 August 9, 2025
August 9, 2025How Older People Are Reaping Brain Benefits From New Tech
Overuse of digital gadgets harms teenagers, research suggests. But ubiquitous technology may be helping older Americans stay sharp.
Artificial Intelligence
 August 9, 2025
August 9, 2025
Artificial Intelligence
 August 9, 2025
August 9, 2025
Artificial Intelligence
 August 9, 2025
August 9, 2025
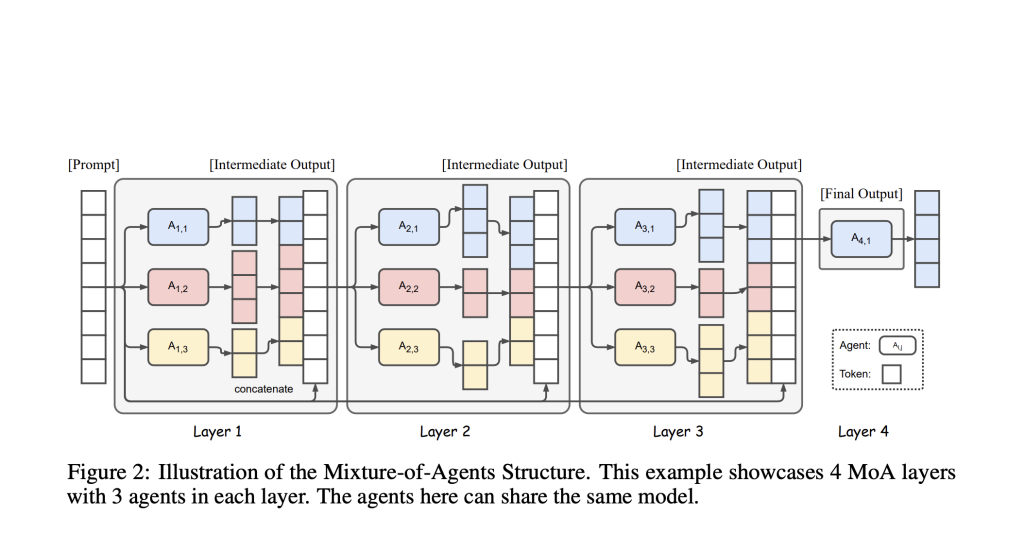
The Mixture-of-Agents (MoA) architecture is a transformative approach for enhancing large language model (LLM) performance, especially on complex, open-ended tasks where a single model can struggle with accuracy, reasoning, or domain specificity.
Imagine a medical diagnosis: one agent specializes in radiology, another in genomics, a third in pharmaceutical treatments. Each reviews a patient’s case from its own angle. Their conclusions are integrated and weighted, with higher-level aggregators assembling the best treatment recommendation. This approach is now being adapted to AI for everything from scientific analysis to financial planning, law, and complex document generation.
In summary, combining specialized AI agents—each with domain-specific expertise—through MoA architectures leads to more reliable, nuanced, and accurate outputs than any single LLM, especially for sophisticated, multi-dimensional tasks.
The post Mixture-of-Agents (MoA): A Breakthrough in LLM Performance appeared first on MarkTechPost.
MarkTechPost
 August 9, 2025
August 9, 2025
An AI agent is a goal-directed loop built around a capable model (often multimodal) and a set of tools/actuators. The loop typically includes:
Key difference from a plain assistant: agents act—they do not only answer; they execute workflows across software systems and UIs.
Limits: reliability drops with unstable selectors, auth flows, CAPTCHAs, ambiguous policies, or when success depends on tacit domain knowledge not present in tools/docs.
Benchmarks have improved and now better capture end-to-end computer use and web navigation. Success rates vary by task type and environment stability. Trends across public leaderboards show:
Takeaway: use benchmarks to compare strategies, but always validate on your own task distribution before production claims.
Yes—when scoped narrowly and instrumented well. Reported patterns include:
What’s less mature: broad, unbounded automation across heterogeneous processes.
Aim for a minimal, composable stack:
Design ethos: small planner, strong tools, strong evals.
Controls: allow-lists and typed schemas; deterministic tool wrappers; output validation; sandboxed browser/OS; scoped OAuth/API creds; rate limits; comprehensive audit logs; adversarial test suites; and periodic red-teaming.
Adopt a four-level evaluation ladder:
Continuously triage failures and back-propagate fixes into prompts, tools, and guardrails.
Use both.
Cost(task) ≈ Σ_i (prompt_tokens_i × $/tok)
+ Σ_j (tool_calls_j × tool_cost_j)
+ (browser_minutes × $/min)
Latency(task) ≈ model_time(thinking + generation)
+ Σ(tool_RTTs)
+ environment_steps_timeMain drivers: retries, browser step count, retrieval width, and post-hoc validation. Hybrid “code-as-action” can shorten long click-paths.
Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to Subscribe to our Newsletter.
The post FAQs: Everything You Need to Know About AI Agents in 2025 appeared first on MarkTechPost.
MarkTechPost
 August 9, 2025
August 9, 2025
Multimodal reasoning, where models integrate and interpret information from multiple sources such as text, images, and diagrams, is a frontier challenge in AI. VL-Cogito is a state-of-the-art Multimodal Large Language Model (MLLM) proposed by DAMO Academy (Alibaba Group) and partners, introducing a robust reinforcement learning pipeline that fundamentally upgrades the reasoning skills of large models across mathematics, science, logic, charts, and general understanding.
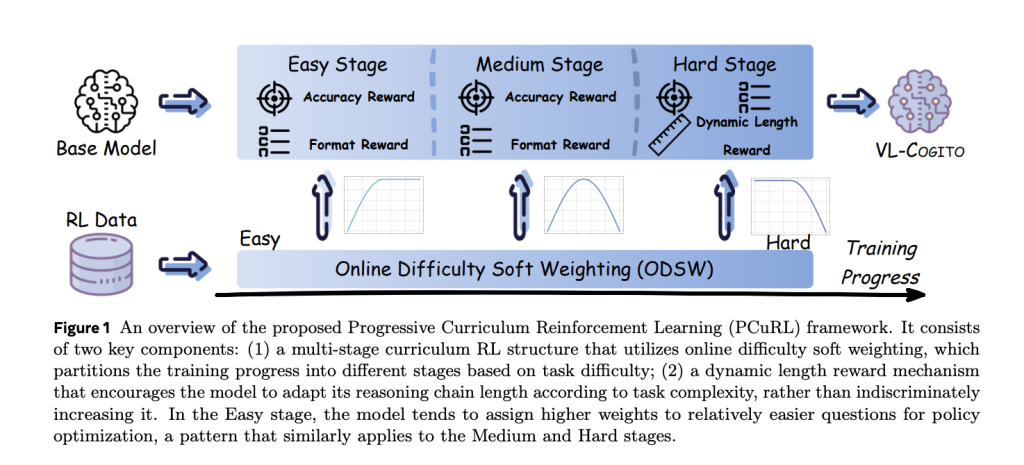
VL-Cogito’s unique approach centers around the Progressive Curriculum Reinforcement Learning (PCuRL) framework, engineered to systematically overcome the instability and domain gaps endemic to multimodal reasoning. The framework includes two breakthrough innovations:
VL-Cogito’s RL post-training starts directly from the Qwen2.5-VL-Instruct-7B backbone, with no initial supervised fine-tuning (SFT) cold start required. The PCuRL process is explicitly divided into three sequential RL stages: easy, medium, and hard. In each stage:
Technical setup details:
A meticulously curated training set covers 23 open-source multimodal datasets across six task categories: Mathematical Reasoning, Logical Reasoning, Counting, Science Reasoning, Chart Understanding, and General Image Understanding.
VL-Cogito is benchmarked against both general-purpose and reasoning-oriented MLLMs on a ten-task panel, including datasets like Geometry@3K, MathVerse, MathVista, ChartQA, ScienceQA, MMMU, EMMA, and MMStar.
| Model | Geo3K | MathVerse | MathVista | MathVision | LogicVista | ChartQA | SciQA | MMMU | EMMA | MMStar |
|---|---|---|---|---|---|---|---|---|---|---|
| VL-Cogito (7B) | 68.7 | 53.3 | 74.8 | 30.7 | 48.9 | 83.4 | 87.6 | 52.6 | 29.1 | 66.3 |
| VL-Rethinker (7B) | 67.7 | 54.6 | 73.7 | 30.1 | 45.7 | 83.5 | 86.7 | 52.9 | 28.6 | 64.2 |
| MM-Eureka (8B) | 67.2 | 52.3 | 73.4 | 29.4 | 47.1 | 82.7 | 86.4 | 52.3 | 27.4 | 64.7 |
| Qwen2.5-VL (7B) | 61.6 | 50.4 | 69.3 | 28.7 | 44.0 | 82.4 | 85.4 | 50.9 | 24.6 | 62.5 |
VL-Cogito exhibits detailed, self-reflective, stepwise reasoning. For math, the model decomposes solutions into granular chains and actively corrects missteps, a behavior instilled by RL verification and advantage estimation[1, Figure 5]. On classification-style problems (e.g., identifying decomposers or skyscrapers in images), it methodically considers each option before boxing the answer, demonstrating strong multimodal comprehension and process reliability.

VL-Cogito’s systematic PCuRL pipeline validates several key insights:
VL-Cogito’s architecture and training innovations set a new standard for multimodal reasoning across diverse benchmarks. The design and empirical validation of progressive curriculum RL with dynamic length rewards point toward a general roadmap for robust reasoning in multimodal models.
Check out the Paper. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post VL-Cogito: Advancing Multimodal Reasoning with Progressive Curriculum Reinforcement Learning appeared first on MarkTechPost.
MarkTechPost
 August 9, 2025
August 9, 2025
Alibaba’s Qwen team has introduced two powerful additions to its small language model lineup: Qwen3-4B-Instruct-2507 and Qwen3-4B-Thinking-2507. Despite having only 4 billion parameters, these models deliver exceptional capabilities across general-purpose and expert-level tasks while running efficiently on consumer-grade hardware. Both are designed with native 256K token context windows, meaning they can process extremely long inputs such as large codebases, multi-document archives, and extended dialogues without external modifications.
Both models feature 4 billion total parameters (3.6B excluding embeddings) built across 36 transformer layers. They use Grouped Query Attention (GQA) with 32 query heads and 8 key/value heads, enhancing efficiency and memory management for very large contexts. They are dense transformer architectures—not mixture-of-experts—which ensures consistent task performance. Long-context support up to 262,144 tokens is baked directly into the model architecture, and each model is pretrained extensively before undergoing alignment and safety post-training to ensure responsible, high-quality outputs.
The Qwen3-4B-Instruct-2507 model is optimized for speed, clarity, and user-aligned instruction following. It is designed to deliver direct answers without explicit step-by-step reasoning, making it perfect for scenarios where users want concise responses rather than detailed thought processes.
Multilingual coverage spans over 100 languages, making it highly suitable for global deployments in chatbots, customer support, education, and cross-language search. Its native 256K context support enables it to handle tasks like analyzing large legal documents, processing multi-hour transcripts, or summarizing massive datasets without splitting the content.
| Benchmark Task | Score |
|---|---|
| General Knowledge (MMLU-Pro) | 69.6 |
| Reasoning (AIME25) | 47.4 |
| SuperGPQA (QA) | 42.8 |
| Coding (LiveCodeBench) | 35.1 |
| Creative Writing | 83.5 |
| Multilingual Comprehension (MultiIF) | 69.0 |
In practice, this means Qwen3-4B-Instruct-2507 can handle everything from language tutoring in multiple languages to generating rich narrative content, while still providing competent performance in reasoning, coding, and domain-specific knowledge.
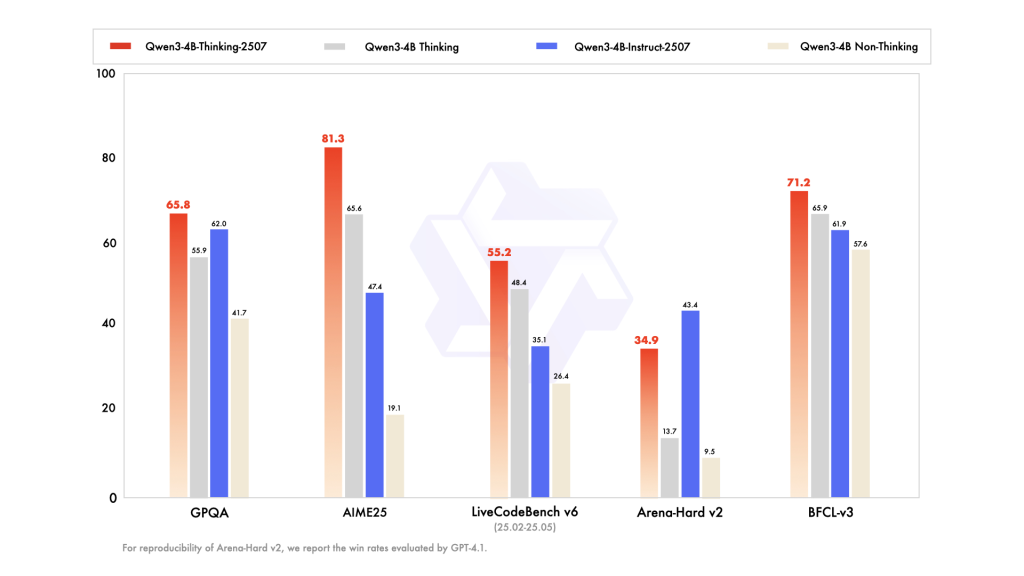
Where the Instruct model focuses on concise responsiveness, the Qwen3-4B-Thinking-2507 model is engineered for deep reasoning and problem-solving. It automatically generates explicit chains of thought in its outputs, making its decision-making process transparent—especially beneficial for complex domains like mathematics, science, and programming.
This model excels at technical diagnostics, scientific data interpretation, and multi-step logical analysis. It’s suited for advanced AI agents, research assistants, and coding companions that need to reason through problems before answering.
| Benchmark Task | Score |
|---|---|
| Math (AIME25) | 81.3% |
| Science (HMMT25) | 55.5% |
| General QA (GPQA) | 65.8% |
| Coding (LiveCodeBench) | 55.2% |
| Tool Usage (BFCL) | 71.2% |
| Human Alignment | 87.4% |
These scores demonstrate that Qwen3-4B-Thinking-2507 can match or even surpass much larger models in reasoning-heavy benchmarks, allowing more accurate and explainable results for mission-critical use cases.
Both the Instruct and Thinking variants share key advancements. The 256K native context window allows for seamless work on extremely long inputs without external memory hacks. They also feature improved alignment, producing more natural, coherent, and context-aware responses in creative and multi-turn conversations. Furthermore, both are agent-ready, supporting API calling, multi-step reasoning, and workflow orchestration out-of-the-box.
From a deployment perspective, they are highly efficient—capable of running on mainstream consumer GPUs with quantization for lower memory usage, and fully compatible with modern inference frameworks. This means developers can run them locally or scale them in cloud environments without significant resource investment.
Deployment is straightforward, with broad framework compatibility enabling integration into any modern ML pipeline. They can be used in edge devices, enterprise virtual assistants, research institutions, coding environments, and creative studios. Example scenarios include:
The Qwen3-4B-Instruct-2507 and Qwen3-4B-Thinking-2507 prove that small language models can rival and even outperform larger models in specific domains when engineered thoughtfully. Their blend of long-context handling, strong multilingual capabilities, deep reasoning (in Thinking mode), and alignment improvements makes them powerful tools for both everyday and specialist AI applications. With these releases, Alibaba has set a new benchmark in making 256K-ready, high-performance AI models accessible to developers worldwide.
Check out the Qwen3-4B-Instruct-2507 Model and Qwen3-4B-Thinking-2507 Model. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to Subscribe to our Newsletter.
The post Alibaba Qwen Unveils Qwen3-4B-Instruct-2507 and Qwen3-4B-Thinking-2507: Refreshing the Importance of Small Language Models appeared first on MarkTechPost.
MarkTechPost
 August 9, 2025
August 9, 2025
Empowering large language models (LLMs) to fluidly interact with dynamic, real-world environments is a new frontier for AI engineering. The Model Context Protocol (MCP) specification offers a standardized gateway through which LLMs can interface with arbitrary external systems—APIs, file systems, databases, applications, or tools—without needing custom glue code or brittle prompt hacks each time. Still, leveraging such toolsets programmatically, with robust reasoning across multi-step tasks, remains a formidable challenge.
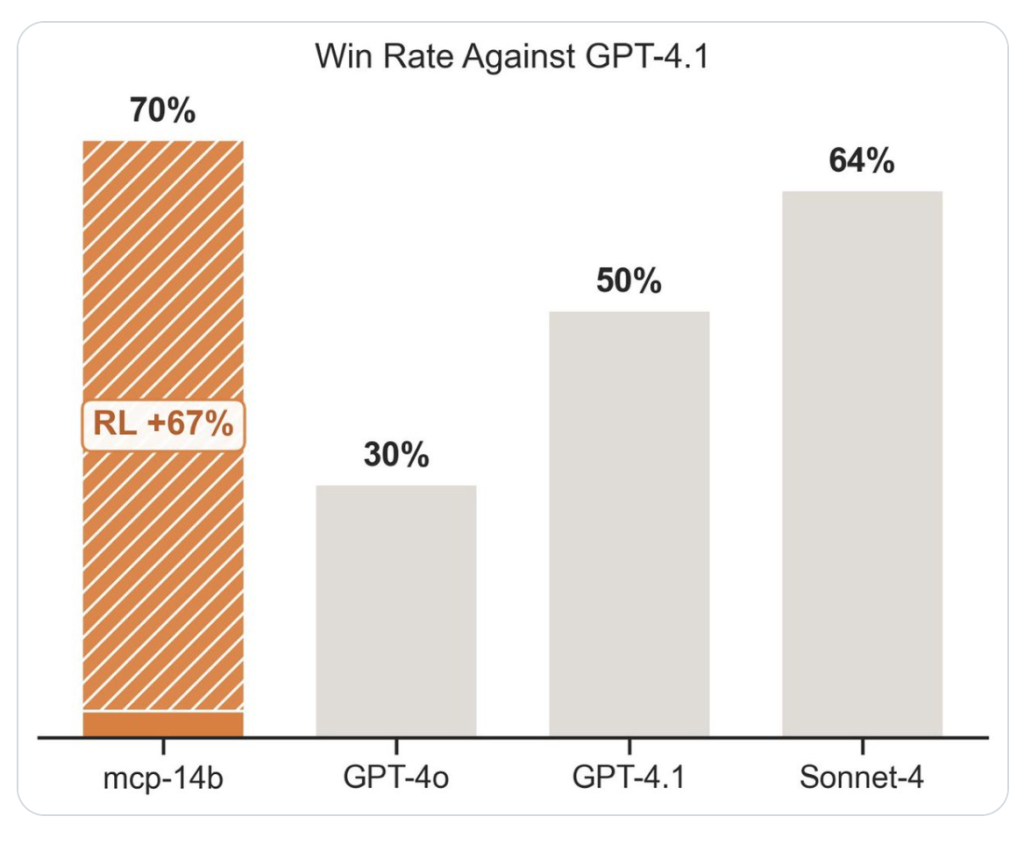
This is where the recent combination of MCP- RL (a reinforcement learning loop targeting MCP servers) and the open-source ART (Agent Reinforcement Trainer) library brings a paradigm shift: you can now have an agent probe, specialize, and self-optimize for any MCP service with minimal human design, no labeled data, and SOTA reliability. This article unpacks the exact mechanics, implementation pathways, and technical intricacies—down to code level—of this system.
MCP- RL is a meta-training protocol built to let any LLM agent learn, through reinforcement learning (RL), to operate the toolset exposed by an MCP server. MCP-RL is part of the Agent Reinforcement Trainer (ART) project. Given only the server’s URL:
This means an LLM can gain proficiency on any conformant toolbacked server—APIs for weather, databases, file search, ticketing, etc.—just by pointing MCP- RL at the right endpoint.
ART (Agent Reinforcement Trainer) provides the orchestrated RL pipeline underlying MCP- RL, supporting most vLLM/HuggingFace-compatible models (e.g. Qwen2.5, Qwen3, Llama, Kimi) and a distributed or local compute environment. ART is architected with:
The essence of the workflow is distilled in the following code excerpt from ART’s documentation:
from art.rewards import ruler_score_group
# Point to an MCP server (example: National Weather Service)
MCP_SERVER_URL = "https://server.smithery.ai/@smithery-ai/national-weather-service/mcp"
# Generate a batch of synthetic scenarios covering server tools
scenarios = await generate_scenarios(
num_scenarios=24,
server_url=MCP_SERVER_URL
)
# Run agent rollouts in parallel, collecting response trajectories
# Each trajectory = (system, user, assistant messages...)
# Assign rewards to each group using RULER's relative scoring
scored_groups = []
for group in groups:
judged_group = await ruler_score_group(group)
scored_groups.append(judged_group)
# Submit grouped trajectories for RL fine-tuning (GRPO)
await model.train(scored_groups)
generate_scenarios auto-designs diverse prompts/tasks based on the tools discovered from the MCP server.The loop repeats—each cycle making the agent more proficient at combining the server’s tools to solve the synthetic tasks.
| Component | Description |
|---|---|
| ART Client | Orchestrates agent rollouts, sends/receives messages, batches rewards |
| ART Server | Handles inference and RL training loop, manages LoRA checkpoints |
| MCP Server | Exposes the toolset, queried by agent during each task |
| Scenario Engine | Auto-generates synthetic diverse task prompts |
| RULER Scorer | Relative reward assignment for each group of trajectories |
pip install openpipe-artThe combination of MCP- RL and ART abstracts away years of RL automation design, letting you convert any LLM into a tool-using, self-improving agent, domain-agnostic and without annotated training data. Whether your environment is public APIs or bespoke enterprise servers, the agent learns on-the-job and achieves scalable, robust performance.
For further details, practical example notebooks, and up-to-date benchmarks, visit the ART repository and its [MCP- RL-specific training examples]
The post Technical Deep Dive: Automating LLM Agent Mastery for Any MCP Server with MCP- RL and ART appeared first on MarkTechPost.
MarkTechPost
August 9, 2025
Reading through Cloudflare’s detailed exposé and the extensive media coverage, the controversy surrounding Perplexity AI’s web scraping practices is deeper — and more polarizing — than it first appears. Cloudflare accuses Perplexity of systematically ignoring website blocks and masking its identity to scrape data from sites that have opted out, raising serious questions about ethics, transparency, and the future of the Internet’s business model.
Cloudflare’s report and independent investigations show that Perplexity, an AI startup, allegedly crawls and scrapes content from websites that explicitly signal (through robots.txt and direct blocks) that AI tools are not welcome. The technical evidence includes changing user agents to impersonate browsers like Google Chrome on macOS and rotating Autonomous System Numbers (ASNs) — sophisticated tactics intended to evade detection and blocks. Cloudflare claims it detected this covert scraping across tens of thousands of domains, generating millions of requests daily, and fingerprinted the crawler using machine learning and other network signals.
For decades, websites have used robots.txt as a “gentleman’s agreement” to tell bots what’s allowed. While illegal in very few jurisdictions, the norm among leaders like OpenAI and Anthropic is to respect these signals. Perplexity’s alleged approach undermines this unwritten contract, suggesting a willingness to bypass website owners’ wishes in pursuit of training data.
This issue exploded just as Cloudflare launched its new “Pay Per Crawl” marketplace, which lets publishers charge for AI bot access and blocks most crawlers by default. Major outlets — The Atlantic, BuzzFeed, Time Inc., and O’Reilly — have signed up, and over 2.5million websites now disallow AI training outright.
Perplexity’s spokesperson dismissed Cloudflare’s blog post as little more than a “sales pitch,” claiming the screenshots “show that no content was accessed” and denying ownership of the bot in question. Perplexity later argued that much of what Cloudflare saw was user-driven fetching (an AI agent acting on direct user requests) rather than automated crawling — a key distinction in ongoing debates about what “scraping” really means. They also mentioned that similar incidents had happened before, notably accusations of plagiarism from outlets like Wired, and the company has struggled to define its own standards for content use.
Whether Perplexity is being singled out unfairly or genuinely violating web norms, this is a watershed moment. The era of “free data” for AI is ending. Ethics, economics, and new gatekeeping platforms like Cloudflare are pushing a shift toward paid data, greater accountability, and sustainable content partnerships. Unless AI companies adapt, they’ll face locked gates and a fragmented, paywalled Internet — and that ultimately reshapes the foundation of the digital world.
Check out the Technical details. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks.
The post Cloudflare vs Perplexity: The Battle Over AI Web Scraping Heats Up appeared first on MarkTechPost.
MarkTechPost
August 9, 2025
In this tutorial, we’ll explore the new capabilities introduced in OpenAI’s latest model, GPT-5. The update brings several powerful features, including the Verbosity parameter, Free-form Function Calling, Context-Free Grammar (CFG), and Minimal Reasoning. We’ll look at what they do and how to use them in practice. Check out the Full Codes here.
!pip install pandas openaiTo get an OpenAI API key, visit https://platform.openai.com/settings/organization/api-keys and generate a new key. If you’re a new user, you may need to add billing details and make a minimum payment of $5 to activate API access. Check out the Full Codes here.
import os
from getpass import getpass
os.environ['OPENAI_API_KEY'] = getpass('Enter OpenAI API Key: ')The Verbosity parameter lets you control how detailed the model’s replies are without changing your prompt.
from openai import OpenAI
import pandas as pd
from IPython.display import display
client = OpenAI()
question = "Write a poem about a detective and his first solve"
data = []
for verbosity in ["low", "medium", "high"]:
response = client.responses.create(
model="gpt-5-mini",
input=question,
text={"verbosity": verbosity}
)
# Extract text
output_text = ""
for item in response.output:
if hasattr(item, "content"):
for content in item.content:
if hasattr(content, "text"):
output_text += content.text
usage = response.usage
data.append({
"Verbosity": verbosity,
"Sample Output": output_text,
"Output Tokens": usage.output_tokens
})# Create DataFrame
df = pd.DataFrame(data)
# Display nicely with centered headers
pd.set_option('display.max_colwidth', None)
styled_df = df.style.set_table_styles(
[
{'selector': 'th', 'props': [('text-align', 'center')]}, # Center column headers
{'selector': 'td', 'props': [('text-align', 'left')]} # Left-align table cells
]
)
display(styled_df)The output tokens scale roughly linearly with verbosity: low (731) → medium (1017) → high (1263).
Free-form function calling lets GPT-5 send raw text payloads—like Python scripts, SQL queries, or shell commands—directly to your tool, without the JSON formatting used in GPT-4. Check out the Full Codes here.
This makes it easier to connect GPT-5 to external runtimes such as:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5-mini",
input="Please use the code_exec tool to calculate the cube of the number of vowels in the word 'pineapple'",
text={"format": {"type": "text"}},
tools=[
{
"type": "custom",
"name": "code_exec",
"description": "Executes arbitrary python code",
}
]
)print(response.output[1].input)
This output shows GPT-5 generating raw Python code that counts the vowels in the word pineapple, calculates the cube of that count, and prints both values. Instead of returning a structured JSON object (like GPT-4 typically would for tool calls), GPT-5 delivers plain executable code. This makes it possible to feed the result directly into a Python runtime without extra parsing.
A Context-Free Grammar (CFG) is a set of production rules that define valid strings in a language. Each rule rewrites a non-terminal symbol into terminals and/or other non-terminals, without depending on the surrounding context.
CFGs are useful when you want to strictly constrain the model’s output so it always follows the syntax of a programming language, data format, or other structured text — for example, ensuring generated SQL, JSON, or code is always syntactically correct.
For comparison, we’ll run the same script using GPT-4 and GPT-5 with an identical CFG to see how both models adhere to the grammar rules and how their outputs differ in accuracy and speed. Check out the Full Codes here.
from openai import OpenAI
import re
client = OpenAI()
email_regex = r"^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+.[A-Za-z]{2,}$"
prompt = "Give me a valid email address for John Doe. It can be a dummy email"
# No grammar constraints -- model might give prose or invalid format
response = client.responses.create(
model="gpt-4o", # or earlier
input=prompt
)
output = response.output_text.strip()
print("GPT Output:", output)
print("Valid?", bool(re.match(email_regex, output)))
from openai import OpenAI
client = OpenAI()
email_regex = r"^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+.[A-Za-z]{2,}$"
prompt = "Give me a valid email address for John Doe. It can be a dummy email"
response = client.responses.create(
model="gpt-5", # grammar-constrained model
input=prompt,
text={"format": {"type": "text"}},
tools=[
{
"type": "custom",
"name": "email_grammar",
"description": "Outputs a valid email address.",
"format": {
"type": "grammar",
"syntax": "regex",
"definition": email_regex
}
}
],
parallel_tool_calls=False
)
print("GPT-5 Output:", response.output[1].input)
This example shows how GPT-5 can adhere more closely to a specified format when using a Context-Free Grammar.
With the same grammar rules, GPT-4 produced extra text around the email address (“Sure, here’s a test email you can use for John Doe: johndoe@example.com”), which makes it invalid according to the strict format requirement.
GPT-5, however, output exactly john.doe@example.com, matching the grammar and passing validation. This demonstrates GPT-5’s improved ability to follow CFG constraints precisely. Check out the Full Codes here.
Minimal reasoning mode runs GPT-5 with very few or no reasoning tokens, reducing latency and delivering a faster time-to-first-token.
It’s ideal for deterministic, lightweight tasks such as:
Because the model skips most intermediate reasoning steps, responses are quick and concise. If not specified, the reasoning effort defaults to medium. Check out the Full Codes here.
import time
from openai import OpenAI
client = OpenAI()
prompt = "Classify the given number as odd or even. Return one word only."
start_time = time.time() # Start timer
response = client.responses.create(
model="gpt-5",
input=[
{ "role": "developer", "content": prompt },
{ "role": "user", "content": "57" }
],
reasoning={
"effort": "minimal" # Faster time-to-first-token
},
)
latency = time.time() - start_time # End timer
# Extract model's text output
output_text = ""
for item in response.output:
if hasattr(item, "content"):
for content in item.content:
if hasattr(content, "text"):
output_text += content.text
print("--------------------------------")
print("Output:", output_text)
print(f"Latency: {latency:.3f} seconds")Check out the Full Codes here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post A Developer’s Guide to OpenAI’s GPT-5 Model Capabilities appeared first on MarkTechPost.
MarkTechPost
 August 9, 2025
August 9, 2025Truth Search AI appears to rely heavily on conservative outlet Fox News to answer even the most basic questions.Feed: Artificial Intelligence Latest
 Discuss on Hacker News
Discuss on Hacker News  Join our ML Subreddit
Join our ML Subreddit  Sponsor us
Sponsor us 
