistics intelligence.
Check out the . Also, feel free to follow us on and don’t forget to join our and Subscribe to . Wait! are you on telegram?
The post appeared first on .
 Security Check ---")
try:
api_key = userdata.get('GEMINI_API_KEY')
except:
print("Please enter your Google Gemini API Key:")
api_key = getpass.getpass("API Key: ")
if not api_key:
raise ValueError("API Key is required to run the agent.")
genai.configure(api_key=api_key)
return genai.GenerativeModel('gemini-2.5-flash')
class MockCustomerDB:
def __init__(self):
self.today = datetime.now()
self.users = self._generate_mock_users()
def _generate_mock_users(self) -> List[Dict]:
profiles = [
{"id": "U001", "name": "Sarah Connor", "plan": "Enterprise",
"last_login_days_ago": 2, "top_features": ["Reports", "Admin Panel"], "total_spend": 5000},
{"id": "U002", "name": "John Smith", "plan": "Basic",
"last_login_days_ago": 25, "top_features": ["Image Editor"], "total_spend": 50},
{"id": "U003", "name": "Emily Chen", "plan": "Pro",
"last_login_days_ago": 16, "top_features": ["API Access", "Data Export"], "total_spend": 1200},
{"id": "U004", "name": "Marcus Aurelius", "plan": "Enterprise",
"last_login_days_ago": 45, "top_features": ["Team Management"], "total_spend": 8000}
]
return profiles
def fetch_at_risk_users(self, threshold_days=14) -> List[Dict]:
return [u for u in self.users if u['last_login_days_ago'] >= threshold_days]
Security Check ---")
try:
api_key = userdata.get('GEMINI_API_KEY')
except:
print("Please enter your Google Gemini API Key:")
api_key = getpass.getpass("API Key: ")
if not api_key:
raise ValueError("API Key is required to run the agent.")
genai.configure(api_key=api_key)
return genai.GenerativeModel('gemini-2.5-flash')
class MockCustomerDB:
def __init__(self):
self.today = datetime.now()
self.users = self._generate_mock_users()
def _generate_mock_users(self) -> List[Dict]:
profiles = [
{"id": "U001", "name": "Sarah Connor", "plan": "Enterprise",
"last_login_days_ago": 2, "top_features": ["Reports", "Admin Panel"], "total_spend": 5000},
{"id": "U002", "name": "John Smith", "plan": "Basic",
"last_login_days_ago": 25, "top_features": ["Image Editor"], "total_spend": 50},
{"id": "U003", "name": "Emily Chen", "plan": "Pro",
"last_login_days_ago": 16, "top_features": ["API Access", "Data Export"], "total_spend": 1200},
{"id": "U004", "name": "Marcus Aurelius", "plan": "Enterprise",
"last_login_days_ago": 45, "top_features": ["Team Management"], "total_spend": 8000}
]
return profiles
def fetch_at_risk_users(self, threshold_days=14) -> List[Dict]:
return [u for u in self.users if u['last_login_days_ago'] >= threshold_days] Analyzing strategy for {user['name']}...")
prompt = f"""
You are a Customer Success AI Specialist.
Analyze this user profile and determine the best 'Win-Back Strategy'.
USER PROFILE:
- Name: {user['name']}
- Plan: {user['plan']}
- Days Inactive: {user['last_login_days_ago']}
- Favorite Features: {', '.join(user['top_features'])}
- Total Spend: ${user['total_spend']}
TASK:
1. Determine the 'Churn Probability' (Medium/High/Critical).
2. Select a specific INCENTIVE.
3. Explain your reasoning briefly.
OUTPUT FORMAT:
{{
"risk_level": "High",
"incentive_type": "Specific Incentive",
"reasoning": "One sentence explanation."
}}
"""
try:
response = self.model.generate_content(prompt)
clean_json = response.text.replace("```json", "").replace("```", "").strip()
return json.loads(clean_json)
except Exception as e:
return {
"risk_level": "Unknown",
"incentive_type": "General Check-in",
"reasoning": f"Analysis failed: {str(e)}"
}
Analyzing strategy for {user['name']}...")
prompt = f"""
You are a Customer Success AI Specialist.
Analyze this user profile and determine the best 'Win-Back Strategy'.
USER PROFILE:
- Name: {user['name']}
- Plan: {user['plan']}
- Days Inactive: {user['last_login_days_ago']}
- Favorite Features: {', '.join(user['top_features'])}
- Total Spend: ${user['total_spend']}
TASK:
1. Determine the 'Churn Probability' (Medium/High/Critical).
2. Select a specific INCENTIVE.
3. Explain your reasoning briefly.
OUTPUT FORMAT:
{{
"risk_level": "High",
"incentive_type": "Specific Incentive",
"reasoning": "One sentence explanation."
}}
"""
try:
response = self.model.generate_content(prompt)
clean_json = response.text.replace("```json", "").replace("```", "").strip()
return json.loads(clean_json)
except Exception as e:
return {
"risk_level": "Unknown",
"incentive_type": "General Check-in",
"reasoning": f"Analysis failed: {str(e)}"
} Drafting email for {user['name']} using '{strategy['incentive_type']}'...")
prompt = f"""
Write a short, empathetic, professional re-engagement email.
TO: {user['name']}
CONTEXT: They haven't logged in for {user['last_login_days_ago']} days.
STRATEGY: {strategy['incentive_type']}
REASONING: {strategy['reasoning']}
USER HISTORY: They love {', '.join(user['top_features'])}.
TONE: Helpful and concise.
"""
response = self.model.generate_content(prompt)
return response.text
Drafting email for {user['name']} using '{strategy['incentive_type']}'...")
prompt = f"""
Write a short, empathetic, professional re-engagement email.
TO: {user['name']}
CONTEXT: They haven't logged in for {user['last_login_days_ago']} days.
STRATEGY: {strategy['incentive_type']}
REASONING: {strategy['reasoning']}
USER HISTORY: They love {', '.join(user['top_features'])}.
TONE: Helpful and concise.
"""
response = self.model.generate_content(prompt)
return response.text REVIEW REQUIRED: Re-engagement for {user_name}")
print(f"
REVIEW REQUIRED: Re-engagement for {user_name}")
print(f" Strategy: {strategy['incentive_type']}")
print(f"
Strategy: {strategy['incentive_type']}")
print(f" Risk Level: {strategy['risk_level']}")
print("-" * 60)
print("
Risk Level: {strategy['risk_level']}")
print("-" * 60)
print(" DRAFT EMAIL:n")
print(textwrap.indent(draft_text, ' '))
print("-" * 60)
print("n[Auto-Simulation] Manager reviewing...")
time.sleep(1.5)
if strategy['risk_level'] == "Critical":
print("
DRAFT EMAIL:n")
print(textwrap.indent(draft_text, ' '))
print("-" * 60)
print("n[Auto-Simulation] Manager reviewing...")
time.sleep(1.5)
if strategy['risk_level'] == "Critical":
print(" MANAGER DECISION: Approved (Priority Send)")
return True
else:
print("
MANAGER DECISION: Approved (Priority Send)")
return True
else:
print(" AGENT STATUS: Scanning Database for inactive users (>14 days)...")
at_risk_users = db.fetch_at_risk_users(threshold_days=14)
print(f"Found {len(at_risk_users)} at-risk users.n")
for user in at_risk_users:
print(f"--- Processing Case: {user['id']} ({user['name']}) ---")
strategy = agent.analyze_and_strategize(user)
email_draft = agent.draft_engagement_email(user, strategy)
approved = manager.review_draft(user['name'], strategy, email_draft)
if approved:
print(f"
AGENT STATUS: Scanning Database for inactive users (>14 days)...")
at_risk_users = db.fetch_at_risk_users(threshold_days=14)
print(f"Found {len(at_risk_users)} at-risk users.n")
for user in at_risk_users:
print(f"--- Processing Case: {user['id']} ({user['name']}) ---")
strategy = agent.analyze_and_strategize(user)
email_draft = agent.draft_engagement_email(user, strategy)
approved = manager.review_draft(user['name'], strategy, email_draft)
if approved:
print(f" ACTION: Email queued for sending to {user['name']}.")
else:
print(f"
ACTION: Email queued for sending to {user['name']}.")
else:
print(f" ACTION: Email rejected.")
print("n")
time.sleep(1)
if __name__ == "__main__":
main()
ACTION: Email rejected.")
print("n")
time.sleep(1)
if __name__ == "__main__":
main()