AlphaFold Changed Science. After 5 Years, It’s Still Evolving
WIRED spoke with DeepMind’s Pushmeet Kohli about the recent past—and promising future—of the Nobel Prize-winning research project that changed biology and chemistry forever.

WIRED spoke with DeepMind’s Pushmeet Kohli about the recent past—and promising future—of the Nobel Prize-winning research project that changed biology and chemistry forever.
 December 24, 2025
December 24, 2025
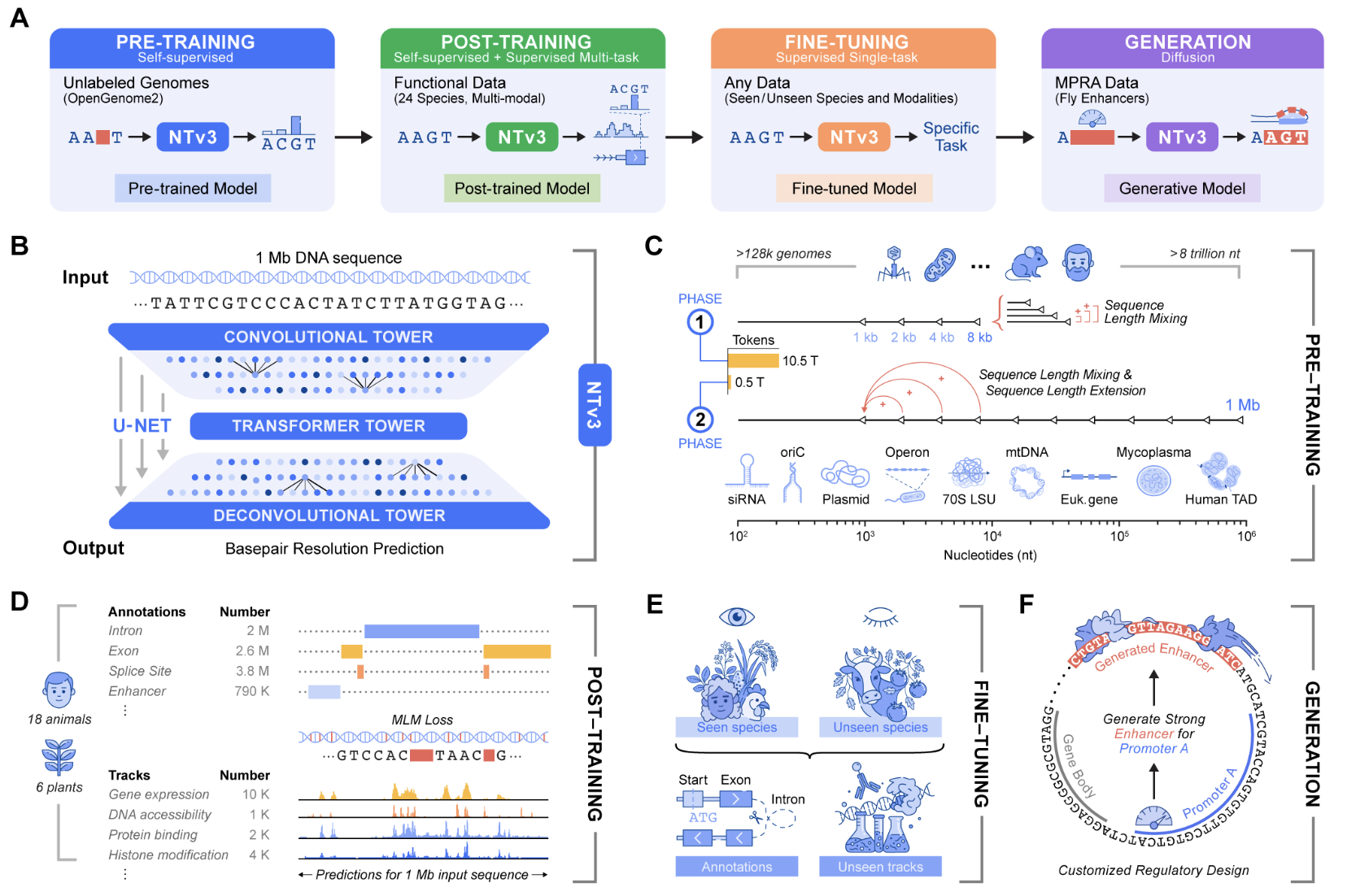
Genomic prediction and design now require models that connect local motifs with megabase scale regulatory context and that operate across many organisms. Nucleotide Transformer v3, or NTv3, is InstaDeep’s new multi species genomics foundation model for this setting. It unifies representation learning, functional track and genome annotation prediction, and controllable sequence generation in a single backbone that runs on 1 Mb contexts at single nucleotide resolution.
Earlier Nucleotide Transformer models already showed that self supervised pretraining on thousands of genomes yields strong features for molecular phenotype prediction. The original series included models from 50M to 2.5B parameters trained on 3,200 human genomes and 850 additional genomes from diverse species. NTv3 keeps this sequence only pretraining idea but extends it to longer contexts and adds explicit functional supervision and a generative mode.
NTv3 uses a U-Net style architecture that targets very long genomic windows. A convolutional downsampling tower compresses the input sequence, a transformer stack models long range dependencies in that compressed space, and a deconvolution tower restores base level resolution for prediction and generation. Inputs are tokenized at the character level over A, T, C, G, N with special tokens such as <unk>, <pad>, <mask>, <cls>, <eos>, and <bos>. Sequence length must be a multiple of 128 tokens, and the reference implementation uses padding to enforce this constraint. All public checkpoints use single base tokenization with a vocabulary size of 11 tokens.
The smallest public model, NTv3 8M pre, has about 7.69M parameters with hidden dimension 256, FFN dimension 1,024, 2 transformer layers, 8 attention heads, and 7 downsample stages. At the high end, NTv3 650M uses hidden dimension 1,536, FFN dimension 6,144, 12 transformer layers, 24 attention heads, and 7 downsample stages, and adds conditioning layers for species specific prediction heads.
The NTv3 model is pretrained on 9 trillion base pairs from the OpenGenome2 resource using base resolution masked language modeling. After this stage, the model is post trained with a joint objective that integrates continued self supervision with supervised learning on approximately 16,000 functional tracks and annotation labels from 24 animal and plant species.
After post training NTv3 achieves state of the art accuracy for functional track prediction and genome annotation across species. It outperforms strong sequence to function models and previous genomic foundation models on existing public benchmarks and on the new Ntv3 Benchmark, which is defined as a controlled downstream fine tuning suite with standardized 32 kb input windows and base resolution outputs.
The Ntv3 Benchmark currently consists of 106 long range, single nucleotide, cross assay, cross species tasks. Because NTv3 sees thousands of tracks across 24 species during post training, the model learns a shared regulatory grammar that transfers between organisms and assays and supports coherent long range genome to function inference.
Beyond prediction, NTv3 can be fine tuned into a controllable generative model via masked diffusion language modeling. In this mode the model receives conditioning signals that encode desired enhancer activity levels and promoter selectivity, and it fills masked spans in the DNA sequence in a way that is consistent with those conditions.
In experiments described in the launch materials, the team designs 1,000 enhancer sequences with specified activity and promoter specificity and validates them in vitro using STARR seq assays in collaboration with the Stark Lab. The results show that these generated enhancers recover the intended ordering of activity levels and reach more than 2 times improved promoter specificity compared with baselines.
Check out the , and . Also, feel free to follow us on and don’t forget to join our and Subscribe to . Wait! are you on telegram?
The post appeared first on .
 December 24, 2025
December 24, 2025
Google Health AI team has released MedASR, an open weights medical speech to text model that targets clinical dictation and physician patient conversations and is designed to plug directly into modern AI workflows.
MedASR is a speech to text model based on the Conformer architecture and is pre trained for medical dictation and transcription. It is positioned as a starting point for developers who want to build healthcare based voice applications such as radiology dictation tools or visit note capture systems.
The model has 105 million parameters and accepts mono channel audio at 16000 hertz with 16 bit integer waveforms. It produces text only output, so it drops directly into downstream natural language processing or generative models such as MedGemma.
MedASR sits inside the Health AI Developer Foundations portfolio, alongside MedGemma, MedSigLIP and other domain specific medical models that share common terms of use and a consistent governance story.
MedASR is trained on a diverse corpus of de identified medical speech. The dataset includes about 5000 hours of physician dictations and clinical conversations across radiology, internal medicine and family medicine.
The training pairs audio segments with transcripts and metadata. Subsets of the conversational data are annotated with medical named entities including symptoms, medications and conditions. This gives the model strong coverage of clinical vocabulary and phrasing patterns that appear in routine documentation.
The model is English only, and most training audio comes from speakers for whom English is a first language and who were raised in the United States. The documentation notes that performance may be lower for other speaker profiles or noisy microphones and recommends fine tuning for such settings.
MedASR follows the Conformer encoder design. Conformer combines convolution blocks with self attention layers so it can capture local acoustic patterns and longer range temporal dependencies in the same stack.
The model is exposed as an automated speech detector with a CTC style interface. In the reference implementation, developers use AutoProcessor to create input features from waveform audio and AutoModelForCTC to produce token sequences. Decoding uses greedy decoding by default. The model can also be paired with an external six gram language model with beam search of size 8 to improve word error rate.
MedASR training uses JAX and ML Pathways on TPUv4p, TPUv5p and TPUv5e hardware. These systems provide the scale needed for large speech models and align with Google’s broader foundation model training stack.
Key results, with greedy decoding and with a six gram language model, are:
A minimal pipeline example is:
from transformers import pipeline
import huggingface_hub
audio = huggingface_hub.hf_hub_download("google/medasr", "test_audio.wav")
pipe = pipeline("automatic-speech-recognition", model="google/medasr")
result = pipe(audio, chunk_length_s=20, stride_length_s=2)
print(result)For more control, developers load AutoProcessor and AutoModelForCTC, resample audio to 16000 hertz with librosa, move tensors to CUDA if available and call model.generate followed by processor.batch_decode.
Check out the , and . Also, feel free to follow us on and don’t forget to join our and Subscribe to . Wait! are you on telegram?
The post appeared first on .
December 23, 2025
In this tutorial, we build a fully functional Pre-Emptive Churn Agent that proactively identifies at-risk users and drafts personalized re-engagement emails before they cancel. Rather than waiting for churn to occur, we design an agentic loop in which we observe user inactivity, analyze behavioral patterns, strategize incentives, and generate human-ready email drafts using Gemini. We orchestrate the entire process step by step, ensuring each component, from data simulation to manager approval, works seamlessly together. Check out the .
import os
import time
import json
import random
from datetime import datetime, timedelta
from typing import List, Dict, Any
import textwrap
try:
import google.generativeai as genai
except ImportError:
!pip install -q -U google-generativeai
import google.generativeai as genai
from google.colab import userdata
import getpassWe set up our environment, import all required libraries, and ensure Gemini is available for use. We keep the initialization minimal so the rest of the system loads cleanly. As we run it, we prepare the foundation for the agent-driven workflow that follows. Check out the .
def setup_gemini():
print("---  Security Check ---")
try:
api_key = userdata.get('GEMINI_API_KEY')
except:
print("Please enter your Google Gemini API Key:")
api_key = getpass.getpass("API Key: ")
if not api_key:
raise ValueError("API Key is required to run the agent.")
genai.configure(api_key=api_key)
return genai.GenerativeModel('gemini-2.5-flash')
class MockCustomerDB:
def __init__(self):
self.today = datetime.now()
self.users = self._generate_mock_users()
def _generate_mock_users(self) -> List[Dict]:
profiles = [
{"id": "U001", "name": "Sarah Connor", "plan": "Enterprise",
"last_login_days_ago": 2, "top_features": ["Reports", "Admin Panel"], "total_spend": 5000},
{"id": "U002", "name": "John Smith", "plan": "Basic",
"last_login_days_ago": 25, "top_features": ["Image Editor"], "total_spend": 50},
{"id": "U003", "name": "Emily Chen", "plan": "Pro",
"last_login_days_ago": 16, "top_features": ["API Access", "Data Export"], "total_spend": 1200},
{"id": "U004", "name": "Marcus Aurelius", "plan": "Enterprise",
"last_login_days_ago": 45, "top_features": ["Team Management"], "total_spend": 8000}
]
return profiles
def fetch_at_risk_users(self, threshold_days=14) -> List[Dict]:
return [u for u in self.users if u['last_login_days_ago'] >= threshold_days]
Security Check ---")
try:
api_key = userdata.get('GEMINI_API_KEY')
except:
print("Please enter your Google Gemini API Key:")
api_key = getpass.getpass("API Key: ")
if not api_key:
raise ValueError("API Key is required to run the agent.")
genai.configure(api_key=api_key)
return genai.GenerativeModel('gemini-2.5-flash')
class MockCustomerDB:
def __init__(self):
self.today = datetime.now()
self.users = self._generate_mock_users()
def _generate_mock_users(self) -> List[Dict]:
profiles = [
{"id": "U001", "name": "Sarah Connor", "plan": "Enterprise",
"last_login_days_ago": 2, "top_features": ["Reports", "Admin Panel"], "total_spend": 5000},
{"id": "U002", "name": "John Smith", "plan": "Basic",
"last_login_days_ago": 25, "top_features": ["Image Editor"], "total_spend": 50},
{"id": "U003", "name": "Emily Chen", "plan": "Pro",
"last_login_days_ago": 16, "top_features": ["API Access", "Data Export"], "total_spend": 1200},
{"id": "U004", "name": "Marcus Aurelius", "plan": "Enterprise",
"last_login_days_ago": 45, "top_features": ["Team Management"], "total_spend": 8000}
]
return profiles
def fetch_at_risk_users(self, threshold_days=14) -> List[Dict]:
return [u for u in self.users if u['last_login_days_ago'] >= threshold_days]We configure authentication for Gemini and construct a mock customer database that behaves like a real system. We simulate users with varying levels of inactivity to generate realistic churn scenarios. Check out the .
class ChurnPreventionAgent:
def __init__(self, model):
self.model = model
def analyze_and_strategize(self, user: Dict) -> Dict:
print(f" ...  Analyzing strategy for {user['name']}...")
prompt = f"""
You are a Customer Success AI Specialist.
Analyze this user profile and determine the best 'Win-Back Strategy'.
USER PROFILE:
- Name: {user['name']}
- Plan: {user['plan']}
- Days Inactive: {user['last_login_days_ago']}
- Favorite Features: {', '.join(user['top_features'])}
- Total Spend: ${user['total_spend']}
TASK:
1. Determine the 'Churn Probability' (Medium/High/Critical).
2. Select a specific INCENTIVE.
3. Explain your reasoning briefly.
OUTPUT FORMAT:
{{
"risk_level": "High",
"incentive_type": "Specific Incentive",
"reasoning": "One sentence explanation."
}}
"""
try:
response = self.model.generate_content(prompt)
clean_json = response.text.replace("```json", "").replace("```", "").strip()
return json.loads(clean_json)
except Exception as e:
return {
"risk_level": "Unknown",
"incentive_type": "General Check-in",
"reasoning": f"Analysis failed: {str(e)}"
}
Analyzing strategy for {user['name']}...")
prompt = f"""
You are a Customer Success AI Specialist.
Analyze this user profile and determine the best 'Win-Back Strategy'.
USER PROFILE:
- Name: {user['name']}
- Plan: {user['plan']}
- Days Inactive: {user['last_login_days_ago']}
- Favorite Features: {', '.join(user['top_features'])}
- Total Spend: ${user['total_spend']}
TASK:
1. Determine the 'Churn Probability' (Medium/High/Critical).
2. Select a specific INCENTIVE.
3. Explain your reasoning briefly.
OUTPUT FORMAT:
{{
"risk_level": "High",
"incentive_type": "Specific Incentive",
"reasoning": "One sentence explanation."
}}
"""
try:
response = self.model.generate_content(prompt)
clean_json = response.text.replace("```json", "").replace("```", "").strip()
return json.loads(clean_json)
except Exception as e:
return {
"risk_level": "Unknown",
"incentive_type": "General Check-in",
"reasoning": f"Analysis failed: {str(e)}"
}We build the analytical core of our churn agent to evaluate user behavior and select win-back strategies. We let Gemini interpret signals, such as inactivity and usage patterns, to determine risk and incentives. Check out the .
def draft_engagement_email(self, user: Dict, strategy: Dict) -> str:
print(f" ...  Drafting email for {user['name']} using '{strategy['incentive_type']}'...")
prompt = f"""
Write a short, empathetic, professional re-engagement email.
TO: {user['name']}
CONTEXT: They haven't logged in for {user['last_login_days_ago']} days.
STRATEGY: {strategy['incentive_type']}
REASONING: {strategy['reasoning']}
USER HISTORY: They love {', '.join(user['top_features'])}.
TONE: Helpful and concise.
"""
response = self.model.generate_content(prompt)
return response.text
Drafting email for {user['name']} using '{strategy['incentive_type']}'...")
prompt = f"""
Write a short, empathetic, professional re-engagement email.
TO: {user['name']}
CONTEXT: They haven't logged in for {user['last_login_days_ago']} days.
STRATEGY: {strategy['incentive_type']}
REASONING: {strategy['reasoning']}
USER HISTORY: They love {', '.join(user['top_features'])}.
TONE: Helpful and concise.
"""
response = self.model.generate_content(prompt)
return response.textWe generate personalized re-engagement emails based on the strategy output from the previous step. We use Gemini to craft concise, empathetic messaging that aligns with each user’s history. Check out the .
class ManagerDashboard:
def review_draft(self, user_name, strategy, draft_text):
print("n" + "="*60)
print(f" REVIEW REQUIRED: Re-engagement for {user_name}")
print(f"
REVIEW REQUIRED: Re-engagement for {user_name}")
print(f" Strategy: {strategy['incentive_type']}")
print(f"
Strategy: {strategy['incentive_type']}")
print(f" Risk Level: {strategy['risk_level']}")
print("-" * 60)
print("
Risk Level: {strategy['risk_level']}")
print("-" * 60)
print(" DRAFT EMAIL:n")
print(textwrap.indent(draft_text, ' '))
print("-" * 60)
print("n[Auto-Simulation] Manager reviewing...")
time.sleep(1.5)
if strategy['risk_level'] == "Critical":
print("
DRAFT EMAIL:n")
print(textwrap.indent(draft_text, ' '))
print("-" * 60)
print("n[Auto-Simulation] Manager reviewing...")
time.sleep(1.5)
if strategy['risk_level'] == "Critical":
print(" MANAGER DECISION: Approved (Priority Send)")
return True
else:
print(" MANAGER DECISION: Approved")
return True
MANAGER DECISION: Approved (Priority Send)")
return True
else:
print(" MANAGER DECISION: Approved")
return TrueWe simulate a manager dashboard where human oversight approves or rejects the drafted email. We keep the flow simple but realistic, ensuring the agent’s actions remain aligned with human judgment. Check out the .
def main():
print("Initializing Agentic System...")
try:
model = setup_gemini()
db = MockCustomerDB()
agent = ChurnPreventionAgent(model)
manager = ManagerDashboard()
except Exception as e:
print(f"Setup failed: {e}")
return
print("n AGENT STATUS: Scanning Database for inactive users (>14 days)...")
at_risk_users = db.fetch_at_risk_users(threshold_days=14)
print(f"Found {len(at_risk_users)} at-risk users.n")
for user in at_risk_users:
print(f"--- Processing Case: {user['id']} ({user['name']}) ---")
strategy = agent.analyze_and_strategize(user)
email_draft = agent.draft_engagement_email(user, strategy)
approved = manager.review_draft(user['name'], strategy, email_draft)
if approved:
print(f"
AGENT STATUS: Scanning Database for inactive users (>14 days)...")
at_risk_users = db.fetch_at_risk_users(threshold_days=14)
print(f"Found {len(at_risk_users)} at-risk users.n")
for user in at_risk_users:
print(f"--- Processing Case: {user['id']} ({user['name']}) ---")
strategy = agent.analyze_and_strategize(user)
email_draft = agent.draft_engagement_email(user, strategy)
approved = manager.review_draft(user['name'], strategy, email_draft)
if approved:
print(f" ACTION: Email queued for sending to {user['name']}.")
else:
print(f"
ACTION: Email queued for sending to {user['name']}.")
else:
print(f" ACTION: Email rejected.")
print("n")
time.sleep(1)
if __name__ == "__main__":
main()
ACTION: Email rejected.")
print("n")
time.sleep(1)
if __name__ == "__main__":
main()We orchestrate the full system: scanning for at-risk users, analyzing them, drafting messages, and routing everything for approval. We bring all components together into one continuous loop.
In conclusion, we have completed a churn-prevention pipeline that observes, reasons, drafts, and involves a human reviewer before action. We watch the agent detect risk patterns, craft tailored strategies, and generate professional emails, all while maintaining human oversight for final decisions. This implementation demonstrates how agentic workflows can transform customer success operations by enabling timely, personalized, and scalable interventions. We now have a modular foundation we can expand further, connecting it to real databases, CRMs, web dashboards, or automation systems, to build a truly production-ready churn prevention engine.
Check out the . Also, feel free to follow us on and don’t forget to join our and Subscribe to . Wait! are you on telegram?
The post appeared first on .
 December 23, 2025
December 23, 2025 December 23, 2025
December 23, 2025 December 23, 2025
December 23, 2025Users of AI image generators are offering each other instructions on how to use the tech to alter pictures of women into realistic, revealing deepfakes.
December 23, 2025
Google DeepMind Researchers introduce Gemma Scope 2, an open suite of interpretability tools that exposes how Gemma 3 language models process and represent information across all layers, from 270M to 27B parameters.
Its core goal is simple, give AI safety and alignment teams a practical way to trace model behavior back to internal features instead of relying only on input output analysis. When a Gemma 3 model jailbreaks, hallucinates or shows sycophantic behavior, Gemma Scope 2 lets researchers inspect which internal features fired and how those activations flowed through the network.
Gemma Scope 2 is a comprehensive, open suite of sparse autoencoders and related tools trained on internal activations of the Gemma 3 model family. Sparse autoencoders, SAEs, act as a microscope on the model. They decompose high dimensional activations into a sparse set of human inspectable features that correspond to concepts or behaviors.
Training Gemma Scope 2 required storing around 110 Petabytes of activation data and fitting over 1 trillion total parameters across all interpretability models.
The suite targets every Gemma 3 variant, including 270M, 1B, 4B, 12B and 27B parameter models, and covers the full depth of the network. This is important because many safety relevant behaviors only appear at larger scales.
The first Gemma Scope release focused on Gemma 2 and already enabled research on model hallucination, identifying secrets known by a model and training safer models.
Gemma Scope 2 extends that work in four main ways:
Check out the , and . Also, feel free to follow us on and don’t forget to join our and Subscribe to . Wait! are you on telegram?
The post appeared first on .
 December 22, 2025
December 22, 2025
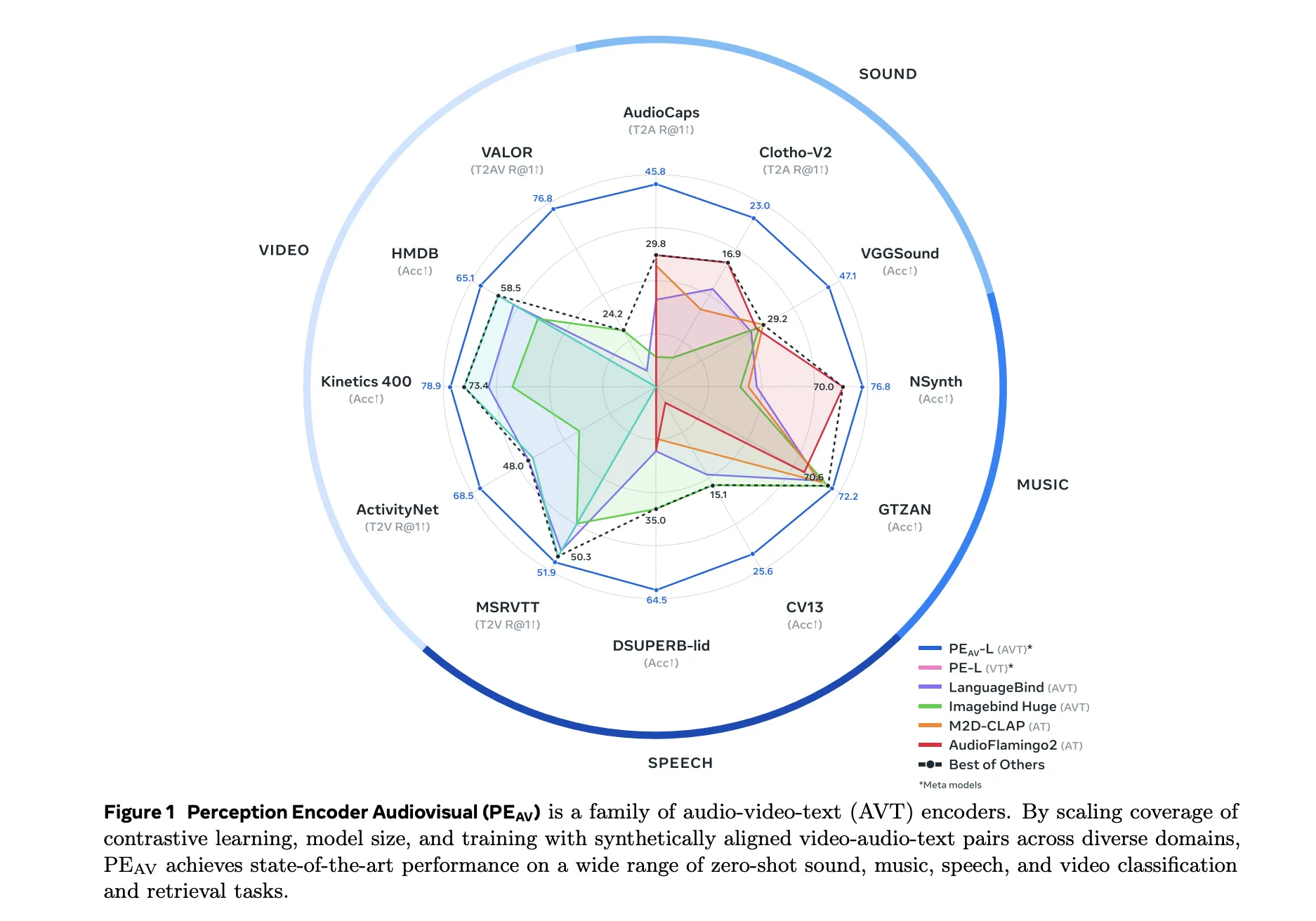
Meta researchers have introduced Perception Encoder Audiovisual, PEAV, as a new family of encoders for joint audio and video understanding. The model learns aligned audio, video, and text representations in a single embedding space using large scale contrastive training on about 100M audio video pairs with text captions.
Perception Encoder, PE, is the core vision stack in Meta’s Perception Models project. It is a family of encoders for images, video, and audio that reaches state of the art on many vision and audio benchmarks using a unified contrastive pretraining recipe. PE core surpasses SigLIP2 on image tasks and InternVideo2 on video tasks. PE lang powers Perception Language Model for multimodal reasoning. PE spatial is tuned for dense prediction tasks such as detection and depth estimation.
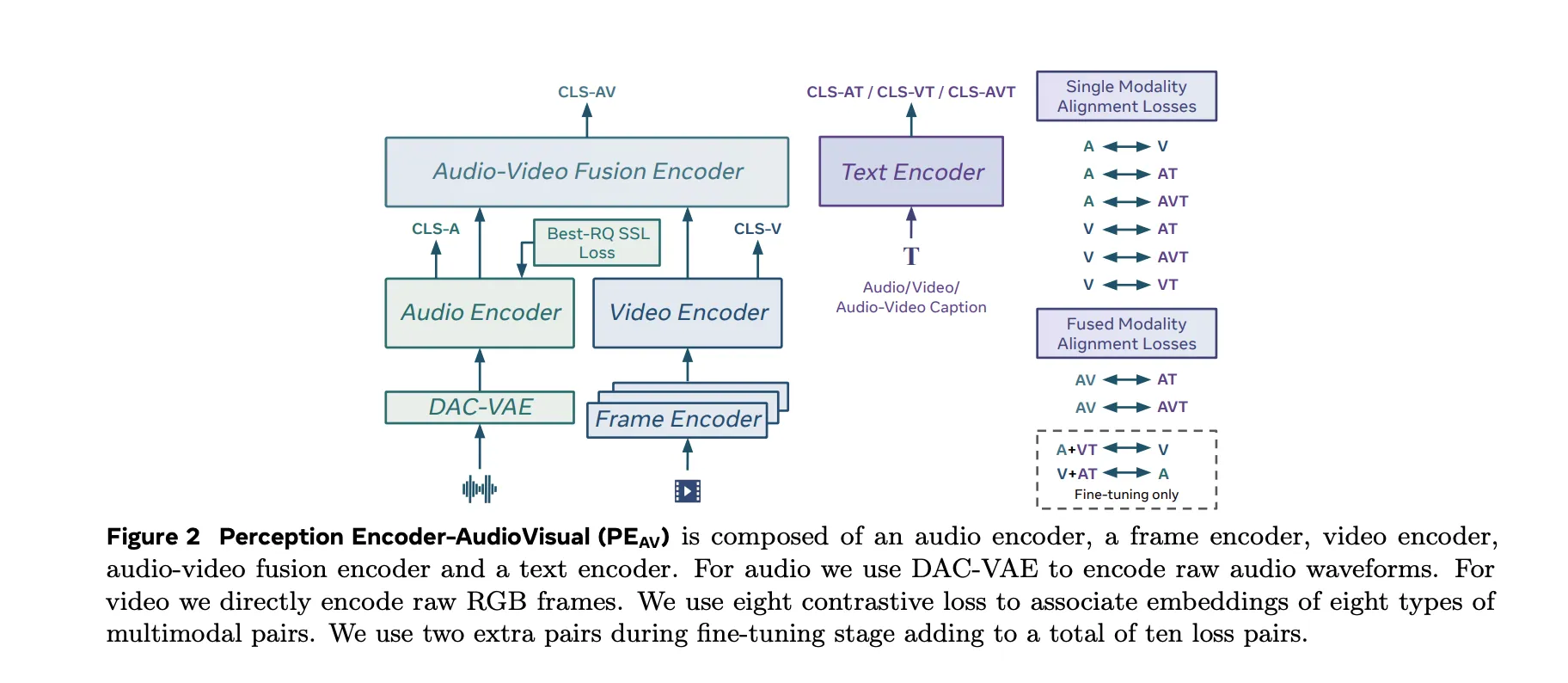
PEAV builds on this backbone and extends it to full audio video text alignment. In the Perception Models repository, PE audio visual is listed as the branch that embeds audio, video, audio video, and text into a single joint embedding space for cross modal understanding.
The PEAV architecture is composed of a frame encoder, a video encoder, an audio encoder, an audio video fusion encoder, and a text encoder.
These towers feed an audio video fusion encoder that learns a shared representation for both streams. The text encoder projects text queries into several specialized spaces. In practice this gives you a single backbone that can be queried in many ways. You can retrieve video from text, audio from text, audio from video, or retrieve text descriptions conditioned on any combination of modalities without retraining task specific heads.
The research team proposed a two stage audiovisual data engine that generates high quality synthetic captions for unlabeled clips. The team describes a pipeline that first uses several weak audio caption models, their confidence scores, and separate video captioners as input to a large language model. This LLM produces three caption types per clip, one for audio content, one for visual content, and one for joint audio visual content. An initial PE AV model is trained on this synthetic supervision.
In the second stage, this initial PEAV is paired with a Perception Language Model decoder. Together they refine the captions to better exploit audiovisual correspondences. The two stage engine yields reliable captions for about 100M audio video pairs and uses about 92M unique clips for stage 1 pretraining and 32M additional unique clips for stage 2 fine tuning.
Compared to prior work that often focuses on speech or narrow sound domains, this corpus is designed to be balanced across speech, general sounds, music, and diverse video domains, which is important for general audio visual retrieval and understanding.
PEAV uses a sigmoid based contrastive loss across audio, video, text, and fused representations. The research team explains that the model uses eight contrastive loss pairs during pretraining. These cover combinations such as audio text, video text, audio video text, and fusion related pairs. During fine tuning, two extra pairs are added, which brings the total to ten loss pairs among the different modality and caption types.
This objective is similar in form to contrastive objectives used in recent vision language encoders but generalized to audio video text tri modal training. By aligning all these views in one space, the same encoder can support classification, retrieval, and correspondence tasks with simple dot product similarities.
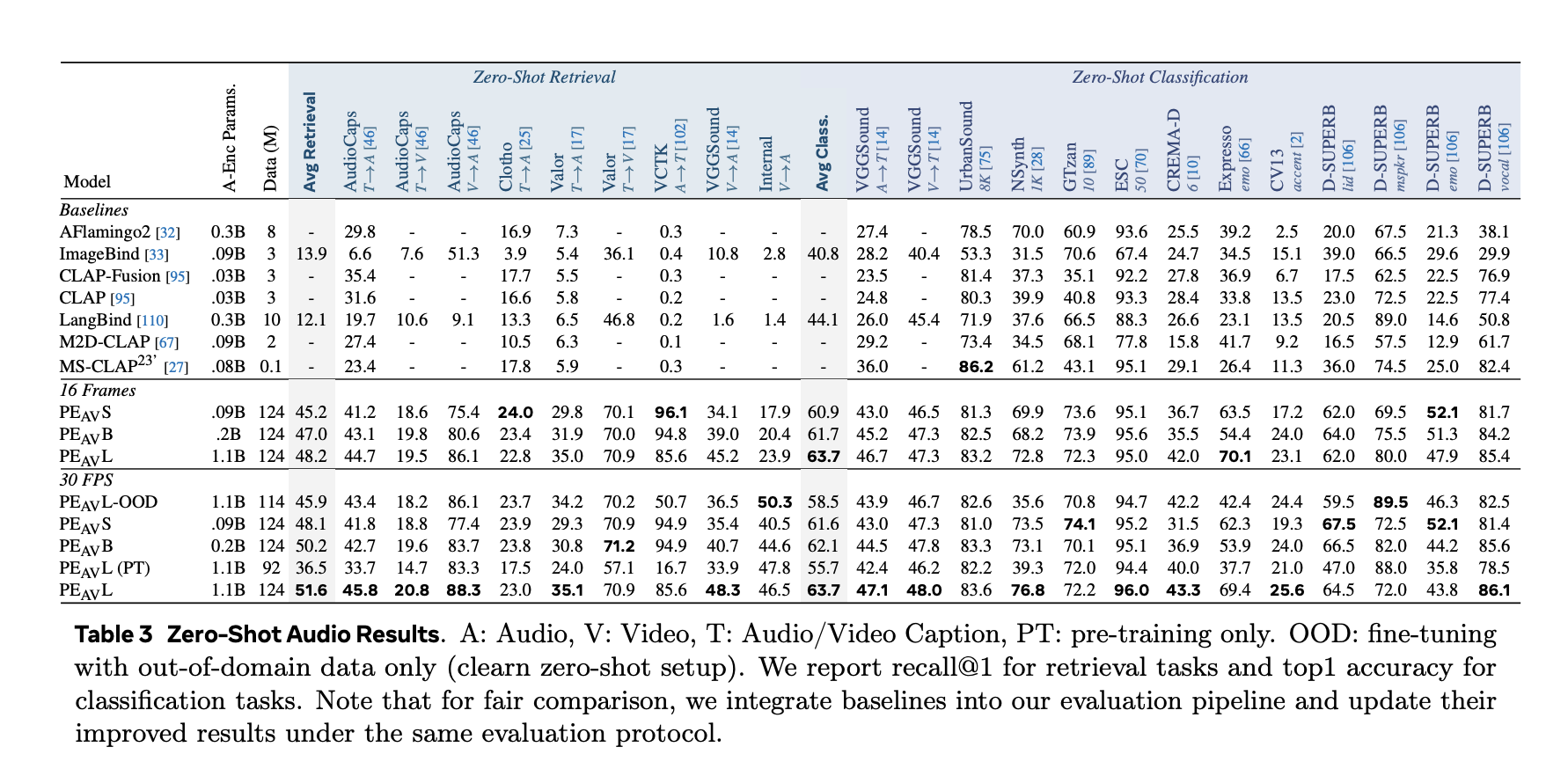
On benchmarks, PEAV targets zero shot retrieval and classification for multiple domains. PE AV achieves state of the art performance on several audio and video benchmarks compared to recent audio text and audio video text models from works such as CLAP, Audio Flamingo, ImageBind, and LanguageBind.
Concrete gains include:
Alongside PEAV, Meta releases Perception Encoder Audio Frame, PEA-Frame, for sound event localization. PE A Frame is an audio text embedding model that outputs one audio embedding per 40 milliseconds frame and a single text embedding per query. The model can return temporal spans that mark where in the audio each described event occurs.
PEA-Frame uses frame level contrastive learning to align audio frames with text. This enables precise localization of events such as specific speakers, instruments, or transient sounds in long audio sequences.
PEAV and PEA-Frame sit inside the broader Perception Models stack, which combines PE encoders with Perception Language Model for multimodal generation and reasoning.
PEAV is also the core perception engine behind Meta’s new SAM Audio model and its Judge evaluator. SAM Audio uses PEAV embeddings to connect visual prompts and text prompts to sound sources in complex mixtures and to score the quality of separated audio tracks.
Check out the , and . Also, feel free to follow us on and don’t forget to join our and Subscribe to . Wait! are you on telegram?
The post appeared first on .



