December 29, 2025
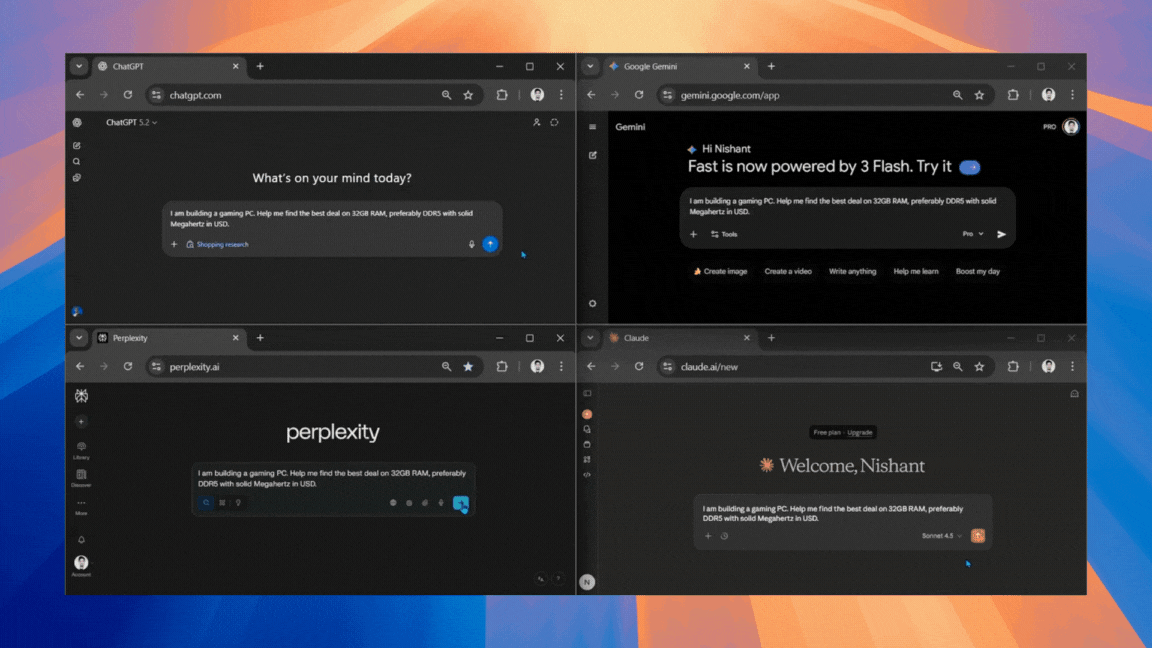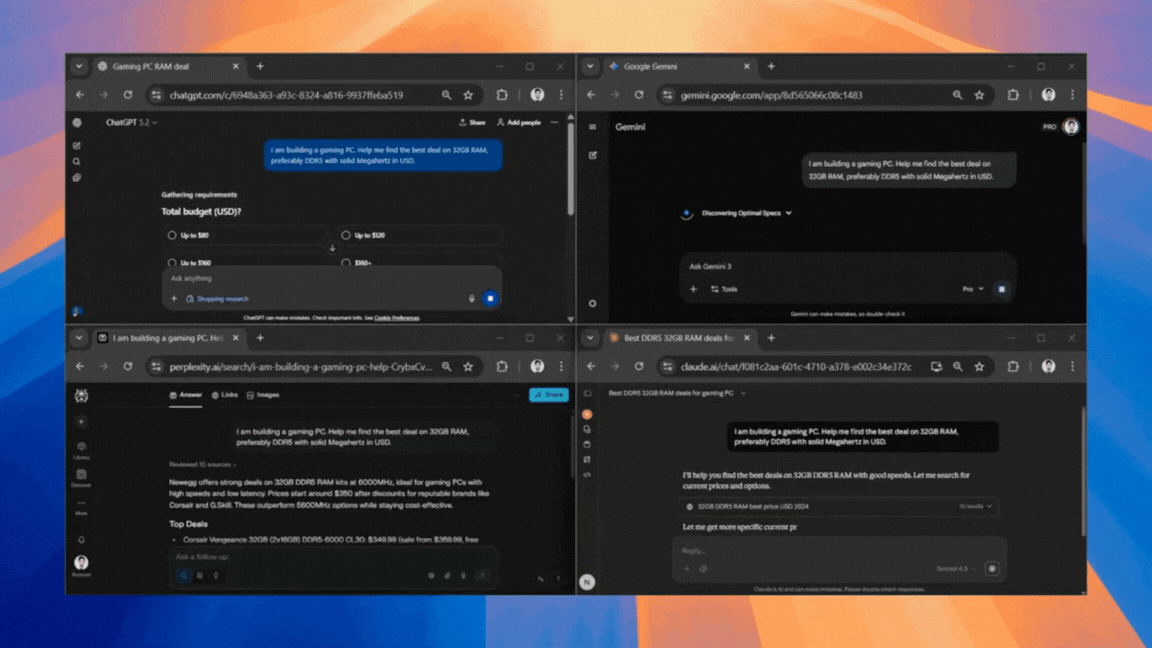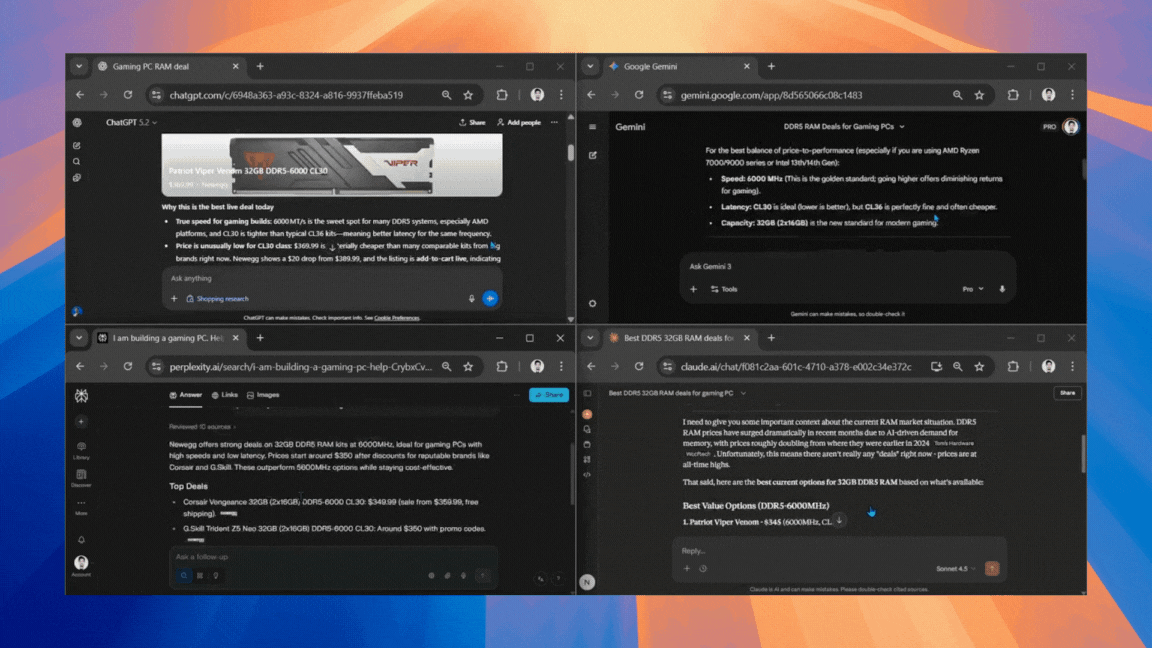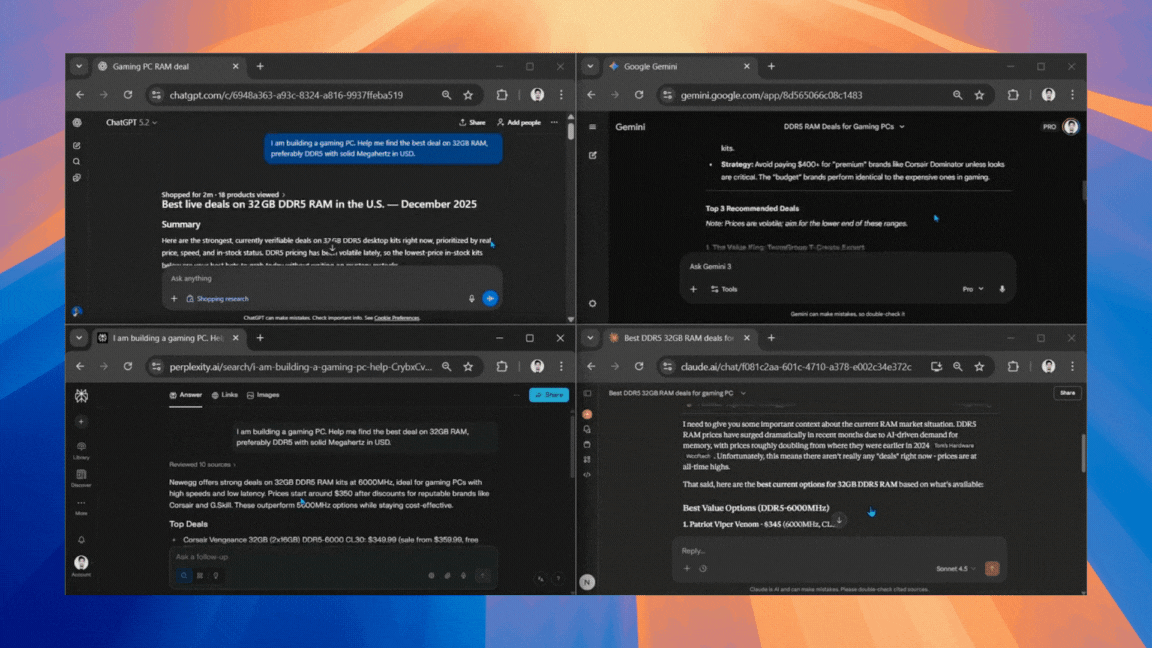
December 29, 20253 New Tricks to Try With Google Gemini Live After Its Latest Major Upgrade
Google’s AI is now even smarter, and more versatile.
 December 29, 2025
December 29, 2025Google’s AI is now even smarter, and more versatile.
 December 29, 2025
December 29, 2025
In this tutorial, we demonstrate how to design a contract-first agentic decision system using , treating structured schemas as non-negotiable governance contracts rather than optional output formats. We show how we define a strict decision model that encodes policy compliance, risk assessment, confidence calibration, and actionable next steps directly into the agent’s output schema. By combining Pydantic validators with PydanticAI’s retry and self-correction mechanisms, we ensure that the agent cannot produce logically inconsistent or non-compliant decisions. Throughout the workflow, we focus on building an enterprise-grade decision agent that reasons under constraints, making it suitable for real-world risk, compliance, and governance scenarios rather than toy prompt-based demos. Check out the .
!pip -q install -U pydantic-ai pydantic openai nest_asyncio
import os
import time
import asyncio
import getpass
from dataclasses import dataclass
from typing import List, Literal
import nest_asyncio
nest_asyncio.apply()
from pydantic import BaseModel, Field, field_validator
from pydantic_ai import Agent
from pydantic_ai.models.openai import OpenAIChatModel
from pydantic_ai.providers.openai import OpenAIProvider
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
if not OPENAI_API_KEY:
try:
from google.colab import userdata
OPENAI_API_KEY = userdata.get("OPENAI_API_KEY")
except Exception:
OPENAI_API_KEY = None
if not OPENAI_API_KEY:
OPENAI_API_KEY = getpass.getpass("Enter OPENAI_API_KEY: ").strip()We set up the execution environment by installing the required libraries and configuring asynchronous execution for Google Colab. We securely load the OpenAI API key and ensure the runtime is ready to handle async agent calls. This establishes a stable foundation for running the contract-first agent without environment-related issues. Check out the .
class RiskItem(BaseModel):
risk: str = Field(..., min_length=8)
severity: Literal["low", "medium", "high"]
mitigation: str = Field(..., min_length=12)
class DecisionOutput(BaseModel):
decision: Literal["approve", "approve_with_conditions", "reject"]
confidence: float = Field(..., ge=0.0, le=1.0)
rationale: str = Field(..., min_length=80)
identified_risks: List[RiskItem] = Field(..., min_length=2)
compliance_passed: bool
conditions: List[str] = Field(default_factory=list)
next_steps: List[str] = Field(..., min_length=3)
timestamp_unix: int = Field(default_factory=lambda: int(time.time()))
@field_validator("confidence")
@classmethod
def confidence_vs_risk(cls, v, info):
risks = info.data.get("identified_risks") or []
if any(r.severity == "high" for r in risks) and v > 0.70:
raise ValueError("confidence too high given high-severity risks")
return v
@field_validator("decision")
@classmethod
def reject_if_non_compliant(cls, v, info):
if info.data.get("compliance_passed") is False and v != "reject":
raise ValueError("non-compliant decisions must be reject")
return v
@field_validator("conditions")
@classmethod
def conditions_required_for_conditional_approval(cls, v, info):
d = info.data.get("decision")
if d == "approve_with_conditions" and (not v or len(v) < 2):
raise ValueError("approve_with_conditions requires at least 2 conditions")
if d == "approve" and v:
raise ValueError("approve must not include conditions")
return vWe define the core decision contract using strict Pydantic models that precisely describe a valid decision. We encode logical constraints such as confidence–risk alignment, compliance-driven rejection, and conditional approvals directly into the schema. This ensures that any agent output must satisfy business logic, not just syntactic structure. Check out the .
@dataclass
class DecisionContext:
company_policy: str
risk_threshold: float = 0.6
model = OpenAIChatModel(
"gpt-5",
provider=OpenAIProvider(api_key=OPENAI_API_KEY),
)
agent = Agent(
model=model,
deps_type=DecisionContext,
output_type=DecisionOutput,
system_prompt="""
You are a corporate decision analysis agent.
You must evaluate risk, compliance, and uncertainty.
All outputs must strictly satisfy the DecisionOutput schema.
"""
)
We inject enterprise context through a typed dependency object and initialize the OpenAI-backed PydanticAI agent. We configure the agent to produce only structured decision outputs that conform to the predefined contract. This step formalizes the separation between business context and model reasoning. Check out the .
@agent.output_validator
def ensure_risk_quality(result: DecisionOutput) -> DecisionOutput:
if len(result.identified_risks) < 2:
raise ValueError("minimum two risks required")
if not any(r.severity in ("medium", "high") for r in result.identified_risks):
raise ValueError("at least one medium or high risk required")
return result
@agent.output_validator
def enforce_policy_controls(result: DecisionOutput) -> DecisionOutput:
policy = CURRENT_DEPS.company_policy.lower()
text = (
result.rationale
+ " ".join(result.next_steps)
+ " ".join(result.conditions)
).lower()
if result.compliance_passed:
if not any(k in text for k in ["encryption", "audit", "logging", "access control", "key management"]):
raise ValueError("missing concrete security controls")
return resultWe add output validators that act as governance checkpoints after the model generates a response. We force the agent to identify meaningful risks and to explicitly reference concrete security controls when claiming compliance. If these constraints are violated, we trigger automatic retries to enforce self-correction. Check out the .
async def run_decision():
global CURRENT_DEPS
CURRENT_DEPS = DecisionContext(
company_policy=(
"No deployment of systems handling personal data or transaction metadata "
"without encryption, audit logging, and least-privilege access control."
)
)
prompt = """
Decision request:
Deploy an AI-powered customer analytics dashboard using a third-party cloud vendor.
The system processes user behavior and transaction metadata.
Audit logging is not implemented and customer-managed keys are uncertain.
"""
result = await agent.run(prompt, deps=CURRENT_DEPS)
return result.output
decision = asyncio.run(run_decision())
from pprint import pprint
pprint(decision.model_dump())We run the agent on a realistic decision request and capture the validated structured output. We demonstrate how the agent evaluates risk, policy compliance, and confidence before producing a final decision. This completes the end-to-end contract-first decision workflow in a production-style setup.
In conclusion, we demonstrate how to move from free-form LLM outputs to governed, reliable decision systems using PydanticAI. We show that by enforcing hard contracts at the schema level, we can automatically align decisions with policy requirements, risk severity, and confidence realism without manual prompt tuning. This approach allows us to build agents that fail safely, self-correct when constraints are violated, and produce auditable, structured outputs that downstream systems can trust. Ultimately, we demonstrate that contract-first agent design enables us to deploy agentic AI as a dependable decision layer within production and enterprise environments.
Check out the . Also, feel free to follow us on and don’t forget to join our and Subscribe to . Wait! are you on telegram?
The post appeared first on .
 December 28, 2025
December 28, 2025
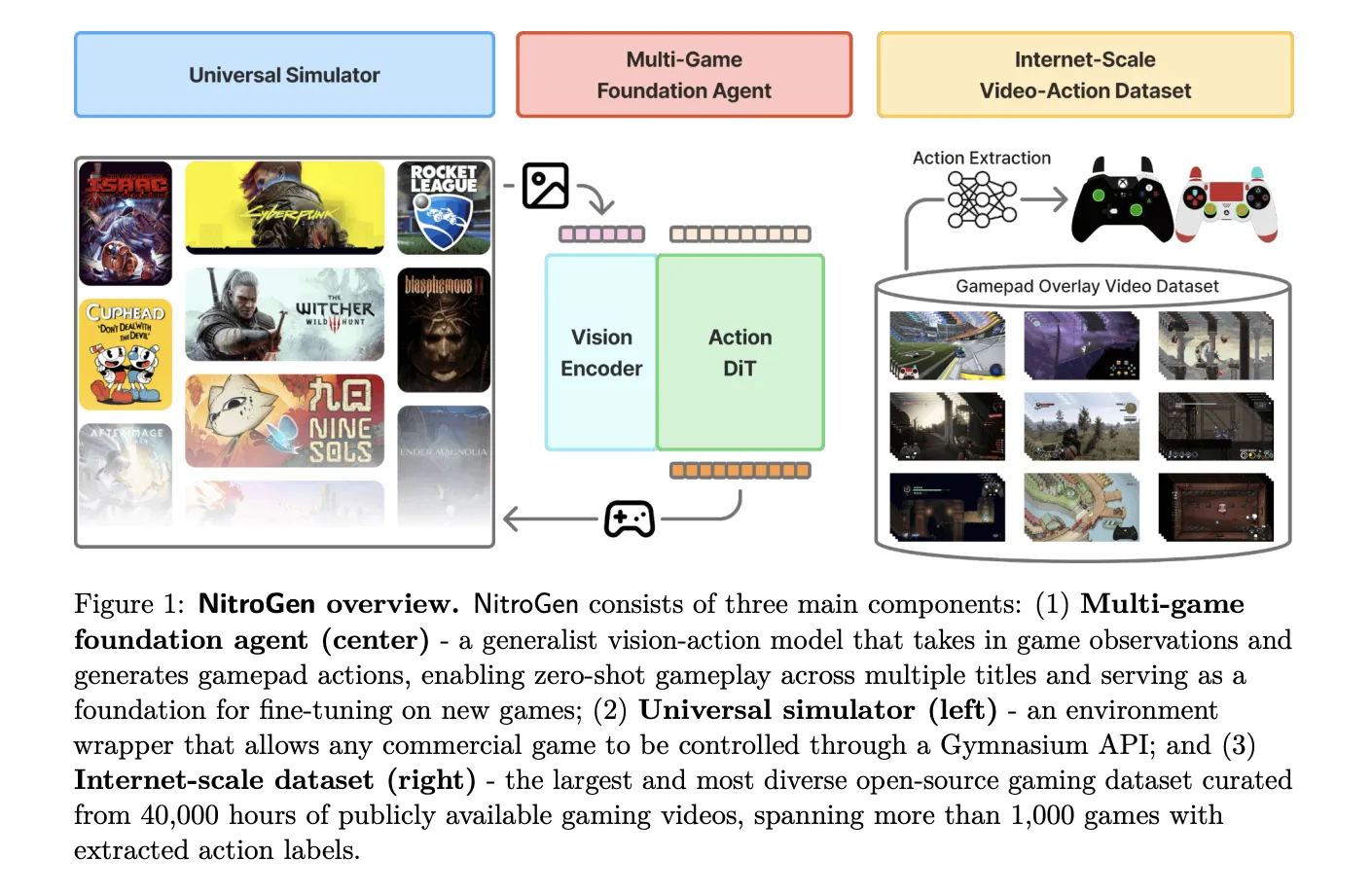
NVIDIA AI research team released NitroGen, an open vision action foundation model for generalist gaming agents that learns to play commercial games directly from pixels and gamepad actions using internet video at scale. NitroGen is trained on 40,000 hours of gameplay across more than 1,000 games and comes with an open dataset, a universal simulator, and a pre trained policy.
The NitroGen pipeline starts from publicly available gameplay videos that include input overlays, for example gamepad visualizations that streamers place in a corner of the screen. The research team collects 71,000 hours of raw video with such overlays, then applies quality filtering based on action density, which leaves 55% of the data, about 40,000 hours, spanning more than 1,000 games.
The curated dataset contains 38,739 videos from 818 creators. The distribution covers a wide range of titles. There are 846 games with more than 1 hour of data, 91 games with more than 100 hours, and 15 games with more than 1,000 hours each. Action RPGs account for 34.9 percent of the hours, platformers for 18.4 percent, and action adventure titles for 9.2 percent, with the rest spread across sports, roguelike, racing and other genres.
To recover frame level actions from raw streams, NitroGen uses a three stage action extraction pipeline. First, a template matching module localizes the controller overlay using about 300 controller templates. For each video, the system samples 25 frames and matches SIFT and XFeat features between frames and templates, then estimates an affine transform when at least 20 inliers support a match. This yields a crop of the controller region for all frames.
Second, a SegFormer based hybrid classification segmentation model parses the controller crops. The model takes two consecutive frames concatenated spatially and outputs joystick locations on an 11 by 11 grid plus binary button states. It is trained on 8 million synthetic images rendered with different controller templates, opacities, sizes and compression settings, using AdamW with learning rate 0.0001, weight decay 0.1, and batch size 256.
Third, the pipeline refines joystick positions and filters low activity segments. Joystick coordinates are normalized to the range from −1.0 to 1.0 using the 99th percentile of absolute x and y values to reduce outliers. Chunks where fewer than 50 percent of timesteps have non zero actions are removed, which avoids over predicting the null action during policy training.
A separate benchmark with ground truth controller logs shows that joystick predictions reach an average R² of 0.84 and button frame accuracy reaches 0.96 across major controller families such as Xbox and PlayStation. This validates that automatic annotations are accurate enough for large scale behavior cloning.
NitroGen includes a universal simulator that wraps commercial Windows games in a Gymnasium compatible interface. The wrapper intercepts the game engine system clock to control simulation time and supports frame by frame interaction without modifying game code, for any title that uses the system clock for physics and interactions.
Observations in this benchmark are single RGB frames. Actions are defined as a unified controller space with a 16 dimensional binary vector for gamepad buttons, four d pad buttons, four face buttons, two shoulders, two triggers, two joystick thumb buttons, start and back, plus a 4 dimensional continuous vector for joystick positions, left and right x,y. This unified layout allows direct transfer of one policy across many games.
The evaluation suite covers 10 commercial games and 30 tasks. There are 5 two dimensional games, three side scrollers and two top down roguelikes, and 5 three dimensional games, two open world games, two combat focused action RPGs and one sports title. Tasks fall into 11 combat tasks, 10 navigation tasks, and 9 game specific tasks with custom objectives.
The NitroGen foundation policy follows the GR00T N1 architecture pattern for embodied agents. It discards the language and state encoders, and keeps a vision encoder plus a single action head. Input is one RGB frame at 256 by 256 resolution. A SigLIP 2 vision transformer encodes this frame into 256 image tokens.
A diffusion transformer, DiT, generates 16 step chunks of future actions. During training, noisy action chunks are embedded by a multilayer perceptron into action tokens, processed by a stack of DiT blocks with self attention and cross attention to visual tokens, then decoded back into continuous action vectors. The training objective is conditional flow matching with 16 denoising steps over each 16 action chunk.
The released checkpoint has 4.93 × 10^8 parameters. The model card describes the output as a 21 by 16 tensor, where 17 dimensions correspond to binary button states and 4 dimensions store two two dimensional joystick vectors, over 16 future timesteps. This representation is consistent with the unified action space, up to reshaping of the joystick components.
NitroGen is trained purely with large scale behavior cloning on the internet video dataset. There is no reinforcement learning and no reward design in the base model. Image augmentations include random brightness, contrast, saturation, hue, small rotations, and random crops. Training uses AdamW with weight decay 0.001, a warmup stable decay learning rate schedule with constant phase at 0.0001, and an exponential moving average of weights with decay 0.9999.
After pre training on the full dataset, NitroGen 500M already achieves non trivial task completion rates in zero shot evaluation across all games in the benchmark. Average completion rates stay in the range from about 45 percent to 60 percent across combat, navigation and game specific tasks, and across two dimensional and three dimensional games, despite the noise in internet supervision.
For transfer to unseen games, the research team hold out a title, pre train on the remaining data, and then fine tune on the held out game under a fixed data and compute budget. On an isometric roguelike, fine tuning from NitroGen gives an average relative improvement of about 10 percent compared with training from scratch. On a three dimensional action RPG, the average gain is about 25 percent, and for some combat tasks in the low data regime, 30 hours, the relative improvement reaches 52 percent.
Check out the and . Also, feel free to follow us on and don’t forget to join our and Subscribe to . Wait! are you on telegram?
The post appeared first on .
 December 28, 2025
December 28, 2025The battle for AI dominance has left a large footprint—and it’s only getting bigger and more expensive.
 December 28, 2025
December 28, 2025
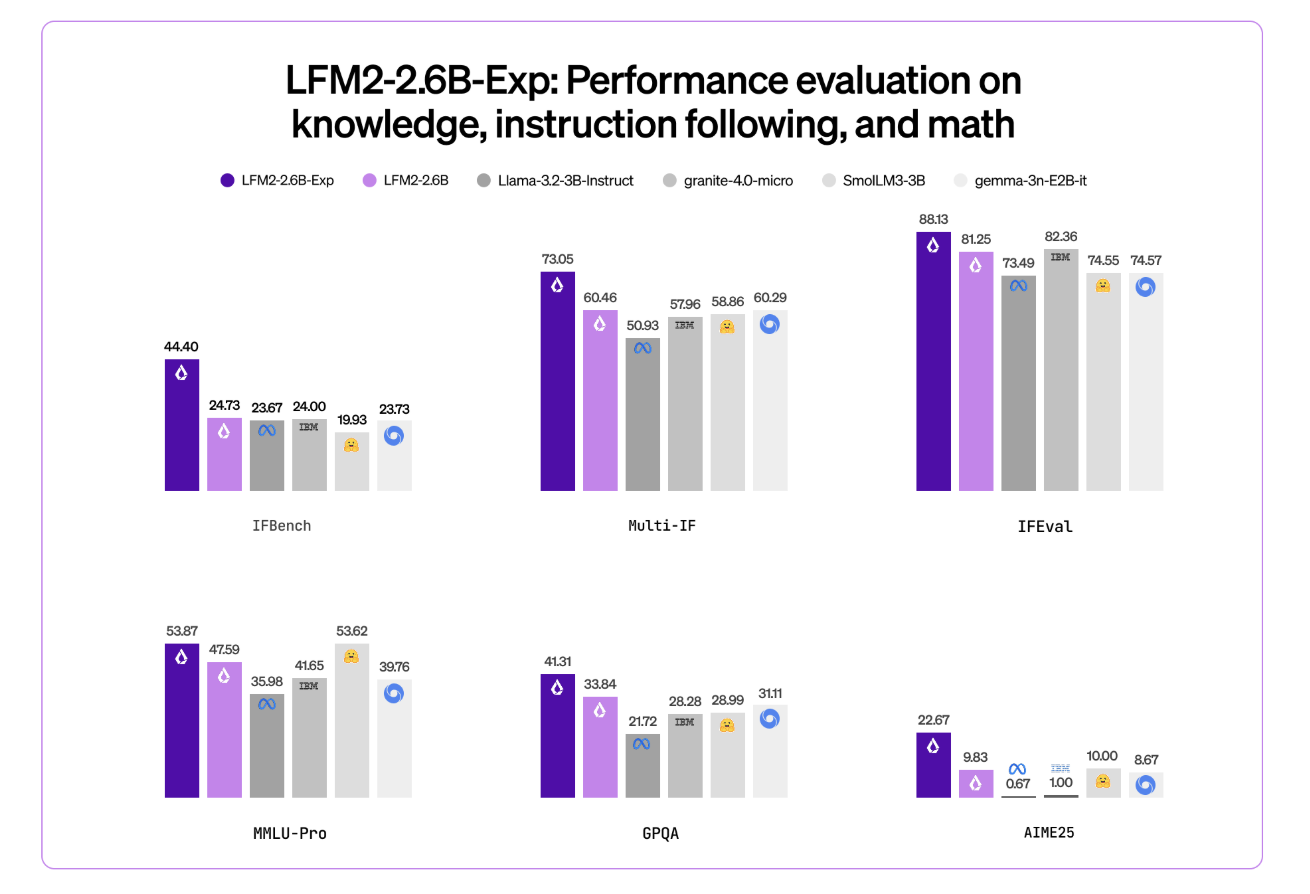
Liquid AI has introduced LFM2-2.6B-Exp, an experimental checkpoint of its LFM2-2.6B language model that is trained with pure reinforcement learning on top of the existing LFM2 stack. The goal is simple, improve instruction following, knowledge tasks, and math for a small 3B class model that still targets on device and edge deployment.
LFM2 is the second generation of Liquid Foundation Models. It is designed for efficient deployment on phones, laptops, and other edge devices. Liquid AI describes LFM2 as a hybrid model that combines short range LIV convolution blocks with grouped query attention blocks, controlled by multiplicative gates.
The family includes 4 dense sizes, LFM2-350M, LFM2-700M, LFM2-1.2B, and LFM2-2.6B. All share a context length of 32,768 tokens, a vocabulary size of 65,536, and bfloat16 precision. The 2.6B model uses 30 layers, with 22 convolution layers and 8 attention layers. Each size is trained on a 10 trillion token budget.
LFM2-2.6B is already positioned as a high efficiency model. It reaches 82.41 percent on GSM8K and 79.56 percent on IFEval. This places it ahead of several 3B class models such as Llama 3.2 3B Instruct, Gemma 3 4B it, and SmolLM3 3B on these benchmarks.
LFM2-2.6B-Exp keeps this architecture. It reuses the same tokenization, context window, and hardware profile. The checkpoint focuses only on changing behavior through a reinforcement learning stage.
This checkpoint is built on LFM2-2.6B using pure reinforcement learning. It is specifically trained on instruction following, knowledge, and math.
The underlying LFM2 training stack combines several stages. It includes very large scale supervised fine tuning on a mix of downstream tasks and general domains, custom Direct Preference Optimization with length normalization, iterative model merging, and reinforcement learning with verifiable rewards.
But exactly ‘pure reinforcement learning’ means? LFM2-2.6B-Exp starts from the existing LFM2-2.6B checkpoint and then goes through a sequential RL training schedule. It begin with instruction following, then extend RL training to knowledge oriented prompts, math, and a small amount of tool use, without an additional SFT warm up or distillation step in that final phase.
The important point is that LFM2-2.6B-Exp does not change the base architecture or pre training. It changes the policy through an RL stage that uses verifiable rewards, on a targeted set of domains, on top of a model that is already supervised and preference aligned.
Liquid AI team highlights IFBench as the main headline metric. IFBench is an instruction following benchmark that checks how reliably a model follows complex, constrained instructions. On this benchmark, LFM2-2.6B-Exp surpasses DeepSeek R1-0528, which is reported as 263 times larger in parameter count.
LFM2 models provide strong performance across a standard set of benchmarks such as MMLU, GPQA, IFEval, GSM8K, and related suites. The 2.6B base model already competes well in the 3B segment. The RL checkpoint then pushes instruction following and math further, while staying in the same 3B parameter budget.
The architecture uses 10 double gated short range LIV convolution blocks and 6 grouped query attention blocks, arranged in a hybrid stack. This design reduces KV cache cost and keeps inference fast on consumer GPUs and NPUs.
The pre training mixture uses roughly 75 percent English, 20 percent multilingual data, and 5 percent code. The supported languages include English, Arabic, Chinese, French, German, Japanese, Korean, and Spanish.
LFM2 models expose a ChatML like template and native tool use tokens. Tools are described as JSON between dedicated tool list markers. The model then emits Python like calls between tool call markers and reads tool responses between tool response markers. This structure makes the model suitable as the agent core for tool calling stacks without custom prompt engineering.
LFM2-2.6B, and by extension LFM2-2.6B-Exp, is also the only model in the family that enables dynamic hybrid reasoning through special think tokens for complex or multilingual inputs. That capability remains available because the RL checkpoint does not change tokenization or architecture.
Check out the . Also, feel free to follow us on and don’t forget to join our and Subscribe to . Wait! are you on telegram?
The post appeared first on .
 December 27, 2025
December 27, 2025
In this tutorial, we build an end-to-end, production-style agentic workflow using that demonstrates how graph-structured execution, tool calling, and optional LLM-driven agents can coexist in a single system. We start by initializing and inspecting the GraphBit runtime, then define a realistic customer-support ticket domain with typed data structures and deterministic, offline-executable tools. We show how these tools can be composed into a reliable, rule-based pipeline for classification, routing, and response drafting, and then elevate that same logic into a validated GraphBit workflow in which agent nodes orchestrate tool usage via a directed graph. Throughout the tutorial, we keep the system running in offline mode while enabling seamless promotion to online execution by simply providing an LLM configuration, illustrating how GraphBit supports the gradual adoption of agentic intelligence without sacrificing reproducibility or operational control. Check out the .
!pip -q install graphbit rich pydantic numpy
import os
import time
import json
import random
from dataclasses import dataclass
from typing import Dict, Any, List, Optional
import numpy as np
from rich import print as rprint
from rich.panel import Panel
from rich.table import TableWe begin by installing all required dependencies and importing the core Python, numerical, and visualization libraries needed for the tutorial. We set up the runtime environment so the notebook remains self-contained and reproducible on Google Colab. Check out the .
from graphbit import init, shutdown, configure_runtime, get_system_info, health_check, version
from graphbit import Workflow, Node, Executor, LlmConfig
from graphbit import tool, ToolExecutor, ExecutorConfig
from graphbit import get_tool_registry, clear_tools
configure_runtime(worker_threads=4, max_blocking_threads=8, thread_stack_size_mb=2)
init(log_level="warn", enable_tracing=False, debug=False)
info = get_system_info()
health = health_check()
sys_table = Table(title="System Info / Health")
sys_table.add_column("Key", style="bold")
sys_table.add_column("Value")
for k in ["version", "python_binding_version", "cpu_count", "runtime_worker_threads", "runtime_initialized", "build_target", "build_profile"]:
sys_table.add_row(k, str(info.get(k)))
sys_table.add_row("graphbit_version()", str(version()))
sys_table.add_row("overall_healthy", str(health.get("overall_healthy")))
rprint(sys_table)We initialize the GraphBit runtime and explicitly configure its execution parameters to control threading and resource usage. We then query system metadata and perform a health check to verify that the runtime is correctly initialized. Check out the .
@dataclass
class Ticket:
ticket_id: str
user_id: str
text: str
created_at: float
def make_tickets(n: int = 10) -> List[Ticket]:
seeds = [
"My card payment failed twice, what should I do?",
"I want to cancel my subscription immediately.",
"Your app crashes when I open the dashboard.",
"Please update my email address on the account.",
"Refund not received after 7 days.",
"My delivery is delayed and tracking is stuck.",
"I suspect fraudulent activity on my account.",
"How can I change my billing cycle date?",
"The website is very slow and times out.",
"I forgot my password and cannot login.",
"Chargeback process details please.",
"Need invoice for last month’s payment."
]
random.shuffle(seeds)
out = []
for i in range(n):
out.append(
Ticket(
ticket_id=f"T-{1000+i}",
user_id=f"U-{random.randint(100,999)}",
text=seeds[i % len(seeds)],
created_at=time.time() - random.randint(0, 7 * 24 * 3600),
)
)
return out
tickets = make_tickets(10)
rprint(Panel.fit("n".join([f"- {t.ticket_id}: {t.text}" for t in tickets]), title="Sample Tickets"))We define a strongly typed data model for support tickets and generate a synthetic dataset that simulates realistic customer issues. We construct tickets with timestamps and identifiers to mirror production inputs. This dataset serves as the shared input across both offline and agent-driven pipelines. Check out the .
clear_tools()
@tool(_description="Classify a support ticket into a coarse category.")
def classify_ticket(text: str) -> Dict[str, Any]:
t = text.lower()
if "fraud" in t or "fraudulent" in t:
return {"category": "fraud", "priority": "p0"}
if "cancel" in t:
return {"category": "cancellation", "priority": "p1"}
if "refund" in t or "chargeback" in t:
return {"category": "refunds", "priority": "p1"}
if "password" in t or "login" in t:
return {"category": "account_access", "priority": "p2"}
if "crash" in t or "slow" in t or "timeout" in t:
return {"category": "bug", "priority": "p2"}
if "payment" in t or "billing" in t or "invoice" in t:
return {"category": "billing", "priority": "p2"}
if "delivery" in t or "tracking" in t:
return {"category": "delivery", "priority": "p3"}
return {"category": "general", "priority": "p3"}
@tool(_description="Route a ticket to a queue (returns queue id and SLA hours).")
def route_ticket(category: str, priority: str) -> Dict[str, Any]:
queue_map = {
"fraud": ("risk_ops", 2),
"cancellation": ("retention", 8),
"refunds": ("payments_ops", 12),
"account_access": ("identity", 12),
"bug": ("engineering_support", 24),
"billing": ("billing_support", 24),
"delivery": ("logistics_support", 48),
"general": ("support_general", 48),
}
q, sla = queue_map.get(category, ("support_general", 48))
if priority == "p0":
sla = min(sla, 2)
elif priority == "p1":
sla = min(sla, 8)
return {"queue": q, "sla_hours": sla}
@tool(_description="Generate a playbook response based on category + priority.")
def draft_response(category: str, priority: str, ticket_text: str) -> Dict[str, Any]:
templates = {
"fraud": "We’ve temporarily secured your account. Please confirm last 3 transactions and reset credentials.",
"cancellation": "We can help cancel your subscription. Please confirm your plan and the effective date you want.",
"refunds": "We’re checking the refund status. Please share the order/payment reference and date.",
"account_access": "Let’s get you back in. Please use the password reset link; if blocked, we’ll verify identity.",
"bug": "Thanks for reporting. Please share device/browser + a screenshot; we’ll attempt reproduction.",
"billing": "We can help with billing. Please confirm the last 4 digits and the invoice period you need.",
"delivery": "We’re checking shipment status. Please share your tracking ID and delivery address PIN/ZIP.",
"general": "Thanks for reaching out."
}
base = templates.get(category, templates["general"])
tone = "urgent" if priority == "p0" else ("fast" if priority == "p1" else "standard")
return {
"tone": tone,
"message": f"{base}nnContext we received: '{ticket_text}'",
"next_steps": ["request_missing_info", "log_case", "route_to_queue"]
}
registry = get_tool_registry()
tools_list = registry.list_tools() if hasattr(registry, "list_tools") else []
rprint(Panel.fit(f"Registered tools: {tools_list}", title="Tool Registry"))We register deterministic business tools for ticket classification, routing, and response drafting using GraphBit’s tool interface. We encode domain logic directly into these tools so they can be executed without any LLM dependency. This establishes a reliable, testable foundation for later agent orchestration. Check out the .
tool_exec_cfg = ExecutorConfig(
max_execution_time_ms=10_000,
max_tool_calls=50,
continue_on_error=False,
store_results=True,
enable_logging=False
)
tool_executor = ToolExecutor(config=tool_exec_cfg) if "config" in ToolExecutor.__init__.__code__.co_varnames else ToolExecutor()
def offline_triage(ticket: Ticket) -> Dict[str, Any]:
c = classify_ticket(ticket.text)
rt = route_ticket(c["category"], c["priority"])
dr = draft_response(c["category"], c["priority"], ticket.text)
return {
"ticket_id": ticket.ticket_id,
"user_id": ticket.user_id,
"category": c["category"],
"priority": c["priority"],
"queue": rt["queue"],
"sla_hours": rt["sla_hours"],
"draft": dr["message"],
"tone": dr["tone"],
"steps": [
("classify_ticket", c),
("route_ticket", rt),
("draft_response", dr),
]
}
offline_results = [offline_triage(t) for t in tickets]
res_table = Table(title="Offline Pipeline Results")
res_table.add_column("Ticket", style="bold")
res_table.add_column("Category")
res_table.add_column("Priority")
res_table.add_column("Queue")
res_table.add_column("SLA (h)")
for r in offline_results:
res_table.add_row(r["ticket_id"], r["category"], r["priority"], r["queue"], str(r["sla_hours"]))
rprint(res_table)
prio_counts: Dict[str, int] = {}
sla_vals: List[int] = []
for r in offline_results:
prio_counts[r["priority"]] = prio_counts.get(r["priority"], 0) + 1
sla_vals.append(int(r["sla_hours"]))
metrics = {
"offline_mode": True,
"tickets": len(offline_results),
"priority_distribution": prio_counts,
"sla_mean": float(np.mean(sla_vals)) if sla_vals else None,
"sla_p95": float(np.percentile(sla_vals, 95)) if sla_vals else None,
}
rprint(Panel.fit(json.dumps(metrics, indent=2), title="Offline Metrics"))We compose the registered tools into an offline execution pipeline and apply it across all tickets to produce structured triage results. We aggregate outputs into tables and compute priority and SLA metrics to evaluate system behavior. It demonstrates how GraphBit-based logic can be validated deterministically before introducing agents. Check out the .
SYSTEM_POLICY = "You are a reliable support ops agent. Return STRICT JSON only."
workflow = Workflow("Ticket Triage Workflow (GraphBit)")
summarizer = Node.agent(
name="Summarizer",
agent_id="summarizer",
system_prompt=SYSTEM_POLICY,
prompt="Summarize this ticket in 1-2 lines. Return JSON: {"summary":"..."}nTicket: {input}",
temperature=0.2,
max_tokens=200
)
router_agent = Node.agent(
name="RouterAgent",
agent_id="router",
system_prompt=SYSTEM_POLICY,
prompt=(
"You MUST use tools.n"
"Call classify_ticket(text), route_ticket(category, priority), draft_response(category, priority, ticket_text).n"
"Return JSON with fields: category, priority, queue, sla_hours, message.n"
"Ticket: {input}"
),
tools=[classify_ticket, route_ticket, draft_response],
temperature=0.1,
max_tokens=700
)
formatter = Node.agent(
name="FinalFormatter",
agent_id="final_formatter",
system_prompt=SYSTEM_POLICY,
prompt=(
"Validate the JSON and output STRICT JSON only:n"
"{"ticket_id":"...","category":"...","priority":"...","queue":"...","sla_hours":0,"customer_message":"..."}n"
"Input: {input}"
),
temperature=0.0,
max_tokens=500
)
sid = workflow.add_node(summarizer)
rid = workflow.add_node(router_agent)
fid = workflow.add_node(formatter)
workflow.connect(sid, rid)
workflow.connect(rid, fid)
workflow.validate()
rprint(Panel.fit("Workflow validated: Summarizer -> RouterAgent -> FinalFormatter", title="Workflow Graph"))We construct a directed GraphBit workflow composed of multiple agent nodes with clearly defined responsibilities and strict JSON contracts. We connect these nodes into a validated execution graph that mirrors the earlier offline logic at an agent level. Check out the .
def pick_llm_config() -> Optional[Any]:
if os.getenv("OPENAI_API_KEY"):
return LlmConfig.openai(os.getenv("OPENAI_API_KEY"), "gpt-4o-mini")
if os.getenv("ANTHROPIC_API_KEY"):
return LlmConfig.anthropic(os.getenv("ANTHROPIC_API_KEY"), "claude-sonnet-4-20250514")
if os.getenv("DEEPSEEK_API_KEY"):
return LlmConfig.deepseek(os.getenv("DEEPSEEK_API_KEY"), "deepseek-chat")
if os.getenv("MISTRALAI_API_KEY"):
return LlmConfig.mistralai(os.getenv("MISTRALAI_API_KEY"), "mistral-large-latest")
return None
def run_agent_flow_once(ticket_text: str) -> Dict[str, Any]:
llm_cfg = pick_llm_config()
if llm_cfg is None:
return {
"mode": "offline",
"note": "Set OPENAI_API_KEY / ANTHROPIC_API_KEY / DEEPSEEK_API_KEY / MISTRALAI_API_KEY to enable execution.",
"input": ticket_text
}
executor = Executor(llm_cfg, lightweight_mode=True, timeout_seconds=90, debug=False) if "lightweight_mode" in Executor.__init__.__code__.co_varnames else Executor(llm_cfg)
if hasattr(executor, "configure"):
executor.configure(timeout_seconds=90, max_retries=2, enable_metrics=True, debug=False)
wf = Workflow("Single Ticket Run")
s = Node.agent(
name="Summarizer",
agent_id="summarizer",
system_prompt=SYSTEM_POLICY,
prompt=f"Summarize this ticket in 1-2 lines. Return JSON: {{"summary":"..."}}nTicket: {ticket_text}",
temperature=0.2,
max_tokens=200
)
r = Node.agent(
name="RouterAgent",
agent_id="router",
system_prompt=SYSTEM_POLICY,
prompt=(
"You MUST use tools.n"
"Call classify_ticket(text), route_ticket(category, priority), draft_response(category, priority, ticket_text).n"
"Return JSON with fields: category, priority, queue, sla_hours, message.n"
f"Ticket: {ticket_text}"
),
tools=[classify_ticket, route_ticket, draft_response],
temperature=0.1,
max_tokens=700
)
f = Node.agent(
name="FinalFormatter",
agent_id="final_formatter",
system_prompt=SYSTEM_POLICY,
prompt=(
"Validate the JSON and output STRICT JSON only:n"
"{"ticket_id":"...","category":"...","priority":"...","queue":"...","sla_hours":0,"customer_message":"..."}n"
"Input: {input}"
),
temperature=0.0,
max_tokens=500
)
sid = wf.add_node(s)
rid = wf.add_node(r)
fid = wf.add_node(f)
wf.connect(sid, rid)
wf.connect(rid, fid)
wf.validate()
t0 = time.time()
result = executor.execute(wf)
dt_ms = int((time.time() - t0) * 1000)
out = {"mode": "online", "execution_time_ms": dt_ms, "success": bool(result.is_success()) if hasattr(result, "is_success") else None}
if hasattr(result, "get_all_variables"):
out["variables"] = result.get_all_variables()
else:
out["raw"] = str(result)[:3000]
return out
sample = tickets[0]
agent_run = run_agent_flow_once(sample.text)
rprint(Panel.fit(json.dumps(agent_run, indent=2)[:3000], title="Agent Workflow Run"))
rprint(Panel.fit("Done", title="Complete"))We add optional LLM configuration and execution logic that enables the same workflow to run autonomously when a provider key is available. We execute the workflow on a single ticket and capture execution status and outputs. This final step illustrates how the system seamlessly transitions from offline determinism to fully agentic execution.
In conclusion, we implemented a complete GraphBit workflow spanning runtime configuration, tool registration, offline deterministic execution, metric aggregation, and optional agent-based orchestration with external LLM providers. We demonstrated how the same business logic can be executed both manually via tools and automatically via agent nodes connected in a validated graph, highlighting GraphBit’s strength as an execution substrate rather than just an LLM wrapper. We showed that complex agentic systems can be designed to fail gracefully, run without external dependencies, and still scale to fully autonomous workflows when LLMs are enabled.
Check out the . Also, feel free to follow us on and don’t forget to join our and Subscribe to . Wait! are you on telegram?
The post appeared first on .
 December 27, 2025
December 27, 2025In the AI boom, chatbots and GPTs come and go quickly. (Remember Llama?) GPT-5 had a big year, but 2026 will be all about Qwen.
December 26, 2025
Google has released FunctionGemma, a specialized version of the Gemma 3 270M model that is trained specifically for function calling and designed to run as an edge agent that maps natural language to executable API actions.
FunctionGemma is a 270M parameter text only transformer based on Gemma 3 270M. It keeps the same architecture as Gemma 3 and is released as an open model under the Gemma license, but the training objective and chat format are dedicated to function calling rather than free form dialogue.
The model is intended to be fine tuned for specific function calling tasks. It is not positioned as a general chat assistant. The primary design goal is to translate user instructions and tool definitions into structured function calls, then optionally summarize tool responses for the user.
From an interface perspective, FunctionGemma is presented as a standard causal language model. Inputs and outputs are text sequences, with an input context of 32K tokens and an output budget of up to 32K tokens per request, shared with the input length.
The model uses the Gemma 3 transformer architecture and the same 270M parameter scale as Gemma 3 270M. The training and runtime stack reuse the research and infrastructure used for Gemini, including JAX and ML Pathways on large TPU clusters.
FunctionGemma uses Gemma’s 256K vocabulary, which is optimized for JSON structures and multilingual text. This improves token efficiency for function schemas and tool responses and reduces sequence length for edge deployments where latency and memory are tight.
The model is trained on 6T tokens, with a knowledge cutoff in August 2024. The dataset focuses on two main categories:
This training signal teaches both syntax, which function to call and how to format arguments, and intent, when to call a function and when to ask for more information.
FunctionGemma does not use a free form chat format. It expects a strict conversation template that separates roles and tool related regions. Conversation turns are wrapped with <start_of_turn>role ... <end_of_turn> where roles are typically developer, user or model.
Within those turns, FunctionGemma relies on a fixed set of control token pairs
<start_function_declaration> and <end_function_declaration> for tool definitions<start_function_call> and <end_function_call> for the model’s tool calls<start_function_response> and <end_function_response> for serialized tool outputsThese markers let the model distinguish natural language text from function schemas and from execution results. The Hugging Face apply_chat_template API and the official Gemma templates generate this structure automatically for messages and tool lists.
Out of the box, FunctionGemma is already trained for generic tool use. However, the official Mobile Actions guide and the model card emphasize that small models reach production level reliability only after task specific fine tuning.
The Mobile Actions demo uses a dataset where each example exposes a small set of tools for Android system operations, for example create a contact, set a calendar event, control the flashlight and map viewing. FunctionGemma learns to map utterances such as ‘Create a calendar event for lunch tomorrow’ or ‘Turn on the flashlight’ to those tools with structured arguments.
On the Mobile Actions evaluation, the base FunctionGemma model reaches 58 percent accuracy on a held out test set. After fine tuning with the public cookbook recipe, accuracy increases to 85 percent.
The main deployment target for FunctionGemma is edge agents that run locally on phones, laptops and small accelerators such as NVIDIA Jetson Nano. The small parameter count, 0.3B, and support for quantization allow inference with low memory and low latency on consumer hardware.
Google ships several reference experiences through the Google AI Edge Gallery
plant_seed and water_plots with explicit grid coordinates.These demos validate that a 270M parameter function caller can support multi step logic on device without server calls, given appropriate fine tuning and tool interfaces.
<start_of_turn>role ... <end_of_turn> and dedicated control tokens for function declarations, function calls and function responses, which is required for reliable tool use in production systems.Check out the and Also, feel free to follow us on and don’t forget to join our and Subscribe to . Wait! are you on telegram?
The post appeared first on .
December 26, 2025
In this tutorial, we dive into the cutting edge of Agentic AI by building a “Zettelkasten” memory system, a “living” architecture that organizes information much like the human brain. We move beyond standard retrieval methods to construct a dynamic knowledge graph where an agent autonomously decomposes inputs into atomic facts, links them semantically, and even “sleeps” to consolidate memories into higher-order insights. Using Google’s Gemini, we implement a robust solution that addresses real-world API constraints, ensuring our agent stores data and also actively understands the evolving context of our projects. Check out the .
!pip install -q -U google-generativeai networkx pyvis scikit-learn numpy
import os
import json
import uuid
import time
import getpass
import random
import networkx as nx
import numpy as np
import google.generativeai as genai
from dataclasses import dataclass, field
from typing import List
from sklearn.metrics.pairwise import cosine_similarity
from IPython.display import display, HTML
from pyvis.network import Network
from google.api_core import exceptions
def retry_with_backoff(func, *args, **kwargs):
max_retries = 5
base_delay = 5
for attempt in range(max_retries):
try:
return func(*args, **kwargs)
except exceptions.ResourceExhausted:
wait_time = base_delay * (2 ** attempt) + random.uniform(0, 1)
print(f"  Quota limit hit. Cooling down for {wait_time:.1f}s...")
time.sleep(wait_time)
except Exception as e:
if "429" in str(e):
wait_time = base_delay * (2 ** attempt) + random.uniform(0, 1)
print(f" Quota limit hit (HTTP 429). Cooling down for {wait_time:.1f}s...")
time.sleep(wait_time)
else:
print(f"
Quota limit hit. Cooling down for {wait_time:.1f}s...")
time.sleep(wait_time)
except Exception as e:
if "429" in str(e):
wait_time = base_delay * (2 ** attempt) + random.uniform(0, 1)
print(f" Quota limit hit (HTTP 429). Cooling down for {wait_time:.1f}s...")
time.sleep(wait_time)
else:
print(f"  Unexpected Error: {e}")
return None
print("
Unexpected Error: {e}")
return None
print("  Max retries reached.")
return None
print("Enter your Google AI Studio API Key (Input will be hidden):")
API_KEY = getpass.getpass()
genai.configure(api_key=API_KEY)
MODEL_NAME = "gemini-2.5-flash"
EMBEDDING_MODEL = "models/text-embedding-004"
print(f"
Max retries reached.")
return None
print("Enter your Google AI Studio API Key (Input will be hidden):")
API_KEY = getpass.getpass()
genai.configure(api_key=API_KEY)
MODEL_NAME = "gemini-2.5-flash"
EMBEDDING_MODEL = "models/text-embedding-004"
print(f" API Key configured. Using model: {MODEL_NAME}")
API Key configured. Using model: {MODEL_NAME}")We begin by importing essential libraries for graph management and AI model interaction, while also securing our API key input. Crucially, we define a robust retry_with_backoff function that automatically handles rate limit errors, ensuring our agent gracefully pauses and recovers when the API quota is exceeded during heavy processing. Check out the .
@dataclass
class MemoryNode:
id: str
content: str
type: str
embedding: List[float] = field(default_factory=list)
timestamp: int = 0
class RobustZettelkasten:
def __init__(self):
self.graph = nx.Graph()
self.model = genai.GenerativeModel(MODEL_NAME)
self.step_counter = 0
def _get_embedding(self, text):
result = retry_with_backoff(
genai.embed_content,
model=EMBEDDING_MODEL,
content=text
)
return result['embedding'] if result else [0.0] * 768We define the fundamental MemoryNode structure to hold our content, types, and vector embeddings in an organized data class. We then initialize the main RobustZettelkasten class, establishing the network graph and configuring the Gemini embedding model that serves as the backbone of our semantic search capabilities. Check out the .
def _atomize_input(self, text):
prompt = f"""
Break the following text into independent atomic facts.
Output JSON: {{ "facts": ["fact1", "fact2"] }}
Text: "{text}"
"""
response = retry_with_backoff(
self.model.generate_content,
prompt,
generation_config={"response_mime_type": "application/json"}
)
try:
return json.loads(response.text).get("facts", []) if response else [text]
except:
return [text]
def _find_similar_nodes(self, embedding, top_k=3, threshold=0.45):
if not self.graph.nodes: return []
nodes = list(self.graph.nodes(data=True))
embeddings = [n[1]['data'].embedding for n in nodes]
valid_embeddings = [e for e in embeddings if len(e) > 0]
if not valid_embeddings: return []
sims = cosine_similarity([embedding], embeddings)[0]
sorted_indices = np.argsort(sims)[::-1]
results = []
for idx in sorted_indices[:top_k]:
if sims[idx] > threshold:
results.append((nodes[idx][0], sims[idx]))
return results
def add_memory(self, user_input):
self.step_counter += 1
print(f"n [Step {self.step_counter}] Processing: "{user_input}"")
facts = self._atomize_input(user_input)
for fact in facts:
print(f" -> Atom: {fact}")
emb = self._get_embedding(fact)
candidates = self._find_similar_nodes(emb)
node_id = str(uuid.uuid4())[:6]
node = MemoryNode(id=node_id, content=fact, type='fact', embedding=emb, timestamp=self.step_counter)
self.graph.add_node(node_id, data=node, title=fact, label=fact[:15]+"...")
if candidates:
context_str = "n".join([f"ID {c[0]}: {self.graph.nodes[c[0]]['data'].content}" for c in candidates])
prompt = f"""
I am adding: "{fact}"
Existing Memory:
{context_str}
Are any of these directly related? If yes, provide the relationship label.
JSON: {{ "links": [{{ "target_id": "ID", "rel": "label" }}] }}
"""
response = retry_with_backoff(
self.model.generate_content,
prompt,
generation_config={"response_mime_type": "application/json"}
)
if response:
try:
links = json.loads(response.text).get("links", [])
for link in links:
if self.graph.has_node(link['target_id']):
self.graph.add_edge(node_id, link['target_id'], label=link['rel'])
print(f"
[Step {self.step_counter}] Processing: "{user_input}"")
facts = self._atomize_input(user_input)
for fact in facts:
print(f" -> Atom: {fact}")
emb = self._get_embedding(fact)
candidates = self._find_similar_nodes(emb)
node_id = str(uuid.uuid4())[:6]
node = MemoryNode(id=node_id, content=fact, type='fact', embedding=emb, timestamp=self.step_counter)
self.graph.add_node(node_id, data=node, title=fact, label=fact[:15]+"...")
if candidates:
context_str = "n".join([f"ID {c[0]}: {self.graph.nodes[c[0]]['data'].content}" for c in candidates])
prompt = f"""
I am adding: "{fact}"
Existing Memory:
{context_str}
Are any of these directly related? If yes, provide the relationship label.
JSON: {{ "links": [{{ "target_id": "ID", "rel": "label" }}] }}
"""
response = retry_with_backoff(
self.model.generate_content,
prompt,
generation_config={"response_mime_type": "application/json"}
)
if response:
try:
links = json.loads(response.text).get("links", [])
for link in links:
if self.graph.has_node(link['target_id']):
self.graph.add_edge(node_id, link['target_id'], label=link['rel'])
print(f"  Linked to {link['target_id']} ({link['rel']})")
except:
pass
time.sleep(1)
Linked to {link['target_id']} ({link['rel']})")
except:
pass
time.sleep(1)We construct an ingestion pipeline that decomposes complex user inputs into atomic facts to prevent information loss. We immediately embed these facts and use our agent to identify and create semantic links to existing nodes, effectively building a knowledge graph in real time that mimics associative memory. Check out the .
def consolidate_memory(self):
print(f"n [Consolidation Phase] Reflecting...")
high_degree_nodes = [n for n, d in self.graph.degree() if d >= 2]
processed_clusters = set()
for main_node in high_degree_nodes:
neighbors = list(self.graph.neighbors(main_node))
cluster_ids = tuple(sorted([main_node] + neighbors))
if cluster_ids in processed_clusters: continue
processed_clusters.add(cluster_ids)
cluster_content = [self.graph.nodes[n]['data'].content for n in cluster_ids]
prompt = f"""
Generate a single high-level insight summary from these facts.
Facts: {json.dumps(cluster_content)}
JSON: {{ "insight": "Your insight here" }}
"""
response = retry_with_backoff(
self.model.generate_content,
prompt,
generation_config={"response_mime_type": "application/json"}
)
if response:
try:
insight_text = json.loads(response.text).get("insight")
if insight_text:
insight_id = f"INSIGHT-{uuid.uuid4().hex[:4]}"
print(f"
[Consolidation Phase] Reflecting...")
high_degree_nodes = [n for n, d in self.graph.degree() if d >= 2]
processed_clusters = set()
for main_node in high_degree_nodes:
neighbors = list(self.graph.neighbors(main_node))
cluster_ids = tuple(sorted([main_node] + neighbors))
if cluster_ids in processed_clusters: continue
processed_clusters.add(cluster_ids)
cluster_content = [self.graph.nodes[n]['data'].content for n in cluster_ids]
prompt = f"""
Generate a single high-level insight summary from these facts.
Facts: {json.dumps(cluster_content)}
JSON: {{ "insight": "Your insight here" }}
"""
response = retry_with_backoff(
self.model.generate_content,
prompt,
generation_config={"response_mime_type": "application/json"}
)
if response:
try:
insight_text = json.loads(response.text).get("insight")
if insight_text:
insight_id = f"INSIGHT-{uuid.uuid4().hex[:4]}"
print(f"  Insight: {insight_text}")
emb = self._get_embedding(insight_text)
insight_node = MemoryNode(id=insight_id, content=insight_text, type='insight', embedding=emb)
self.graph.add_node(insight_id, data=insight_node, title=f"INSIGHT: {insight_text}", label="INSIGHT", color="#ff7f7f")
self.graph.add_edge(insight_id, main_node, label="abstracted_from")
except:
continue
time.sleep(1)
def answer_query(self, query):
print(f"n
Insight: {insight_text}")
emb = self._get_embedding(insight_text)
insight_node = MemoryNode(id=insight_id, content=insight_text, type='insight', embedding=emb)
self.graph.add_node(insight_id, data=insight_node, title=f"INSIGHT: {insight_text}", label="INSIGHT", color="#ff7f7f")
self.graph.add_edge(insight_id, main_node, label="abstracted_from")
except:
continue
time.sleep(1)
def answer_query(self, query):
print(f"n Querying: "{query}"")
emb = self._get_embedding(query)
candidates = self._find_similar_nodes(emb, top_k=2)
if not candidates:
print("No relevant memory found.")
return
relevant_context = set()
for node_id, score in candidates:
node_content = self.graph.nodes[node_id]['data'].content
relevant_context.add(f"- {node_content} (Direct Match)")
for n1 in self.graph.neighbors(node_id):
rel = self.graph[node_id][n1].get('label', 'related')
content = self.graph.nodes[n1]['data'].content
relevant_context.add(f" - linked via '{rel}' to: {content}")
context_text = "n".join(relevant_context)
prompt = f"""
Answer based ONLY on context.
Question: {query}
Context:
{context_text}
"""
response = retry_with_backoff(self.model.generate_content, prompt)
if response:
print(f"
Querying: "{query}"")
emb = self._get_embedding(query)
candidates = self._find_similar_nodes(emb, top_k=2)
if not candidates:
print("No relevant memory found.")
return
relevant_context = set()
for node_id, score in candidates:
node_content = self.graph.nodes[node_id]['data'].content
relevant_context.add(f"- {node_content} (Direct Match)")
for n1 in self.graph.neighbors(node_id):
rel = self.graph[node_id][n1].get('label', 'related')
content = self.graph.nodes[n1]['data'].content
relevant_context.add(f" - linked via '{rel}' to: {content}")
context_text = "n".join(relevant_context)
prompt = f"""
Answer based ONLY on context.
Question: {query}
Context:
{context_text}
"""
response = retry_with_backoff(self.model.generate_content, prompt)
if response:
print(f" Agent Answer:n{response.text}")
Agent Answer:n{response.text}")We implement the cognitive functions of our agent, enabling it to “sleep” and consolidate dense memory clusters into higher-order insights. We also define the query logic that traverses these connected paths, allowing the agent to reason across multiple hops in the graph to answer complex questions. Check out the .
def show_graph(self):
try:
net = Network(notebook=True, cdn_resources='remote', height="500px", width="100%", bgcolor='#222222', font_color='white')
for n, data in self.graph.nodes(data=True):
color = "#97c2fc" if data['data'].type == 'fact' else "#ff7f7f"
net.add_node(n, label=data.get('label', ''), title=data['data'].content, color=color)
for u, v, data in self.graph.edges(data=True):
net.add_edge(u, v, label=data.get('label', ''))
net.show("memory_graph.html")
display(HTML("memory_graph.html"))
except Exception as e:
print(f"Graph visualization error: {e}")
brain = RobustZettelkasten()
events = [
"The project 'Apollo' aims to build a dashboard for tracking solar panel efficiency.",
"We chose React for the frontend because the team knows it well.",
"The backend must be Python to support the data science libraries.",
"Client called. They are unhappy with React performance on low-end devices.",
"We are switching the frontend to Svelte for better performance."
]
print("--- PHASE 1: INGESTION ---")
for event in events:
brain.add_memory(event)
time.sleep(2)
print("--- PHASE 2: CONSOLIDATION ---")
brain.consolidate_memory()
print("--- PHASE 3: RETRIEVAL ---")
brain.answer_query("What is the current frontend technology for Apollo and why?")
print("--- PHASE 4: VISUALIZATION ---")
brain.show_graph()We wrap up by adding a visualization method that generates an interactive HTML graph of our agent’s memory, allowing us to inspect the nodes and edges. Finally, we execute a test scenario involving a project timeline to verify that our system correctly links concepts, generates insights, and retrieves the right context.
In conclusion, we now have a fully functional “Living Memory” prototype that transcends simple database storage. By enabling our agent to actively link related concepts and reflect on its experiences during a “consolidation” phase, we solve the critical problem of fragmented context in long-running AI interactions. This system demonstrates that true intelligence requires processing power and a structured, evolving memory, marking the way for us to build more capable, personalized autonomous agents.
Check out the . Also, feel free to follow us on and don’t forget to join our and Subscribe to . Wait! are you on telegram?
The post appeared first on .