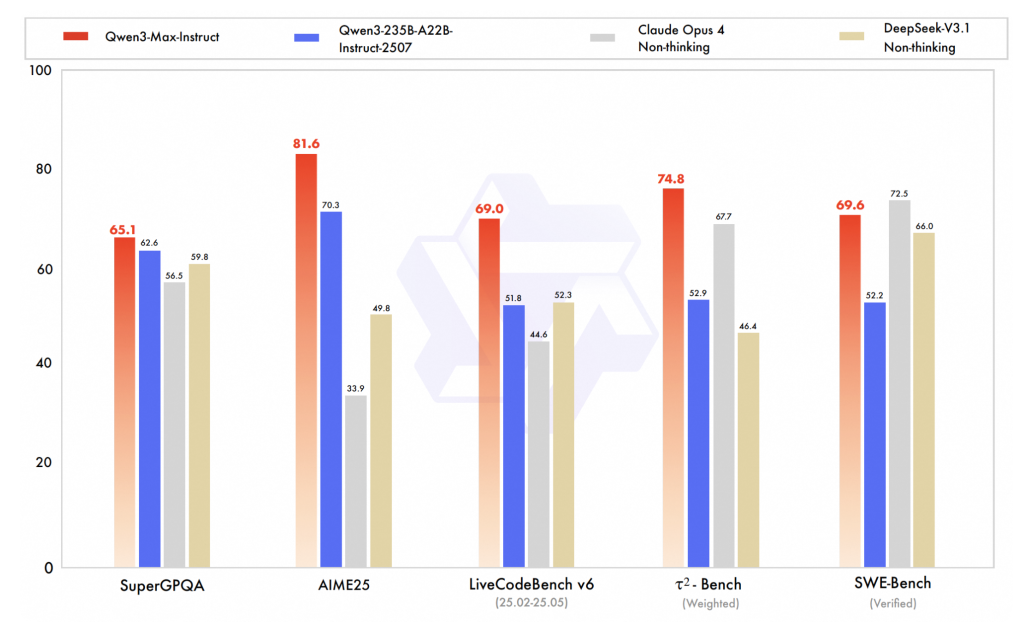
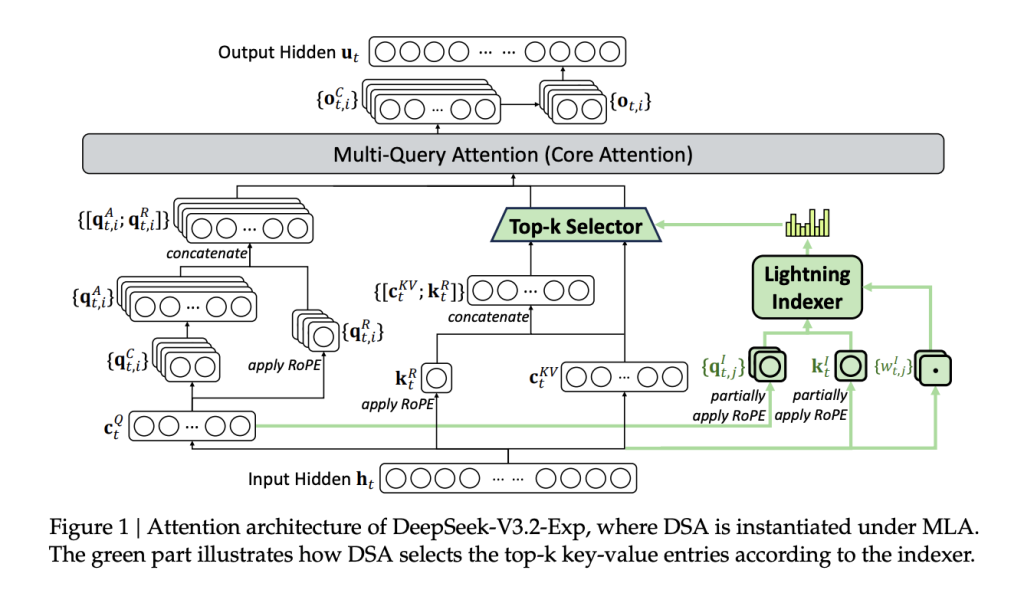
In this tutorial, we explore advanced computer vision techniques using TorchVision’s v2 transforms, modern augmentation strategies, and powerful training enhancements. We walk through the process of building an augmentation pipeline, applying MixUp and CutMix, designing a modern CNN with attention, and implementing a robust training loop. By running everything seamlessly in Google Colab, we position ourselves to understand and apply state-of-the-art practices in deep learning with clarity and efficiency. Check out the .
!pip install torch torchvision torchaudio --quiet
!pip install matplotlib pillow numpy --quiet
import torch
import torchvision
from torchvision import transforms as T
from torchvision.transforms import v2
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import requests
from io import BytesIO
print(f"PyTorch version: {torch.__version__}")
print(f"TorchVision version: {torchvision.__version__}")
We begin by installing the libraries and importing all the essential modules for our workflow. We set up PyTorch, TorchVision v2 transforms, and supporting tools like NumPy, PIL, and Matplotlib, so we are ready to build and test advanced computer vision pipelines. Check out the .
class AdvancedAugmentationPipeline:
def __init__(self, image_size=224, training=True):
self.image_size = image_size
self.training = training
base_transforms = [
v2.ToImage(),
v2.ToDtype(torch.uint8, scale=True),
]
if training:
self.transform = v2.Compose([
*base_transforms,
v2.Resize((image_size + 32, image_size + 32)),
v2.RandomResizedCrop(image_size, scale=(0.8, 1.0), ratio=(0.9, 1.1)),
v2.RandomHorizontalFlip(p=0.5),
v2.RandomRotation(degrees=15),
v2.ColorJitter(brights=0.4, contst=0.4, sation=0.4, hue=0.1),
v2.RandomGrayscale(p=0.1),
v2.GaussianBlur(kernel_size=3, sigma=(0.1, 2.0)),
v2.RandomPerspective(distortion_scale=0.1, p=0.3),
v2.RandomAffine(degrees=10, translate=(0.1, 0.1), scale=(0.9, 1.1)),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
else:
self.transform = v2.Compose([
*base_transforms,
v2.Resize((image_size, image_size)),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
def __call__(self, image):
return self.transform(image)
We define an advanced augmentation pipeline that adapts to both training and validation modes. We apply powerful TorchVision v2 transforms, such as cropping, flipping, color jittering, blurring, perspective, and affine transformations, during training, while keeping validation preprocessing simple with resizing and normalization. This way, we ensure that we enrich the training data for better generalization while maintaining consistent and stable evaluation. Check out the .
class AdvancedMixupCutmix:
def __init__(self, mixup_alpha=1.0, cutmix_alpha=1.0, prob=0.5):
self.mixup_alpha = mixup_alpha
self.cutmix_alpha = cutmix_alpha
self.prob = prob
def mixup(self, x, y):
batch_size = x.size(0)
lam = np.random.beta(self.mixup_alpha, self.mixup_alpha) if self.mixup_alpha > 0 else 1
index = torch.randperm(batch_size)
mixed_x = lam * x + (1 - lam) * x[index, :]
y_a, y_b = y, y[index]
return mixed_x, y_a, y_b, lam
def cutmix(self, x, y):
batch_size = x.size(0)
lam = np.random.beta(self.cutmix_alpha, self.cutmix_alpha) if self.cutmix_alpha > 0 else 1
index = torch.randperm(batch_size)
y_a, y_b = y, y[index]
bbx1, bby1, bbx2, bby2 = self._rand_bbox(x.size(), lam)
x[:, :, bbx1:bbx2, bby1:bby2] = x[index, :, bbx1:bbx2, bby1:bby2]
lam = 1 - ((bbx2 - bbx1) * (bby2 - bby1) / (x.size()[-1] * x.size()[-2]))
return x, y_a, y_b, lam
def _rand_bbox(self, size, lam):
W = size[2]
H = size[3]
cut_rat = np.sqrt(1. - lam)
cut_w = int(W * cut_rat)
cut_h = int(H * cut_rat)
cx = np.random.randint(W)
cy = np.random.randint(H)
bbx1 = np.clip(cx - cut_w // 2, 0, W)
bby1 = np.clip(cy - cut_h // 2, 0, H)
bbx2 = np.clip(cx + cut_w // 2, 0, W)
bby2 = np.clip(cy + cut_h // 2, 0, H)
return bbx1, bby1, bbx2, bby2
def __call__(self, x, y):
if np.random.random() > self.prob:
return x, y, y, 1.0
if np.random.random() < 0.5:
return self.mixup(x, y)
else:
return self.cutmix(x, y)
class ModernCNN(nn.Module):
def __init__(self, num_classes=10, dropout=0.3):
super(ModernCNN, self).__init__()
self.conv1 = self._conv_block(3, 64)
self.conv2 = self._conv_block(64, 128, downsample=True)
self.conv3 = self._conv_block(128, 256, downsample=True)
self.conv4 = self._conv_block(256, 512, downsample=True)
self.gap = nn.AdaptiveAvgPool2d(1)
self.attention = nn.Sequential(
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.Sigmoid()
)
self.classifier = nn.Sequential(
nn.Dropout(dropout),
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(dropout/2),
nn.Linear(256, num_classes)
)
def _conv_block(self, in_channels, out_channels, downsample=False):
stride = 2 if downsample else 1
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, stride=stride, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.gap(x)
x = torch.flatten(x, 1)
attention_weights = self.attention(x)
x = x * attention_weights
return self.classifier(x)
We strengthen our training with a unified MixUp/CutMix module, where we stochastically blend images or patch-swap regions and compute label interpolation with the exact pixel ratio. We pair this with a modern CNN that stacks progressive conv blocks, applies global average pooling, and uses a learned attention gate before a dropout-regularized classifier, so we improve generalization while keeping inference straightforward. Check out the .
class AdvancedTrainer:
def __init__(self, model, device='cuda' if torch.cuda.is_available() else 'cpu'):
self.model = model.to(device)
self.device = device
self.mixup_cutmix = AdvancedMixupCutmix()
self.optimizer = optim.AdamW(model.parameters(), lr=1e-3, weight_decay=1e-4)
self.scheduler = optim.lr_scheduler.OneCycleLR(
self.optimizer, max_lr=1e-2, epochs=10, steps_per_epoch=100
)
self.criterion = nn.CrossEntropyLoss()
def mixup_criterion(self, pred, y_a, y_b, lam):
return lam * self.criterion(pred, y_a) + (1 - lam) * self.criterion(pred, y_b)
def train_epoch(self, dataloader):
self.model.train()
total_loss = 0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(dataloader):
data, target = data.to(self.device), target.to(self.device)
data, target_a, target_b, lam = self.mixup_cutmix(data, target)
self.optimizer.zero_grad()
output = self.model(data)
if lam != 1.0:
loss = self.mixup_criterion(output, target_a, target_b, lam)
else:
loss = self.criterion(output, target)
loss.backward()
torch.nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=1.0)
self.optimizer.step()
self.scheduler.step()
total_loss += loss.item()
_, predicted = output.max(1)
total += target.size(0)
if lam != 1.0:
correct += (lam * predicted.eq(target_a).sum().item() +
(1 - lam) * predicted.eq(target_b).sum().item())
else:
correct += predicted.eq(target).sum().item()
return total_loss / len(dataloader), 100. * correct / total
We orchestrate training with AdamW, OneCycleLR, and dynamic MixUp/CutMix so we stabilize optimization and boost generalization. We compute an interpolated loss when mixing, clip gradients for safety, and step the scheduler each batch, so we track loss/accuracy per epoch in a single tight loop. Check out the .
def demo_advanced_techniques():
batch_size = 16
num_classes = 10
sample_data = torch.randn(batch_size, 3, 224, 224)
sample_labels = torch.randint(0, num_classes, (batch_size,))
transform_pipeline = AdvancedAugmentationPipeline(training=True)
model = ModernCNN(num_classes=num_classes)
trainer = AdvancedTrainer(model)
print(" Advanced Deep Learning Tutorial Demo")
print("=" * 50)
print("n1. Advanced Augmentation Pipeline:")
augmented = transform_pipeline(Image.fromarray((sample_data[0].permute(1,2,0).numpy() * 255).astype(np.uint8)))
print(f" Original shape: {sample_data[0].shape}")
print(f" Augmented shape: {augmented.shape}")
print(f" Applied transforms: Resize, Crop, Flip, ColorJitter, Blur, Perspective, etc.")
print("n2. MixUp/CutMix Augmentation:")
mixup_cutmix = AdvancedMixupCutmix()
mixed_data, target_a, target_b, lam = mixup_cutmix(sample_data, sample_labels)
print(f" Mixed batch shape: {mixed_data.shape}")
print(f" Lambda value: {lam:.3f}")
print(f" Technique: {'MixUp' if lam > 0.7 else 'CutMix'}")
print("n3. Modern CNN Architecture:")
model.eval()
with torch.no_grad():
output = model(sample_data)
print(f" Input shape: {sample_data.shape}")
print(f" Output shape: {output.shape}")
print(f" Features: Residual blocks, Attention, Global Average Pooling")
print(f" Parameters: {sum(p.numel() for p in model.parameters()):,}")
print("n4. Advanced Training Simulation:")
dummy_loader = [(sample_data, sample_labels)]
loss, acc = trainer.train_epoch(dummy_loader)
print(f" Training loss: {loss:.4f}")
print(f" Training accuracy: {acc:.2f}%")
print(f" Learning rate: {trainer.scheduler.get_last_lr()[0]:.6f}")
print("n
Advanced Deep Learning Tutorial Demo")
print("=" * 50)
print("n1. Advanced Augmentation Pipeline:")
augmented = transform_pipeline(Image.fromarray((sample_data[0].permute(1,2,0).numpy() * 255).astype(np.uint8)))
print(f" Original shape: {sample_data[0].shape}")
print(f" Augmented shape: {augmented.shape}")
print(f" Applied transforms: Resize, Crop, Flip, ColorJitter, Blur, Perspective, etc.")
print("n2. MixUp/CutMix Augmentation:")
mixup_cutmix = AdvancedMixupCutmix()
mixed_data, target_a, target_b, lam = mixup_cutmix(sample_data, sample_labels)
print(f" Mixed batch shape: {mixed_data.shape}")
print(f" Lambda value: {lam:.3f}")
print(f" Technique: {'MixUp' if lam > 0.7 else 'CutMix'}")
print("n3. Modern CNN Architecture:")
model.eval()
with torch.no_grad():
output = model(sample_data)
print(f" Input shape: {sample_data.shape}")
print(f" Output shape: {output.shape}")
print(f" Features: Residual blocks, Attention, Global Average Pooling")
print(f" Parameters: {sum(p.numel() for p in model.parameters()):,}")
print("n4. Advanced Training Simulation:")
dummy_loader = [(sample_data, sample_labels)]
loss, acc = trainer.train_epoch(dummy_loader)
print(f" Training loss: {loss:.4f}")
print(f" Training accuracy: {acc:.2f}%")
print(f" Learning rate: {trainer.scheduler.get_last_lr()[0]:.6f}")
print("n Tutorial completed successfully!")
print("This code demonstrates state-of-the-art techniques in deep learning:")
print("• Advanced data augmentation with TorchVision v2")
print("• MixUp and CutMix for better generalization")
print("• Modern CNN architecture with attention")
print("• Advanced training loop with OneCycleLR")
print("• Gradient clipping and weight decay")
if __name__ == "__main__":
demo_advanced_techniques()
Tutorial completed successfully!")
print("This code demonstrates state-of-the-art techniques in deep learning:")
print("• Advanced data augmentation with TorchVision v2")
print("• MixUp and CutMix for better generalization")
print("• Modern CNN architecture with attention")
print("• Advanced training loop with OneCycleLR")
print("• Gradient clipping and weight decay")
if __name__ == "__main__":
demo_advanced_techniques()
We run a compact end-to-end demo where we visualize our augmentation pipeline, apply MixUp/CutMix, and double-check the ModernCNN with a forward pass. We then simulate one training epoch on dummy data to verify loss, accuracy, and learning-rate scheduling, so we confirm the full stack works before scaling to a real dataset.
In conclusion, we have successfully developed and tested a comprehensive workflow that integrates advanced augmentations, innovative CNN design, and modern training strategies. By experimenting with TorchVision v2, MixUp, CutMix, attention mechanisms, and OneCycleLR, we not only strengthen model performance but also deepen our understanding of cutting-edge techniques.
Check out the . Feel free to check out our . Also, feel free to follow us on and don’t forget to join our and Subscribe to .
The post appeared first on .

 September 25, 2025
September 25, 2025

 Enter your Gemini API key (hidden): ")
import google.generativeai as genai
genai.configure(api_key=os.environ["GOOGLE_API_KEY"])
LLM = genai.GenerativeModel("gemini-1.5-flash")
def ask_llm(prompt, sys=None):
p = prompt if sys is None else f"System:n{sys}nnUser:n{prompt}"
r = LLM.generate_content(p)
return (getattr(r, "text", "") or "").strip()
from sklearn.datasets import load_diabetes
raw = load_diabetes(as_frame=True)
df = raw.frame.rename(columns={"target":"disease_progression"})
print("Shape:", df.shape); display(df.head())
from sklearn.model_selection import train_test_split, KFold, cross_val_score
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, QuantileTransformer
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.pipeline import Pipeline
X = df.drop(columns=["disease_progression"]); y = df["disease_progression"]
num_cols = X.columns.tolist()
pre = ColumnTransformer(
[("scale", StandardScaler(), num_cols),
("rank", QuantileTransformer(n_quantiles=min(200, len(X)), output_distribution="normal"), num_cols)],
remainder="drop", verbose_feature_names_out=False)
model = HistGradientBoostingRegressor(max_depth=3, learning_rate=0.07,
l2_regularization=0.0, max_iter=500,
early_stopping=True, validation_fraction=0.15)
pipe = Pipeline([("prep", pre), ("hgbt", model)])
Xtr, Xte, ytr, yte = train_test_split(X, y, test_size=0.20, random_state=42)
cv = KFold(n_splits=5, shuffle=True, random_state=42)
cv_mse = -cross_val_score(pipe, Xtr, ytr, scoring="neg_mean_squared_error", cv=cv).mean()
cv_rmse = float(cv_mse ** 0.5)
pipe.fit(Xtr, ytr)
Enter your Gemini API key (hidden): ")
import google.generativeai as genai
genai.configure(api_key=os.environ["GOOGLE_API_KEY"])
LLM = genai.GenerativeModel("gemini-1.5-flash")
def ask_llm(prompt, sys=None):
p = prompt if sys is None else f"System:n{sys}nnUser:n{prompt}"
r = LLM.generate_content(p)
return (getattr(r, "text", "") or "").strip()
from sklearn.datasets import load_diabetes
raw = load_diabetes(as_frame=True)
df = raw.frame.rename(columns={"target":"disease_progression"})
print("Shape:", df.shape); display(df.head())
from sklearn.model_selection import train_test_split, KFold, cross_val_score
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, QuantileTransformer
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.pipeline import Pipeline
X = df.drop(columns=["disease_progression"]); y = df["disease_progression"]
num_cols = X.columns.tolist()
pre = ColumnTransformer(
[("scale", StandardScaler(), num_cols),
("rank", QuantileTransformer(n_quantiles=min(200, len(X)), output_distribution="normal"), num_cols)],
remainder="drop", verbose_feature_names_out=False)
model = HistGradientBoostingRegressor(max_depth=3, learning_rate=0.07,
l2_regularization=0.0, max_iter=500,
early_stopping=True, validation_fraction=0.15)
pipe = Pipeline([("prep", pre), ("hgbt", model)])
Xtr, Xte, ytr, yte = train_test_split(X, y, test_size=0.20, random_state=42)
cv = KFold(n_splits=5, shuffle=True, random_state=42)
cv_mse = -cross_val_score(pipe, Xtr, ytr, scoring="neg_mean_squared_error", cv=cv).mean()
cv_rmse = float(cv_mse ** 0.5)
pipe.fit(Xtr, ytr) Gemini Executive Briefn" + "-"*80 + f"n{summary}n")
Gemini Executive Briefn" + "-"*80 + f"n{summary}n") Gemini Risk & Robustness Reviewn" + "-"*80 + f"n{critique}n")
def what_if(pipe, Xref: pd.DataFrame, feat: str, delta: float = 0.05):
x0 = Xref.median(numeric_only=True).to_dict()
x1, x2 = x0.copy(), x0.copy()
if feat not in x1: return np.nan
x2[feat] = x1[feat] + delta
X1 = pd.DataFrame([x1], columns=X.columns)
X2 = pd.DataFrame([x2], columns=X.columns)
return float(pipe.predict(X2)[0] - pipe.predict(X1)[0])
for f in top_feats:
print(f"Estimated Δtarget if {f} increases by +0.05 ≈ {what_if(pipe, Xte, f, 0.05):.2f}")
print("n
Gemini Risk & Robustness Reviewn" + "-"*80 + f"n{critique}n")
def what_if(pipe, Xref: pd.DataFrame, feat: str, delta: float = 0.05):
x0 = Xref.median(numeric_only=True).to_dict()
x1, x2 = x0.copy(), x0.copy()
if feat not in x1: return np.nan
x2[feat] = x1[feat] + delta
X1 = pd.DataFrame([x1], columns=X.columns)
X2 = pd.DataFrame([x2], columns=X.columns)
return float(pipe.predict(X2)[0] - pipe.predict(X1)[0])
for f in top_feats:
print(f"Estimated Δtarget if {f} increases by +0.05 ≈ {what_if(pipe, Xte, f, 0.05):.2f}")
print("n

 image alignment (CLIP-family or VLM retrievers) and, in practice, dual-index: cheap text recall for coverage + vision rerank for precision. ColPali’s late-interaction (MaxSim-style) is a strong default for page images.
image alignment (CLIP-family or VLM retrievers) and, in practice, dual-index: cheap text recall for coverage + vision rerank for precision. ColPali’s late-interaction (MaxSim-style) is a strong default for page images.