 September 19, 2025
September 19, 2025 September 19, 2025
September 19, 2025Building AI agents is 5% AI and 100% software engineering
Production-grade agents live or die on data plumbing, controls, and observability—not on model choice. The doc-to-chat pipeline below maps the concrete layers and why they matter.
What is a “doc-to-chat” pipeline?
A doc-to-chat pipeline ingests enterprise documents, standardizes them, enforces governance, indexes embeddings alongside relational features, and serves retrieval + generation behind authenticated APIs with human-in-the-loop (HITL) checkpoints. It’s the reference architecture for agentic Q&A, copilots, and workflow automation where answers must respect permissions and be audit-ready. Production implementations are variations of RAG (retrieval-augmented generation) hardened with LLM guardrails, governance, and OpenTelemetry-backed tracing.
How do you integrate cleanly with the existing stack?
Use standard service boundaries (REST/JSON, gRPC) over a storage layer your org already trusts. For tables, Iceberg gives ACID, schema evolution, partition evolution, and snapshots—critical for reproducible retrieval and backfills. For vectors, use a system that coexists with SQL filters: pgvector collocates embeddings with business keys and ACL tags in PostgreSQL; dedicated engines like Milvus handle high-QPS ANN with disaggregated storage/compute. In practice, many teams run both: SQL+pgvector for transactional joins and Milvus for heavy retrieval.
Key properties
- Iceberg tables: ACID, hidden partitioning, snapshot isolation; vendor support across warehouses.
- pgvector: SQL + vector similarity in one query plan for precise joins and policy enforcement.
- Milvus: layered, horizontally scalable architecture for large-scale similarity search.
How do agents, humans, and workflows coordinate on one “knowledge fabric”?
Production agents require explicit coordination points where humans approve, correct, or escalate. AWS A2I provides managed HITL loops (private workforces, flow definitions) and is a concrete blueprint for gating low-confidence outputs. Frameworks like LangGraph model these human checkpoints inside agent graphs so approvals are first-class steps in the DAG, not ad hoc callbacks. Use them to gate actions like publishing summaries, filing tickets, or committing code.
Pattern: LLM → confidence/guardrail checks → HITL gate → side-effects. Persist every artifact (prompt, retrieval set, decision) for auditability and future re-runs.
How is reliability enforced before anything reaches the model?
Treat reliability as layered defenses:
- Language + content guardrails: Pre-validate inputs/outputs for safety and policy. Options span managed (Bedrock Guardrails) and OSS (NeMo Guardrails, Guardrails AI; Llama Guard). Independent comparisons and a position paper catalog the trade-offs.
- PII detection/redaction: Run analyzers on both source docs and model I/O. Microsoft Presidio offers recognizers and masking, with explicit caveats to combine with additional controls.
- Access control and lineage: Enforce row-/column-level ACLs and audit across catalogs (Unity Catalog) so retrieval respects permissions; unify lineage and access policies across workspaces.
- Retrieval quality gates: Evaluate RAG with reference-free metrics (faithfulness, context precision/recall) using Ragas/related tooling; block or down-rank poor contexts.
How do you scale indexing and retrieval under real traffic?
Two axes matter: ingest throughput and query concurrency.
- Ingest: Normalize at the lakehouse edge; write to Iceberg for versioned snapshots, then embed asynchronously. This enables deterministic rebuilds and point-in-time re-indexing.
- Vector serving: Milvus’s shared-storage, disaggregated compute architecture supports horizontal scaling with independent failure domains; use HNSW/IVF/Flat hybrids and replica sets to balance recall/latency.
- SQL + vector: Keep business joins server-side (pgvector), e.g.,
WHERE tenant_id = ? AND acl_tag @> ... ORDER BY embedding <-> :q LIMIT k. This avoids N+1 trips and respects policies. - Chunking/embedding strategy: Tune chunk size/overlap and semantic boundaries; bad chunking is the silent killer of recall.
For structured+unstructured fusion, prefer hybrid retrieval (BM25 + ANN + reranker) and store structured features next to vectors to support filters and re-ranking features at query time.
How do you monitor beyond logs?
You need traces, metrics, and evaluations stitched together:
- Distributed tracing: Emit OpenTelemetry spans across ingestion, retrieval, model calls, and tools; LangSmith natively ingests OTEL traces and interoperates with external APMs (Jaeger, Datadog, Elastic). This gives end-to-end timing, prompts, contexts, and costs per request.
- LLM observability platforms: Compare options (LangSmith, Arize Phoenix, LangFuse, Datadog) by tracing, evals, cost tracking, and enterprise readiness. Independent roundups and matrixes are available.
- Continuous evaluation: Schedule RAG evals (Ragas/DeepEval/MLflow) on canary sets and live traffic replays; track faithfulness and grounding drift over time.
Add schema profiling/mapping on ingestion to keep observability attached to data shape changes (e.g., new templates, table evolution) and to explain retrieval regressions when upstream sources shift.
Example: doc-to-chat reference flow (signals and gates)
- Ingest: connectors → text extraction → normalization → Iceberg write (ACID, snapshots).
- Govern: PII scan (Presidio) → redact/mask → catalog registration with ACL policies.
- Index: embedding jobs → pgvector (policy-aware joins) and Milvus (high-QPS ANN).
- Serve: REST/gRPC → hybrid retrieval → guardrails → LLM → tool use.
- HITL: low-confidence paths route to A2I/LangGraph approval steps.
- Observe: OTEL traces to LangSmith/APM + scheduled RAG evaluations.
Why “5% AI, 100% software engineering” is accurate in practice?
Most outages and trust failures in agent systems are not model regressions; they’re data quality, permissioning, retrieval decay, or missing telemetry. The controls above—ACID tables, ACL catalogs, PII guardrails, hybrid retrieval, OTEL traces, and human gates—determine whether the same base model is safe, fast, and credibly correct for your users. Invest in these first; swap models later if needed.
References:
The post appeared first on .
 September 19, 2025
September 19, 2025MIT’s LEGO: A Compiler for AI Chips that Auto-Generates Fast, Efficient Spatial Accelerators
Table of contents
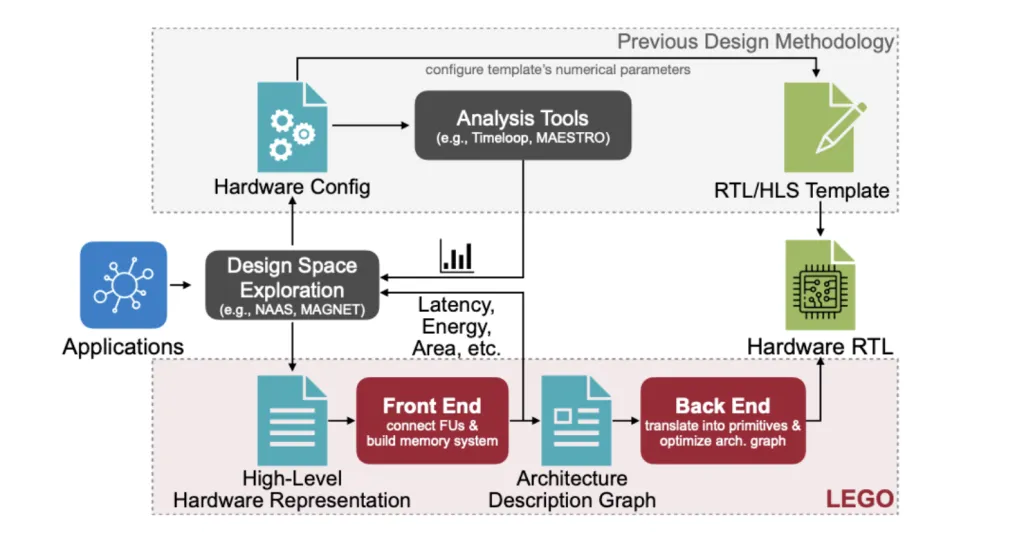
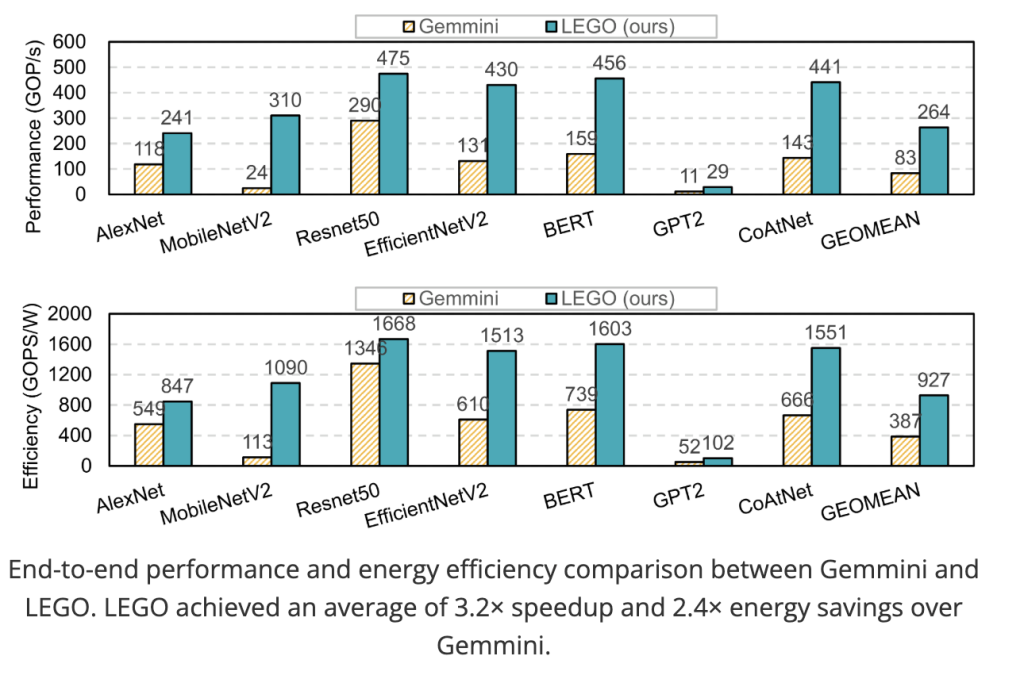
MIT researchers (Han Lab) introduced LEGO, a compiler-like framework that takes tensor workloads (e.g., GEMM, Conv2D, attention, MTTKRP) and automatically generates synthesizable RTL for spatial accelerators—no handwritten templates. LEGO’s front end expresses workloads and dataflows in a relation-centric affine representation, builds FU (functional unit) interconnects and on-chip memory layouts for reuse, and supports fusing multiple spatial dataflows in a single design. The back end lowers to a primitive-level graph and uses linear programming and graph transforms to insert pipeline registers, rewire broadcasts, extract reduction trees, and shrink area and power. Evaluated across foundation models and classic CNNs/Transformers, LEGO’s generated hardware shows 3.2× speedup and 2.4× energy efficiency over Gemmini under matched resources.
Hardware Generation without Templates
Existing flows either: (1) analyze dataflows without generating hardware, or (2) generate RTL from hand-tuned templates with fixed topologies. These approaches restrict the architecture space and struggle with modern workloads that need to switch dataflows dynamically across layers/ops (e.g., conv vs. depthwise vs. attention). LEGO directly targets any dataflow and combinations, generating both architecture and RTL from a high-level description rather than configuring a few numeric parameters in a template.
Input IR: Affine, Relation-Centric Semantics (Deconstruct)
LEGO models tensor programs as loop nests with three index classes: temporal (for-loops), spatial (par-for FUs), and computation (pre-tiling iteration domain). Two affine relations drive the compiler:
- Data mapping fI→Df_{I→D}: maps computation indices to tensor indices.
- Dataflow mapping fTS→If_{TS→I}: maps temporal/spatial indices to computation indices.
This affine-only representation eliminates modulo/division in the core analysis, making reuse detection and address generation a linear-algebra problem. LEGO also decouples control flow from dataflow (a vector c encodes control signal propagation/delay), enabling shared control across FUs and substantially reducing control logic overhead.
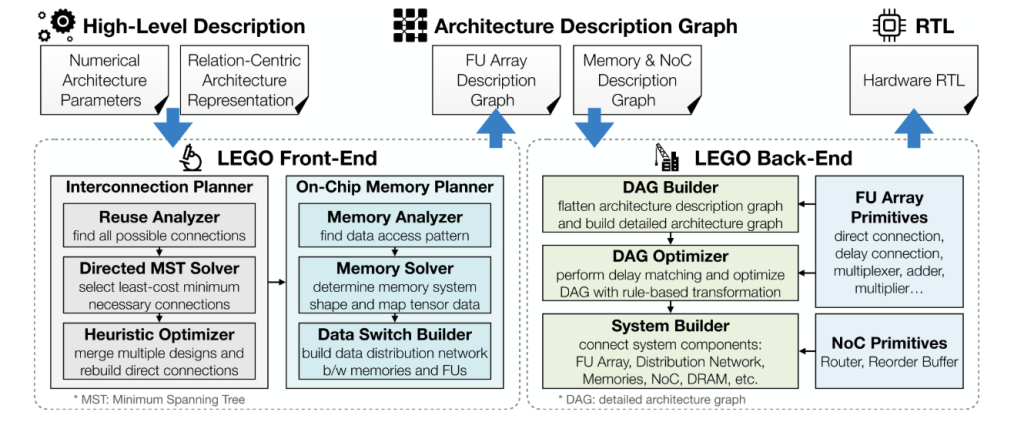
Front End: FU Graph + Memory Co-Design (Architect)
The main objectives is to maximize reuse and on-chip bandwidth while minimizing interconnect/mux overhead.
- Interconnection synthesis. LEGO formulates reuse as solving linear systems over the affine relations to discover direct and delay (FIFO) connections between FUs. It then computes minimum-spanning arborescences (Chu-Liu/Edmonds) to keep only necessary edges (cost = FIFO depth). A BFS-based heuristic rewrites direct interconnects when multiple dataflows must co-exist, prioritizing chain reuse and nodes already fed by delay connections to cut muxes and data nodes.
- Banked memory synthesis. Given the set of FUs that must read/write a tensor in the same cycle, LEGO computes bank counts per tensor dimension from the maximum index deltas (optionally dividing by GCD to reduce banks). It then instantiates data-distribution switches to route between banks and FUs, leaving FU-to-FU reuse to the interconnect.
- Dataflow fusion. Interconnects for different spatial dataflows are combined into a single FU-level Architecture Description Graph (ADG); careful planning avoids naïve mux-heavy merges and yields up to ~20% energy gains compared to naïve fusion.
Back End: Compile & Optimize to RTL (Compile & Optimize)
The ADG is lowered to a Detailed Architecture Graph (DAG) of primitives (FIFOs, muxes, adders, address generators). LEGO applies several LP/graph passes:
- Delay matching via LP. A linear program chooses output delays DvD_v to minimize inserted pipeline registers ∑(Dv−Du−Lv)⋅bitwidthsum (D_v-D_u-L_v)cdot text{bitwidth} across edges—meeting timing alignment with minimal storage.
- Broadcast pin rewiring. A two-stage optimization (virtual cost shaping + MST-based rewiring among destinations) converts expensive broadcasts into forward chains, enabling register sharing and lower latency; a final LP re-balances delays.
- Reduction tree extraction + pin reuse. Sequential adder chains become balanced trees; a 0-1 ILP remaps reducer inputs across dataflows so fewer physical pins are required (mux instead of add). This reduces both logic depth and register count.
These passes focus on the datapath, which dominates resources (e.g., FU-array registers ≈ 40% area, 60% power), and produce ~35% area savings versus naïve generation.
Outcome
Setup. LEGO is implemented in C++ with HiGHS as the LP solver and emits SpinalHDL→Verilog. Evaluation covers tensor kernels and end-to-end models (AlexNet, MobileNetV2, ResNet-50, EfficientNetV2, BERT, GPT-2, CoAtNet, DDPM, Stable Diffusion, LLaMA-7B). A single LEGO-MNICOC accelerator instance is used across models; a mapper picks per-layer tiling/dataflow. Gemmini is the main baseline under matched resources (256 MACs, 256 KB on-chip buffer, 128-bit bus @ 16 GB/s).
End-to-end speed/efficiency. LEGO achieves 3.2× speedup and 2.4× energy efficiency on average vs. Gemmini. Gains stem from: (i) a fast, accurate performance model guiding mapping; (ii) dynamic spatial dataflow switching enabled by generated interconnects (e.g., depthwise conv layers choose OH–OW–IC–OC). Both designs are bandwidth-bound on GPT-2.
Resource breakdown. Example SoC-style configuration shows FU array and NoC dominate area/power, with PPUs contributing ~2–5%. This supports the decision to aggressively optimize datapaths and control reuse.
Generative models. On a larger 1024-FU configuration, LEGO sustains >80% utilization for DDPM/Stable Diffusion; LLaMA-7B remains bandwidth-limited (expected for low operational intensity).
Importance for each segment
- For researchers: LEGO provides a mathematically grounded path from loop-nest specifications to spatial hardware with provable LP-based optimizations. It abstracts away low-level RTL and exposes meaningful levers (tiling, spatialization, reuse patterns) for systematic exploration.
- For practitioners: It is effectively hardware-as-code. You can target arbitrary dataflows and fuse them in one accelerator, letting a compiler derive interconnects, buffers, and controllers while shrinking mux/FIFO overheads. This improves energy and supports multi-op pipelines without manual template redesign.
- For product leaders: By lowering the barrier to custom silicon, LEGO enables task-tuned, power-efficient edge accelerators (wearables, IoT) that keep pace with fast-moving AI stacks—the silicon adapts to the model, not the other way around. End-to-end results against a state-of-the-art generator (Gemmini) quantify the upside.
How the “Compiler for AI Chips” Works—Step-by-Step?
- Deconstruct (Affine IR). Write the tensor op as loop nests; supply affine f_{I→D} (data mapping), f_{TS→I} (dataflow), and control flow vector c. This specifies what to compute and how it is spatialized, without templates.
- Architect (Graph Synthesis). Solve reuse equations → FU interconnects (direct/delay) → MST/heuristics for minimal edges and fused dataflows; compute banked memory and distribution switches to satisfy concurrent accesses without conflicts.
- Compile & Optimize (LP + Graph Transforms). Lower to a primitive DAG; run delay-matching LP, broadcast rewiring (MST), reduction-tree extraction, and pin-reuse ILP; perform bit-width inference and optional power gating. These passes jointly deliver ~35% area and ~28% energy savings vs. naïve codegen.
Where It Lands in the Ecosystem?
Compared with analysis tools (Timeloop/MAESTRO) and template-bound generators (Gemmini, DNA, MAGNET), LEGO is template-free, supports any dataflow and their combinations, and emits synthesizable RTL. Results show comparable or better area/power versus expert handwritten accelerators under similar dataflows and technologies, while offering one-architecture-for-many-models deployment.
Summary
LEGO operationalizes hardware generation as compilation for tensor programs: an affine front end for reuse-aware interconnect/memory synthesis and an LP-powered back end for datapath minimization. The framework’s measured 3.2× performance and 2.4× energy gains over a leading open generator, plus ~35% area reductions from back-end optimizations, position it as a practical path to application-specific AI accelerators at the edge and beyond.
Check out theand . Feel free to check out our . Also, feel free to follow us on and don’t forget to join our and Subscribe to .
The post appeared first on .
 September 18, 2025
September 18, 2025Move Aside, Chatbots: AI Humanoids Are Here
Today on Uncanny Valley, we talk about why the AI industry is investing in the development of humanoid robots, and what that means for us non-robots.
 September 18, 2025
September 18, 2025Jensen Huang Wants You to Know He’s Getting a Lot Out of the ‘Fantastic’ Nvidia-Intel Deal
Nvidia is investing $5 billion in Intel. The news comes after the US government took a roughly 10 percent equity stake in the struggling chipmaker.
 September 18, 2025
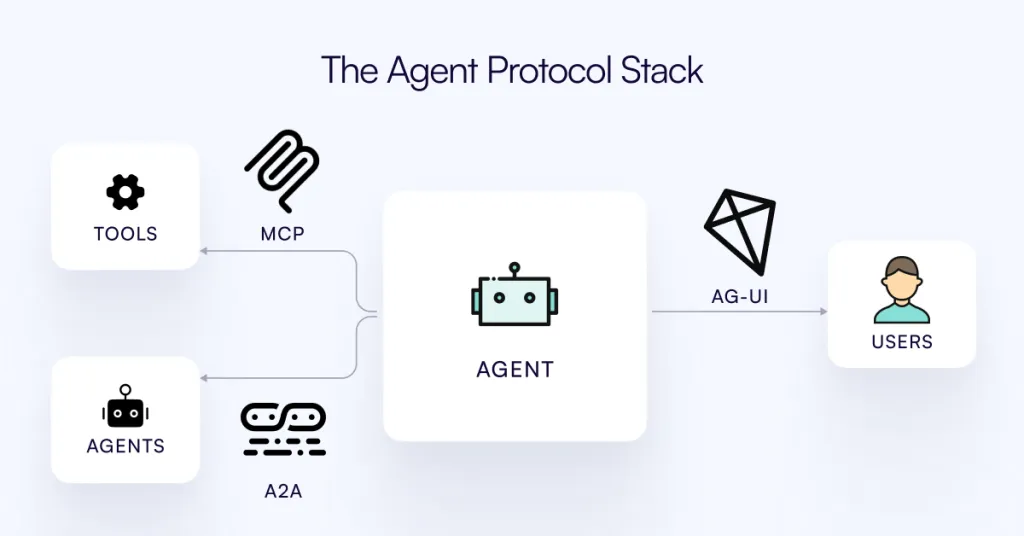
September 18, 2025Bringing AI Agents Into Any UI: The AG-UI Protocol for Real-Time, Structured Agent–Frontend Streams
AI agents are no longer just chatbots that spit out answers. They’re evolving into complex systems that can reason step by step, call APIs, update dashboards, and collaborate with humans in real time. But this raises a key question: how should agents talk to user interfaces?
Ad-hoc sockets and custom APIs can work for prototypes, but they don’t scale. Each project reinvents how to stream outputs, manage tool calls, or handle user corrections. That’s exactly the gap the aims to fill.
What AG-UI Brings to the Table
is a streaming event protocol designed for agent-to-UI communication. Instead of returning a single blob of text, agents emit a continuous sequence of JSON events:
- TEXT_MESSAGE_CONTENT for streaming responses token by token.
- TOOL_CALL_START / ARGS / END for external function calls.
- STATE_SNAPSHOT and STATE_DELTA for keeping UI state in sync with the backend.
- Lifecycle events (RUN_STARTED, RUN_FINISHED) to frame each interaction.
All of this flows over standard transports like HTTP SSE or WebSockets, so developers don’t have to build custom protocols. The frontend subscribes once and can render partial results, update charts, and even send user corrections mid-run.
This more than a messaging layer—it’s a contract between agents and UIs. Backend frameworks can evolve, UIs can change, but as long as they speak AG-UI, everything stays interoperable.
First-Party and Partner Integrations
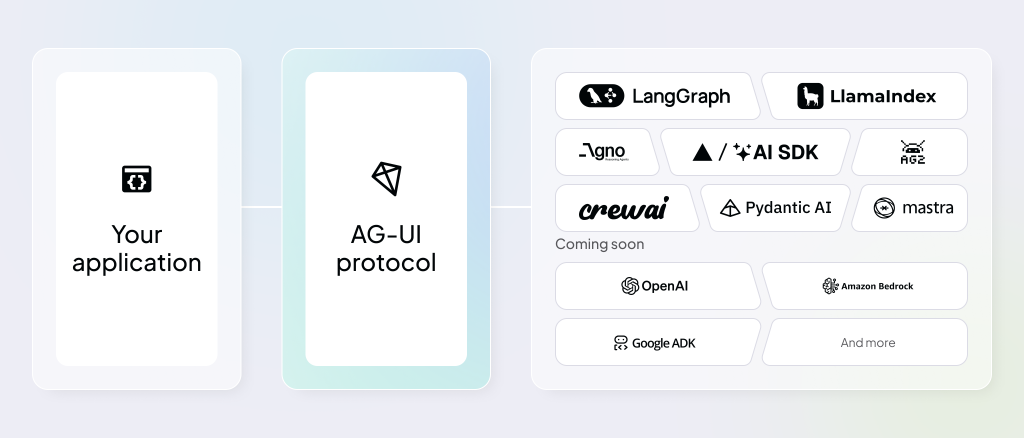
One reason is gaining traction is its breadth of supported integrations. Instead of leaving developers to wire everything manually, many agent frameworks already ship with AG-UI support.
- Mastra (TypeScript): Native support with strong typing, ideal for finance and data-driven copilots.
- LangGraph: AG-UI integrated into orchestration workflows so every node emits structured events.
- CrewAI: Multi-agent coordination exposed to UIs via AG-UI, letting users follow and guide “agent crews.”
- Agno: Full-stack multi-agent systems with -ready backends for dashboards and ops tools.
- LlamaIndex: Adds interactive data retrieval workflows with live evidence streaming to UIs.
- Pydantic AI: Python SDK with baked in, plus example apps like the AG-UI Dojo.
- CopilotKit: Frontend toolkit offering React components that subscribe to AG-UI streams.
Other integrations are in progress—like AWS Bedrock Agents, Google ADK, and Cloudflare Agents—which will make AG-UI accessible on major cloud platforms. Language SDKs are also expanding: Kotlin support is complete, while .NET, Go, Rust, Nim, and Java are in development.
Real-World Use Cases
Healthcare, finance, and analytics teams use to turn critical data streams into live, context-rich interfaces: clinicians see patient vitals update without page reloads, stock traders trigger a stock-analysis agent and watch results stream inline, and analysts view a LangGraph-powered dashboard that visualizes charting plans token by token as the agent reasons.
Beyond data display, simplifies workflow automation. Common patterns—data migration, research summarization, form-filling—are reduced to a single SSE event stream instead of custom sockets or polling loops. Because agents emit only STATE_DELTA patches, the UI refreshes just the pieces that changed, cutting bandwidth and eliminating jarring reloads. The same mechanism powers 24/7 customer-support bots that show typing indicators, tool-call progress, and final answers within one chat window, keeping users engaged throughout the interaction.
For developers, the protocol enables code-assistants and multi-agent applications with minimal glue code. Experiences that mirror GitHub Copilot—real-time suggestions streaming into editors—are built by simply listening to events. Frameworks such as LangGraph, CrewAI, and Mastra already emit the spec’s 16 event types, so teams can swap back-end agents while the front-end remains unchanged. This decoupling speeds prototyping across domains: tax software can show optimistic deduction estimates while validation runs in the background, and a CRM page can autofill client details as an agent returns structured data to a Svelte + Tailwind UI.
AG-UI Dojo
CopilotKit has also recently introduced , a “learning-first” suite of minimal, runnable demos that teach and validate AG-UI integrations end-to-end. Each demo includes a live preview, code, and linked docs, covering six primitives needed for production agent UIs: agentic chat (streaming + tool hooks), human-in-the-loop planning, agentic and tool-based generative UI, shared state, and predictive state updates for real-time collaboration. Teams can use the Dojo as a checklist to troubleshoot event ordering, payload shape, and UI–agent state sync before shipping, reducing integration ambiguity and debugging time.
You can play around with the , and more technical details on the
Roadmap and Community Contributions
The shows where AG-UI is heading and where developers can plug in:
- SDK maturity: Ongoing investment in TypeScript and Python SDKs, with expansion into more languages.
- Debugging and developer tools: Better error handling, observability, and lifecycle event clarity.
- Performance and transports: Work on large payload handling and alternative streaming transports beyond SSE/WS.
- Sample apps and playgrounds: The AG-UI Dojo demonstrates building blocks for UIs and is expanding with more patterns.
On the contribution side, the community has added integrations, improved SDKs, expanded documentation, and built demos. Pull requests across frameworks like Mastra, LangGraph, and Pydantic AI have come from both maintainers and external contributors. This collaborative model ensures is shaped by real developer needs, not just spec writers.
Summary
is emerging as the default interaction protocol for agent UIs. It standardizes the messy middle ground between agents and frontends, making applications more responsive, transparent, and maintainable.
With first-party integrations across popular frameworks, community contributions shaping the roadmap, and tooling like the AG-UI Dojo lowering the barrier to entry, the ecosystem is maturing fast.
Launch with a single command, choose your agent framework, and be prototyping in under five minutes.
npx create-ag-ui-app@latest
#then
<pick your agent framework>
#For details and patterns, see the quickstart blog: go.copilotkit.ai/ag-ui-cli-blog.FAQs
FAQ 1: What problem does AG-UI solve?
standardizes how agents communicate with user interfaces. Instead of ad-hoc APIs, it defines a clear event protocol for streaming text, tool calls, state updates, and lifecycle signals—making interactive UIs easier to build and maintain.
FAQ 2: Which frameworks already support AG-UI?
has first-party integrations with Mastra, LangGraph, CrewAI, Agno, LlamaIndex, and Pydantic AI. Partner integrations include CopilotKit on the frontend. Support for AWS Bedrock Agents, Google ADK, and additional languages like .NET, Go, and Rust is in progress.
FAQ 3: How does AG-UI differ from REST APIs?
REST works for single request–response tasks. is designed for interactive agents—it supports streaming output, incremental updates, tool usage, and user input during a run, which REST cannot handle natively.
FAQ 4: What transports does AG-UI use?
By default, runs over HTTP Server-Sent Events (SSE). It also supports WebSockets, and the roadmap includes exploration of alternative transports for high-performance or binary data use cases.
FAQ 5: How can developers get started with AG-UI?
You can install official SDKs (TypeScript, Python) or use supported frameworks like Mastra or Pydantic AI. The AG-UI Dojo provides working examples and UI building blocks to experiment with event streams.
Thanks to the team for the thought leadership/ Resources for this article. team has supported us in this content/article.
The post appeared first on .
 September 18, 2025
September 18, 2025China Turns Legacy Chips Into a Trade Weapon
As Washington pushes for a TikTok deal, Beijing is countering with probes into American chipmakers.
 September 18, 2025
September 18, 2025AI Psychosis Is Rarely Psychosis at All
A wave of AI users presenting in states of psychological distress gave birth to an unofficial diagnostic label. Experts say it’s neither accurate nor needed, but concede that it’s likely to stay.
 September 18, 2025
September 18, 2025H Company Releases Holo1.5: An Open-Weight Computer-Use VLMs Focused on GUI Localization and UI-VQA
H Company (A french AI startup) releases Holo1.5, a family of open foundation vision models purpose-built for computer-use (CU) agents that act on real user interfaces via screenshots and pointer/keyboard actions. The release includes 3B, 7B, and 72B checkpoints with a documented ~10% accuracy gain over Holo1 across sizes. The 7B model is Apache-2.0; the 3B and 72B inherit research-only constraints from their upstream bases. The series targets two core capabilities that matter for CU stacks: precise UI element localization (coordinate prediction) and UI visual question answering (UI-VQA) for state understanding.
Why does UI element localization matter?
Localization is how an agent converts an intent into a pixel-level action: “Open Spotify” → predict the clickable coordinates of the correct control on the current screen. Failures here cascade: a single off-by-one click can derail a multi-step workflow. Holo1.5 is trained and evaluated for high-resolution screens (up to 3840×2160) across desktop (macOS, Ubuntu, Windows), web, and mobile interfaces, improving robustness on dense professional UIs where iconography and small targets increase error rates.
How is Holo1.5 different from general VLMs?
General VLMs optimize for broad grounding and captioning; CU agents need reliable pointing plus interface comprehension. Holo1.5 aligns its data and objectives with these requirements: large-scale SFT on GUI tasks followed by GRPO-style reinforcement learning to tighten coordinate accuracy and decision reliability. The models are delivered as perception components to be embedded in planners/executors (e.g., Surfer-style agents), not as end-to-end agents.
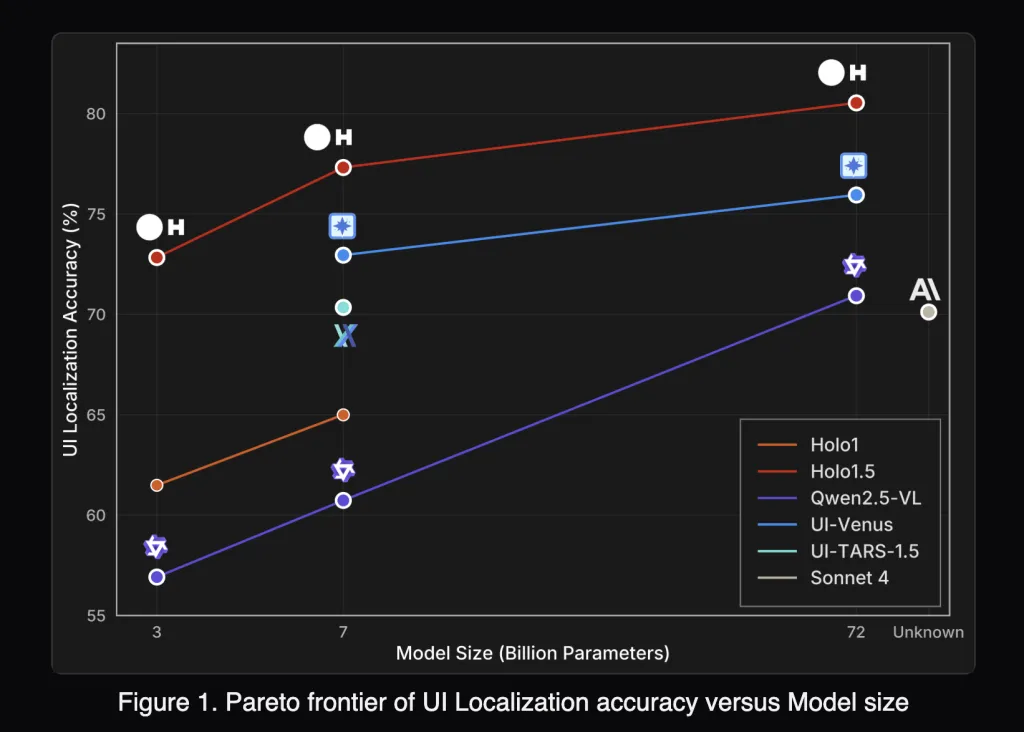
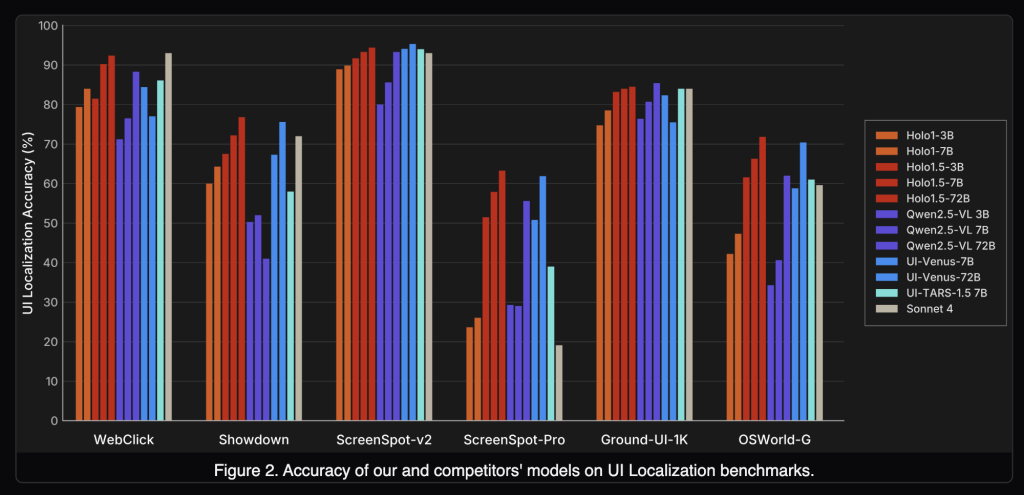
How does Holo1.5 perform on localization benchmarks?
Holo1.5 reports state-of-the-art GUI grounding across ScreenSpot-v2, ScreenSpot-Pro, GroundUI-Web, Showdown, and WebClick. Representative 7B numbers (averages over six localization tracks):
- Holo1.5-7B: 77.32
- Qwen2.5-VL-7B: 60.73
On ScreenSpot-Pro (professional apps with dense layouts), Holo1.5-7B achieves 57.94 vs 29.00 for Qwen2.5-VL-7B, indicating materially better target selection under realistic conditions. The 3B and 72B checkpoints exhibit similar relative gains versus their Qwen2.5-VL counterparts.
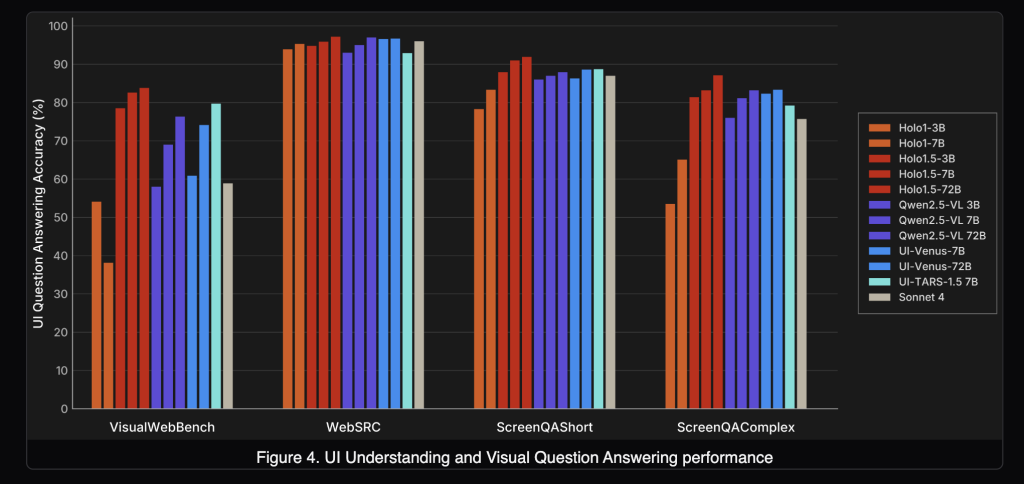
Does it also improve UI understanding (UI-VQA)?
Yes. On VisualWebBench, WebSRC, and ScreenQA (short/complex), Holo1.5 yields consistent accuracy improvements. Reported 7B averages are ≈88.17, with the 72B variant around ≈90.00. This matters for agent reliability: queries like “Which tab is active?” or “Is the user signed in?” reduce ambiguity and enable verification between actions.
How does it compare to specialized and closed systems?
Under the published evaluation setup, Holo1.5 outperforms open baselines (Qwen2.5-VL), competitive specialized systems (e.g., UI-TARS, UI-Venus) and shows advantages versus closed generalist models (e.g., Claude Sonnet 4) on the cited UI tasks. Since protocols, prompts, and screen resolutions influence outcomes, practitioners should replicate with their harness before drawing deployment-level conclusions.
What are the integration implications for CU agents?
- Higher click reliability at native resolution: Better ScreenSpot-Pro performance suggests reduced misclicks in complex applications (IDEs, design suites, admin consoles).
- Stronger state tracking: Higher UI-VQA accuracy improves detection of logged-in state, active tab, modal visibility, and success/failure cues.
- Pragmatic licensing path: 7B (Apache-2.0) is suitable for production. The 72B checkpoint is currently research-only; use it for internal experiments or to bound headroom.
Where does Holo1.5 fit in a modern CU stack?
Think of Holo1.5 as the screen perception layer:
- Input: full-resolution screenshots (optionally with UI metadata).
- Outputs: target coordinates with confidence; short textual answers about screen state.
- Downstream: action policies convert predictions into click/keyboard events; monitoring verifies post-conditions and triggers retries or fallbacks.
Summary
Holo1.5 narrows a practical gap in CU systems by pairing strong coordinate grounding with concise interface understanding. If you need a commercially usable base today, start with Holo1.5-7B (Apache-2.0), benchmark on your screens, and instrument your planner/safety layers around it.
Check out the and. Feel free to check out our . Also, feel free to follow us on and don’t forget to join our and Subscribe to .
The post appeared first on .
 September 18, 2025
September 18, 2025Alibaba Releases Tongyi DeepResearch: A 30B-Parameter Open-Source Agentic LLM Optimized for Long-Horizon Research
Table of contents
Alibaba’s Tongyi Lab has open-sourced Tongyi-DeepResearch-30B-A3B, an agent-specialized large language model built for long-horizon, deep information-seeking with web tools. The model uses a mixture-of-experts (MoE) design with ~30.5B total parameters and ~3–3.3B active per token, enabling high throughput while preserving strong reasoning performance. It targets multi-turn research workflows—searching, browsing, extracting, cross-checking, and synthesizing evidence—under ReAct-style tool use and a heavier test-time scaling mode. The release includes weights (Apache-2.0), inference scripts, and evaluation utilities.
What the benchmarks show?
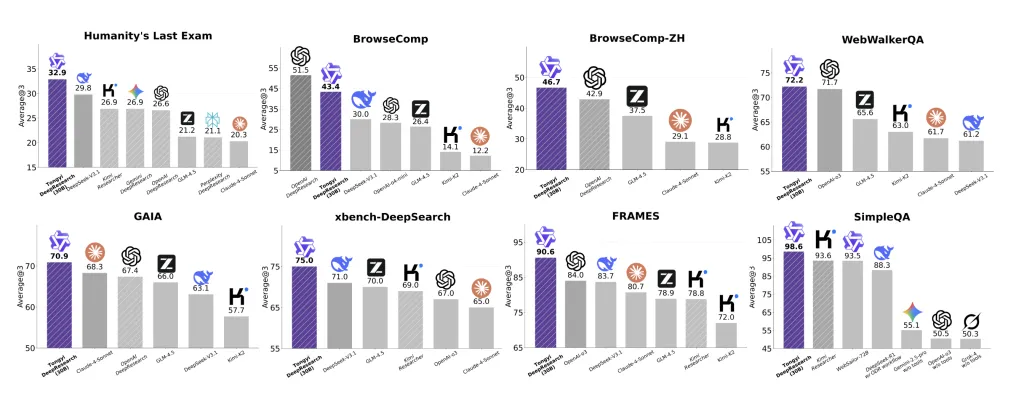
Tongyi DeepResearch reports state-of-the-art results on agentic search suites frequently used to test “deep research” agents:
- Humanity’s Last Exam (HLE): 32.9,
- BrowseComp: 43.4 (EN) and 46.7 (ZH),
- xbench-DeepSearch: 75,
with additional strong results across WebWalkerQA, GAIA, FRAMES, and SimpleQA. The team finds the system as on par with OpenAI-style deep research agents and “systematically outperforming existing proprietary and open-source” agents across these tasks.
Architecture and inference profile
- MoE routing (Qwen3-MoE lineage) with ≈30.5B total / ≈3.3B active parameters, giving the cost envelope of a small dense model while retaining specialist capacity.
- Context length: 128K tokens, suitable for long, tool-augmented browsing sessions and iterative synthesis.
- Dual inference modes:
- ReAct (native) for direct evaluation of intrinsic reasoning and tool use,
- IterResearch “Heavy” mode for test-time scaling with structured multi-round synthesis/reconstruction of context to reduce noise accumulation.
Training pipeline: synthetic data + on-policy RL
Tongyi DeepResearch is trained end-to-end as an agent, not just a chat LLM, using a fully automated, scalable data engine:
- Agentic continual pre-training (CPT): large-scale synthetic trajectories built from curated corpora, historical tool traces, and graph-structured knowledge to teach retrieval, browsing, and multi-source fusion.
- Agentic SFT cold-start: trajectories in ReAct and IterResearch formats for schema-consistent planning and tool use.
- On-policy RL with Group Relative Policy Optimization (GRPO), token-level policy gradients, leave-one-out advantage estimation, and negative-sample filtering to stabilize learning in non-stationary web environments.
Role in document and web research workflows
Deep-research tasks stress four capabilities: (1) long-horizon planning, (2) iterative retrieval and verification across sources, (3) evidence tracking with low hallucination rates, and (4) synthesis under large contexts. The IterResearch rollout restructures context each “round,” retaining only essential artifacts to mitigate context bloat and error propagation, while the ReAct baseline demonstrates that the behaviors are learned rather than prompt-engineered. The reported scores on HLE and BrowseComp suggest improved robustness on multi-hop, tool-mediated queries where prior agents often over-fit to prompt patterns or saturate at low depths.
Key features of Tongyi DeepResearch-30B-A3B
- MoE efficiency at scale: ~30.5B total parameters with ~3.0–3.3B activated per token (Qwen3-MoE lineage), enabling small-model inference cost with large-model capacity.
- 128K context window: long-horizon rollouts with evidence accumulation for multi-step web research.
- Dual inference paradigms: native ReAct for intrinsic tool-use evaluation and IterResearch “Heavy” (test-time scaling) for deeper multi-round synthesis.
- Automated agentic data engine: fully automated synthesis pipeline powering agentic continual pre-training (CPT), supervised fine-tuning (SFT), and RL.
- On-policy RL with GRPO: Group Relative Policy Optimization with token-level policy gradients, leave-one-out advantage estimation, and selective negative-sample filtering for stability.
- Reported SOTA on deep-research suites: HLE 32.9, BrowseComp 43.4 (EN) / 46.7 (ZH), xbench-DeepSearch 75; strong results on WebWalkerQA/GAIA/FRAMES/SimpleQA.
Summary
Tongyi DeepResearch-30B-A3B packages a MoE (~30B total, ~3B active) architecture, 128K context, dual ReAct/IterResearch rollouts, and an automated agentic data + GRPO RL pipeline into a reproducible open-source stack. For teams building long-horizon research agents, it offers a practical balance of inference cost and capability with reported strong performance on deep-research benchmarks
ws where precision and reliability are critical.
Check out the , and . Feel free to check out our . Also, feel free to follow us on and don’t forget to join our and Subscribe to .
The post appeared first on .