 September 20, 2025
September 20, 2025xAI launches Grok-4-Fast: Unified Reasoning and Non-Reasoning Model with 2M-Token Context and Trained End-to-End with Tool-Use Reinforcement Learning (RL)
xAI introduced , a cost-optimized successor to Grok-4 that merges “reasoning” and “non-reasoning” behaviors into a single set of weights controllable via system prompts. The model targets high-throughput search, coding, and Q&A with a 2M-token context window and native tool-use RL that decides when to browse the web, execute code, or call tools.
Architecture note
Previous Grok releases split long-chain “reasoning” and short “non-reasoning” responses across separate models. Grok-4-Fast’s unified weight space reduces end-to-end latency and tokens by steering behavior via system prompts, which is relevant for real-time applications (search, assistive agents, and interactive coding) where switching models penalizes both latency and cost.
Search and agentic use
Grok-4-Fast was trained end-to-end with tool-use reinforcement learning and shows gains on search-centric agent benchmarks: BrowseComp 44.9%, SimpleQA 95.0%, Reka Research 66.0%, plus higher scores on Chinese variants (e.g., BrowseComp-zh 51.2%). xAI also cites private battle-testing on LMArena where grok-4-fast-search (codename “menlo”) ranks #1 in the Search Arena with 1163 Elo, and the text variant (codename “tahoe”) sits at #8 in the Text Arena, roughly on par with grok-4-0709.
Performance and efficiency deltas
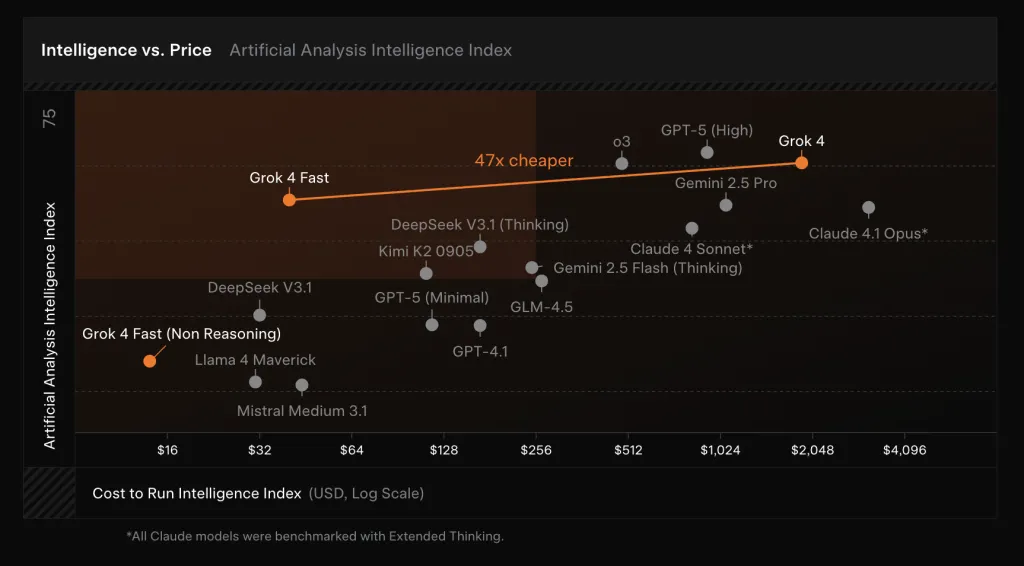
On internal and public benchmarks, Grok-4-Fast posts frontier-class scores while cutting token usage. xAI reports pass@1 results of 92.0% (AIME 2025, no tools), 93.3% (HMMT 2025, no tools), 85.7% (GPQA Diamond), and 80.0% (LiveCodeBench Jan–May), approaching or matching Grok-4 but using ~40% fewer “thinking” tokens on average. The company frames this as “intelligence density,” claiming a ~98% reduction in price to reach the same benchmark performance as Grok-4 when the lower token count and new per-token pricing are combined.
Deployment and price
The model is generally available to all users in Grok’s Fast and Auto modes across web and mobile; Auto will select Grok-4-Fast for difficult queries to improve latency without losing quality, and—for the first time—free users access xAI’s latest model tier. For developers, xAI exposes two SKUs—grok-4-fast-reasoning and grok-4-fast-non-reasoning—both with 2M context. Pricing (xAI API) is $0.20 / 1M input tokens (<128k), $0.40 / 1M input tokens (≥128k), $0.50 / 1M output tokens (<128k), $1.00 / 1M output tokens (≥128k), and $0.05 / 1M cached input tokens.
5 Technical Takeaways:
- Unified model + 2M context. Grok-4-Fast uses a single weight space for “reasoning” and “non-reasoning,” prompt-steered, with a 2,000,000-token window across both SKUs.
- Pricing for scale. API pricing starts at $0.20/M input, $0.50/M output, with cached input at $0.05/M and higher rates only beyond 128K context.
- Efficiency claims. xAI reports ~40% fewer “thinking” tokens at comparable accuracy vs Grok-4, yielding a ~98% lower price to match Grok-4 performance on frontier benchmarks.
- Benchmark profile. Reported pass@1: AIME-2025 92.0%, HMMT-2025 93.3%, GPQA-Diamond 85.7%, LiveCodeBench (Jan–May) 80.0%.
- Agentic/search use. Post-training with tool-use RL; positioned for browsing/search workflows with documented search-agent metrics and live-search billing in docs.
Summary
Grok-4-Fast packages Grok-4-level capability into a single, prompt-steerable model with a 2M-token window, tool-use RL, and pricing tuned for high-throughput search and agent workloads. Early public signals (LMArena #1 in Search, competitive Text placement) align with xAI’s claim of similar accuracy using ~40% fewer “thinking” tokens, translating to lower latency and unit cost in production.
Check out the . Feel free to check out our . Also, feel free to follow us on and don’t forget to join our and Subscribe to .
The post appeared first on .

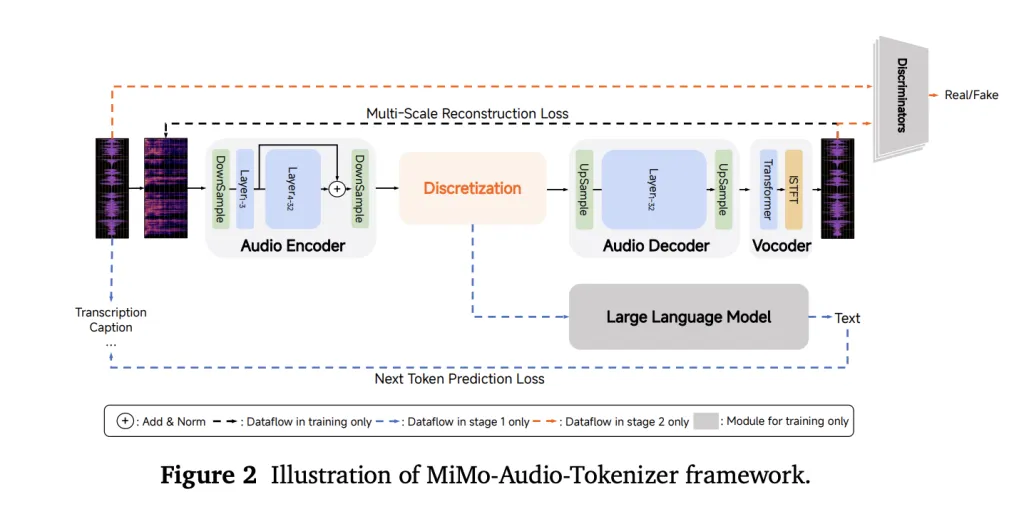
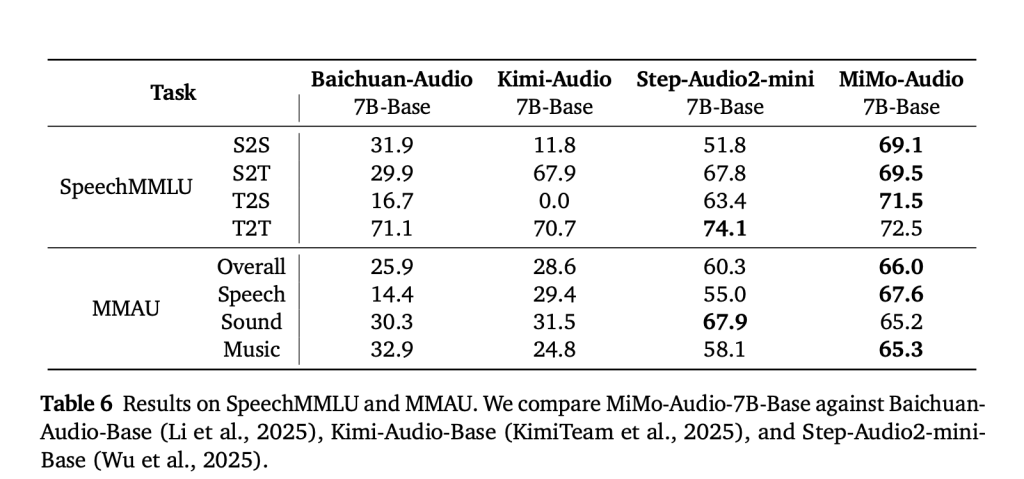
 speech modality gap, generalizes across speech/sound/music benchmarks, and supports in-context S2S editing and continuation.
speech modality gap, generalizes across speech/sound/music benchmarks, and supports in-context S2S editing and continuation.