 August 10, 2025
August 10, 2025Opinion | Trump Is Turning Us Into a Doddering Industrial Giant
Smothering electric vehicles might have been a regrettable mistake for a Republican to make 10 years ago. Today, it is economic idiocy.
Artificial Intelligence
 August 10, 2025
August 10, 2025
Artificial Intelligence
 August 10, 2025
August 10, 2025
Artificial Intelligence
 August 10, 2025
August 10, 2025
The year 2025 marks a defining moment in the evolution of artificial intelligence, ushering in an era where agentic systems—autonomous AI agents capable of complex reasoning and coordinated action—are transforming enterprise workflows, research, software development, and day-to-day user experiences. This articles focuses on five core AI agent trends for 2025: Agentic RAG, Voice Agents, AI Agent Protocols, DeepResearch Agents, Coding Agents, and Computer Using Agents (CUA).
Agentic Retrieval-Augmented Generation (RAG) stands as the cornerstone use case in 2025 for real-world AI agents. Building on the standard RAG architecture, Agentic RAG introduces goal-driven autonomy, memory, and planning. Here’s how the agentic approach refines classical RAG:
Enterprise adoption of Agentic RAG is sweeping across sectors, powering smart assistants, search engines, and collaborative platforms that rely on multi-source data retrieval and reasoning.
Voice-controlled agents are reaching new heights, seamlessly blending speech-to-text (STT) and text-to-speech (TTS) technologies with agentic reasoning pipelines. These agents interact conversationally with users, retrieve data from diverse sources, and even execute tasks such as placing calls or managing calendars—all through spoken language.
With the proliferation of multi-agent systems, open communication protocols are vital. The most prominent ones include:
These protocols are rapidly adopted to enable scalable, interoperable, and secure agentic ecosystems in the enterprise—supporting everything from customer support to supply chain automation.
A new category of agents, DeepResearch Agents, is architected for tackling multi-step research problems. These AI systems aggregate and analyze vast swathes of structured and unstructured information from the web and databases, synthesizing analytical reports and actionable insights.
Business, science, and finance sectors are rapidly integrating DeepResearch architecture, reshaping how teams approach knowledge-intensive work.
Coding Agents are revolutionizing application development, debugging, and testing:
CUA (Computer Using Agents) bridge the gap between human-computer interaction and autonomous interfaces. These agents operate desktop sandboxes, manipulate files and data, and use third-party tools—fully automating tasks as a human would.
The AI agent revolution of 2025 is defined by several key themes:
With ongoing innovations, human oversight remains critical. As agents become more capable, establishing boundaries around agent autonomy—and ensuring transparency and safety—are vital for responsible adoption.
2025’s agentic AI trends is not about single-purpose bots, but sophisticated, task-oriented systems capable of holistic reasoning, collaboration, and learning. These advances are redefining how we work, research, build, and interact with technology—fulfilling the vision set forth in the AI Agent Trends of 2025
Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post AI Agent Trends of 2025: A Transformative Landscape appeared first on MarkTechPost.
MarkTechPost
 August 10, 2025
August 10, 2025
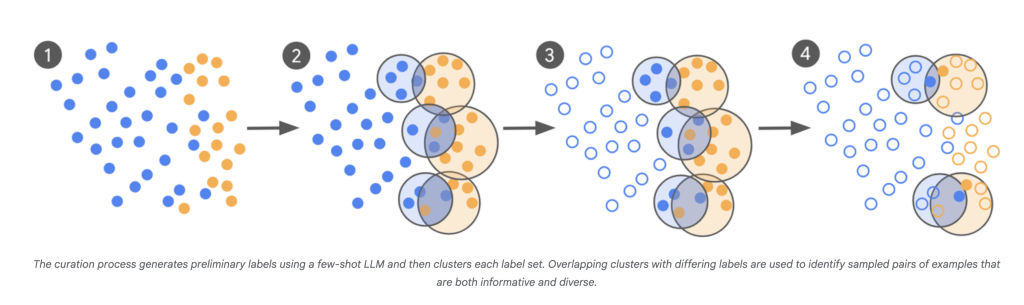
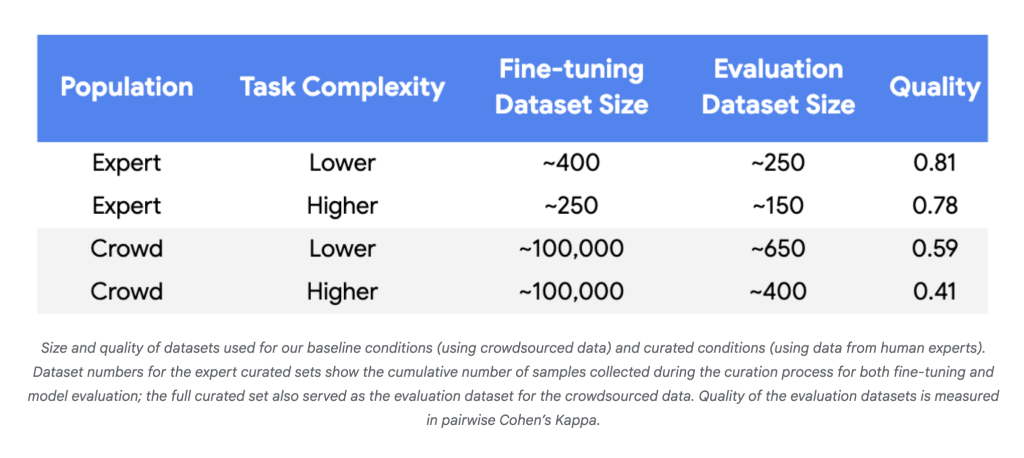
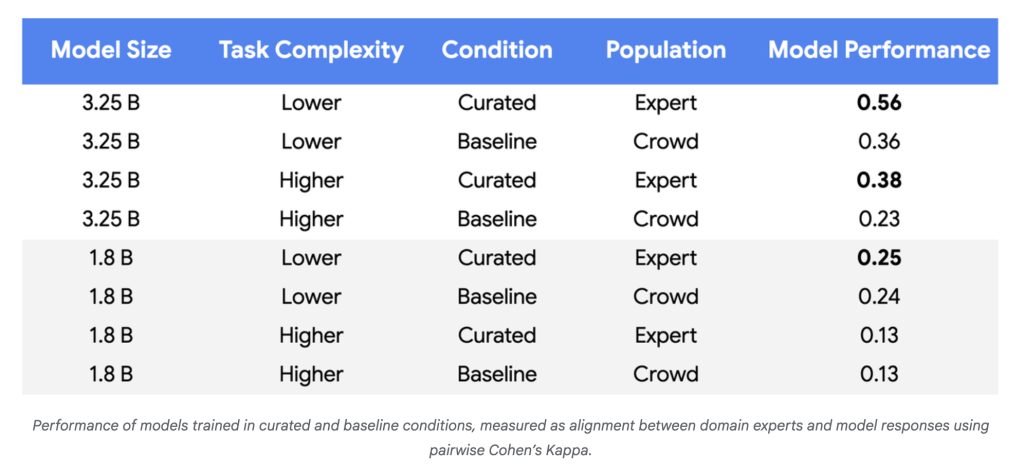
Google Research has unveiled a groundbreaking method for fine-tuning large language models (LLMs) that slashes the amount of required training data by up to 10,000x, while maintaining or even improving model quality. This approach centers on active learning and focusing expert labeling efforts on the most informative examples—the “boundary cases” where model uncertainty peaks.
Fine-tuning LLMs for tasks demanding deep contextual and cultural understanding—like ad content safety or moderation—has typically required massive, high-quality labeled datasets. Most data is benign, meaning that for policy violation detection, only a small fraction of examples matter, driving up the cost and complexity of data curation. Standard methods also struggle to keep up when policies or problematic patterns shift, necessitating expensive retraining.
This approach flips the traditional paradigm. Rather than drowning models in vast pools of noisy, redundant data, it leverages both LLMs’ ability to identify ambiguous cases and the domain expertise of human annotators where their input is most valuable. The benefits are profound:
Google’s new methodology enables LLM fine-tuning on complex, evolving tasks with just hundreds (not hundreds of thousands) of targeted, high-fidelity labels—ushering in far leaner, more agile, and cost-effective model development.
Check out the technical article from Google blog. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post From 100,000 to Under 500 Labels: How Google AI Cuts LLM Training Data by Orders of Magnitude appeared first on MarkTechPost.
MarkTechPost
 August 10, 2025
August 10, 2025
Large Language Models (LLMs) have set new benchmarks in natural language processing, but their tendency for hallucination—generating inaccurate outputs—remains a critical issue for knowledge-intensive applications. Retrieval-Augmented Generation (RAG) frameworks attempt to solve this by incorporating external knowledge into language generation. However, traditional RAG approaches rely on chunk-based retrieval, which limits their ability to represent complex semantic relationships. Entity-relation graph-based RAG methods (GraphRAG) address some structural limitations, but still face high construction cost, one-shot retrieval inflexibility, and dependence on long-context reasoning and carefully crafted prompts.
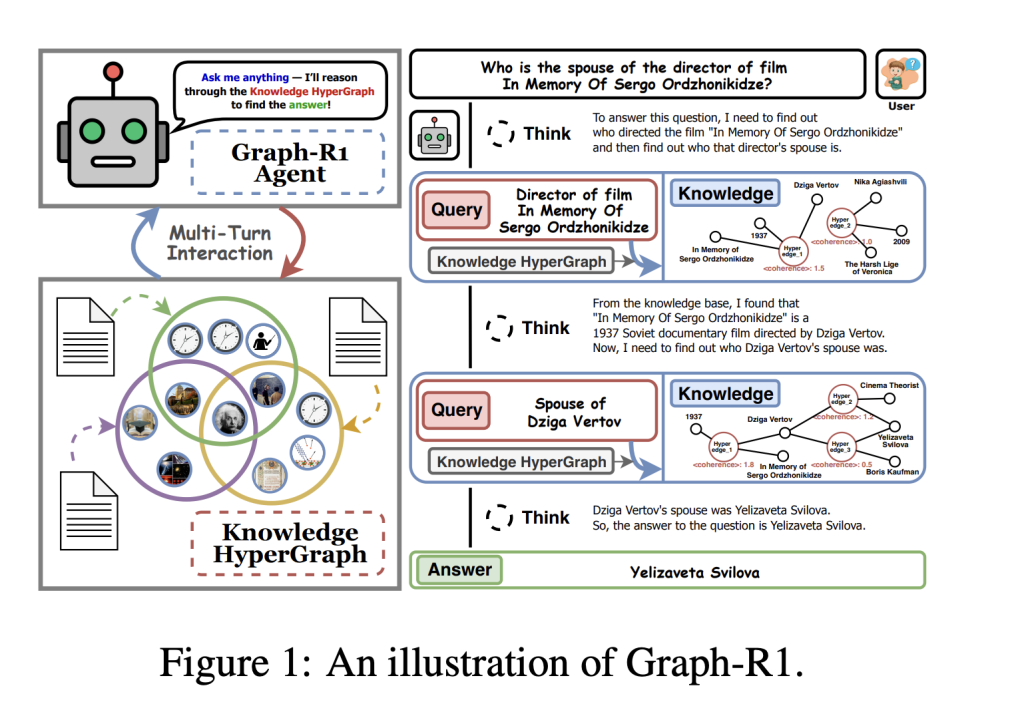
Researchers from Nanyang Technological University, National University of Singapore, Beijing Institute of Computer Technology and Application, and Beijing Anzhen Hospital have introduced Graph-R1, an agentic GraphRAG framework powered by end-to-end reinforcement learning.
Graph-R1 constructs knowledge as a hypergraph, where each knowledge segment is extracted using LLM-driven n-ary relation extraction. This approach encodes richer and more semantically grounded relationships, boosting agentic reasoning capabilities while maintaining manageable cost and computational requirements.
Graph-R1 models retrieval as a multi-turn interaction loop (“think-retrieve-rethink-generate”), allowing the agent to adaptively query and refine its knowledge path, unlike previous methods that use one-shot retrieval.
Graph-R1 uses Group Relative Policy Optimization (GRPO) for end-to-end RL, integrating rewards for format adherence, relevance, and answer correctness. This unified reward guides agents to develop generalizable reasoning strategies tightly aligned with both the knowledge structure and output quality.
Graph-R1 was evaluated across six standard QA datasets (2WikiMultiHopQA, HotpotQA, Musique, Natural Questions, PopQA, TriviaQA).
| Method | Avg. F1 (Qwen2.5-7B) |
|---|---|
| NaiveGeneration | 13.87 |
| StandardRAG | 15.89 |
| GraphRAG | 24.87 |
| HyperGraphRAG | 29.40 |
| Search-R1 | 46.19 |
| R1-Searcher | 42.29 |
| Graph-R1 | 57.82 |
Component ablation demonstrates that removing hypergraph construction, multi-turn reasoning, or RL optimization dramatically reduces performance, validating the necessity of each module within Graph-R1.
Graph-R1’s generation quality is evaluated across seven dimensions—comprehensiveness, knowledgeability, correctness, relevance, diversity, logical coherence, factuality—and consistently outperforms all RL-based and graph-based baselines, achieving top scores in correctness (86.9), relevance (95.2), and coherence (88.5).
Cross-validation on out-of-distribution (O.O.D.) settings reveals that Graph-R1 maintains robust performance across datasets, with O.O.D./I.I.D. ratios often above 85%, demonstrating strong domain generalization properties.
Graph-R1 is supported by information-theoretic analyses:
Graph-R1 demonstrates that integrating hypergraph-based knowledge representation, agentic multi-turn reasoning, and end-to-end RL delivers unprecedented gains in factual QA performance, retrieval efficiency, and generation quality, charting the path for next-generation agentic and knowledge-driven LLM systems.
Graph-R1 introduces an agentic framework where retrieval is modeled as a multi-turn interaction rather than a single one-shot process. Its main innovations are:
Graph-R1 is significantly more efficient and effective in both retrieval and answer generation:
Graph-R1 is ideal for complex knowledge-intensive applications demanding both factual accuracy and reasoning transparency, such as:
Check out the Paper here and GitHub Page. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks.
The post Graph-R1: An Agentic GraphRAG Framework for Structured, Multi-Turn Reasoning with Reinforcement Learning appeared first on MarkTechPost.
MarkTechPost
 August 10, 2025
August 10, 2025
In this tutorial, we walk through building an advanced PaperQA2 AI Agent powered by Google’s Gemini model, designed specifically for scientific literature analysis. We set up the environment in Google Colab/Notebook, configure the Gemini API, and integrate it seamlessly with PaperQA2 to process and query multiple research papers. By the end of the setup, we have an intelligent agent capable of answering complex questions, performing multi-question analyses, and conducting comparative research across papers, all while providing clear answers with evidence from source documents. Check out the Full Codes here.
!pip install paper-qa>=5 google-generativeai requests pypdf2 -q
import os
import asyncio
import tempfile
import requests
from pathlib import Path
from paperqa import Settings, ask, agent_query
from paperqa.settings import AgentSettings
import google.generativeai as genai
GEMINI_API_KEY = "Use Your Own API Key Here"
os.environ["GEMINI_API_KEY"] = GEMINI_API_KEY
genai.configure(api_key=GEMINI_API_KEY)
print(" Gemini API key configured successfully!")
Gemini API key configured successfully!")We begin by installing the required libraries, including PaperQA2 and Google’s Generative AI SDK, and then import the necessary modules for our project. We set our Gemini API key as an environment variable and configure it, ensuring the integration is ready for use. Check out the Full Codes here.
def download_sample_papers():
"""Download sample AI/ML research papers for demonstration"""
papers = {
"attention_is_all_you_need.pdf": "https://arxiv.org/pdf/1706.03762.pdf",
"bert_paper.pdf": "https://arxiv.org/pdf/1810.04805.pdf",
"gpt3_paper.pdf": "https://arxiv.org/pdf/2005.14165.pdf"
}
papers_dir = Path("sample_papers")
papers_dir.mkdir(exist_ok=True)
print(" Downloading sample research papers...")
for filename, url in papers.items():
filepath = papers_dir / filename
if not filepath.exists():
try:
response = requests.get(url, stream=True, timeout=30)
response.raise_for_status()
with open(filepath, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
print(f" Downloaded: {filename}")
except Exception as e:
print(f"
Downloading sample research papers...")
for filename, url in papers.items():
filepath = papers_dir / filename
if not filepath.exists():
try:
response = requests.get(url, stream=True, timeout=30)
response.raise_for_status()
with open(filepath, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
print(f" Downloaded: {filename}")
except Exception as e:
print(f" Failed to download {filename}: {e}")
else:
print(f"
Failed to download {filename}: {e}")
else:
print(f" Already exists: {filename}")
return str(papers_dir)
papers_directory = download_sample_papers()
def create_gemini_settings(paper_dir: str, temperature: float = 0.1):
"""Create optimized settings for PaperQA2 with Gemini models"""
return Settings(
llm="gemini/gemini-1.5-flash",
summary_llm="gemini/gemini-1.5-flash",
agent=AgentSettings(
agent_llm="gemini/gemini-1.5-flash",
search_count=6,
timeout=300.0,
),
embedding="gemini/text-embedding-004",
temperature=temperature,
paper_directory=paper_dir,
answer=dict(
evidence_k=8,
answer_max_sources=4,
evidence_summary_length="about 80 words",
answer_length="about 150 words, but can be longer",
max_concurrent_requests=2,
),
parsing=dict(
chunk_size=4000,
overlap=200,
),
verbosity=1,
)
Already exists: {filename}")
return str(papers_dir)
papers_directory = download_sample_papers()
def create_gemini_settings(paper_dir: str, temperature: float = 0.1):
"""Create optimized settings for PaperQA2 with Gemini models"""
return Settings(
llm="gemini/gemini-1.5-flash",
summary_llm="gemini/gemini-1.5-flash",
agent=AgentSettings(
agent_llm="gemini/gemini-1.5-flash",
search_count=6,
timeout=300.0,
),
embedding="gemini/text-embedding-004",
temperature=temperature,
paper_directory=paper_dir,
answer=dict(
evidence_k=8,
answer_max_sources=4,
evidence_summary_length="about 80 words",
answer_length="about 150 words, but can be longer",
max_concurrent_requests=2,
),
parsing=dict(
chunk_size=4000,
overlap=200,
),
verbosity=1,
)We download a set of well-known AI/ML research papers for our analysis and store them in a dedicated folder. We then create optimized PaperQA2 settings configured to use Gemini for all LLM and embedding tasks, fine-tuning parameters like search count, evidence retrieval, and parsing for efficient and accurate literature processing. Check out the Full Codes here.
class PaperQAAgent:
"""Advanced AI Agent for scientific literature analysis using PaperQA2"""
def __init__(self, papers_directory: str, temperature: float = 0.1):
self.settings = create_gemini_settings(papers_directory, temperature)
self.papers_dir = papers_directory
print(f" PaperQA Agent initialized with papers from: {papers_directory}")
async def ask_question(self, question: str, use_agent: bool = True):
"""Ask a question about the research papers"""
print(f"n
PaperQA Agent initialized with papers from: {papers_directory}")
async def ask_question(self, question: str, use_agent: bool = True):
"""Ask a question about the research papers"""
print(f"n Question: {question}")
print("
Question: {question}")
print(" Searching through research papers...")
try:
if use_agent:
response = await agent_query(query=question, settings=self.settings)
else:
response = ask(question, settings=self.settings)
return response
except Exception as e:
print(f" Error processing question: {e}")
return None
def display_answer(self, response):
"""Display the answer with formatting"""
if response is None:
print(" No response received")
return
print("n" + "="*60)
print("
Searching through research papers...")
try:
if use_agent:
response = await agent_query(query=question, settings=self.settings)
else:
response = ask(question, settings=self.settings)
return response
except Exception as e:
print(f" Error processing question: {e}")
return None
def display_answer(self, response):
"""Display the answer with formatting"""
if response is None:
print(" No response received")
return
print("n" + "="*60)
print(" ANSWER:")
print("="*60)
answer_text = getattr(response, 'answer', str(response))
print(f"n{answer_text}")
contexts = getattr(response, 'contexts', getattr(response, 'context', []))
if contexts:
print("n" + "-"*40)
print("
ANSWER:")
print("="*60)
answer_text = getattr(response, 'answer', str(response))
print(f"n{answer_text}")
contexts = getattr(response, 'contexts', getattr(response, 'context', []))
if contexts:
print("n" + "-"*40)
print(" SOURCES USED:")
print("-"*40)
for i, context in enumerate(contexts[:3], 1):
context_name = getattr(context, 'name', getattr(context, 'doc', f'Source {i}'))
context_text = getattr(context, 'text', getattr(context, 'content', str(context)))
print(f"n{i}. {context_name}")
print(f" Text preview: {context_text[:150]}...")
async def multi_question_analysis(self, questions: list):
"""Analyze multiple questions in sequence"""
results = {}
for i, question in enumerate(questions, 1):
print(f"n
SOURCES USED:")
print("-"*40)
for i, context in enumerate(contexts[:3], 1):
context_name = getattr(context, 'name', getattr(context, 'doc', f'Source {i}'))
context_text = getattr(context, 'text', getattr(context, 'content', str(context)))
print(f"n{i}. {context_name}")
print(f" Text preview: {context_text[:150]}...")
async def multi_question_analysis(self, questions: list):
"""Analyze multiple questions in sequence"""
results = {}
for i, question in enumerate(questions, 1):
print(f"n Processing question {i}/{len(questions)}")
response = await self.ask_question(question)
results = response
if response:
print(f" Completed: {question[:50]}...")
else:
print(f" Failed: {question[:50]}...")
return results
async def comparative_analysis(self, topic: str):
"""Perform comparative analysis across papers"""
questions = [
f"What are the key innovations in {topic}?",
f"What are the limitations of current {topic} approaches?",
f"What future research directions are suggested for {topic}?",
]
print(f"n
Processing question {i}/{len(questions)}")
response = await self.ask_question(question)
results = response
if response:
print(f" Completed: {question[:50]}...")
else:
print(f" Failed: {question[:50]}...")
return results
async def comparative_analysis(self, topic: str):
"""Perform comparative analysis across papers"""
questions = [
f"What are the key innovations in {topic}?",
f"What are the limitations of current {topic} approaches?",
f"What future research directions are suggested for {topic}?",
]
print(f"n Starting comparative analysis on: {topic}")
return await self.multi_question_analysis(questions)
async def basic_demo():
"""Demonstrate basic PaperQA functionality"""
agent = PaperQAAgent(papers_directory)
question = "What is the transformer architecture and why is it important?"
response = await agent.ask_question(question)
agent.display_answer(response)
print("
Starting comparative analysis on: {topic}")
return await self.multi_question_analysis(questions)
async def basic_demo():
"""Demonstrate basic PaperQA functionality"""
agent = PaperQAAgent(papers_directory)
question = "What is the transformer architecture and why is it important?"
response = await agent.ask_question(question)
agent.display_answer(response)
print(" Running basic demonstration...")
await basic_demo()
async def advanced_demo():
"""Demonstrate advanced multi-question analysis"""
agent = PaperQAAgent(papers_directory, temperature=0.2)
questions = [
"How do attention mechanisms work in transformers?",
"What are the computational challenges of large language models?",
"How has pre-training evolved in natural language processing?"
]
print("
Running basic demonstration...")
await basic_demo()
async def advanced_demo():
"""Demonstrate advanced multi-question analysis"""
agent = PaperQAAgent(papers_directory, temperature=0.2)
questions = [
"How do attention mechanisms work in transformers?",
"What are the computational challenges of large language models?",
"How has pre-training evolved in natural language processing?"
]
print(" Running advanced multi-question analysis...")
results = await agent.multi_question_analysis(questions)
for question, response in results.items():
print(f"n{'='*80}")
print(f"Q: {question}")
print('='*80)
if response:
answer_text = getattr(response, 'answer', str(response))
display_text = answer_text[:300] + "..." if len(answer_text) > 300 else answer_text
print(display_text)
else:
print(" No answer available")
print("n Running advanced demonstration...")
await advanced_demo()
async def research_comparison_demo():
"""Demonstrate comparative research analysis"""
agent = PaperQAAgent(papers_directory)
results = await agent.comparative_analysis("attention mechanisms in neural networks")
print("n" + "="*80)
print("
Running advanced multi-question analysis...")
results = await agent.multi_question_analysis(questions)
for question, response in results.items():
print(f"n{'='*80}")
print(f"Q: {question}")
print('='*80)
if response:
answer_text = getattr(response, 'answer', str(response))
display_text = answer_text[:300] + "..." if len(answer_text) > 300 else answer_text
print(display_text)
else:
print(" No answer available")
print("n Running advanced demonstration...")
await advanced_demo()
async def research_comparison_demo():
"""Demonstrate comparative research analysis"""
agent = PaperQAAgent(papers_directory)
results = await agent.comparative_analysis("attention mechanisms in neural networks")
print("n" + "="*80)
print(" COMPARATIVE ANALYSIS RESULTS")
print("="*80)
for question, response in results.items():
print(f"n {question}")
print("-" * 50)
if response:
answer_text = getattr(response, 'answer', str(response))
print(answer_text)
else:
print(" Analysis unavailable")
print()
print(" Running comparative research analysis...")
await research_comparison_demo()
COMPARATIVE ANALYSIS RESULTS")
print("="*80)
for question, response in results.items():
print(f"n {question}")
print("-" * 50)
if response:
answer_text = getattr(response, 'answer', str(response))
print(answer_text)
else:
print(" Analysis unavailable")
print()
print(" Running comparative research analysis...")
await research_comparison_demo()̌We define a PaperQAAgent that uses our Gemini-tuned PaperQA2 settings to search papers, answer questions, and cite sources with clean display helpers. We then run basic, advanced multi-question, and comparative demos so we can interrogate literature end-to-end and summarize findings efficiently. Check out the Full Codes here.
def create_interactive_agent():
"""Create an interactive agent for custom queries"""
agent = PaperQAAgent(papers_directory)
async def query(question: str, show_sources: bool = True):
"""Interactive query function"""
response = await agent.ask_question(question)
if response:
answer_text = getattr(response, 'answer', str(response))
print(f"n Answer:n{answer_text}")
if show_sources:
contexts = getattr(response, 'contexts', getattr(response, 'context', []))
if contexts:
print(f"n Based on {len(contexts)} sources:")
for i, ctx in enumerate(contexts[:3], 1):
ctx_name = getattr(ctx, 'name', getattr(ctx, 'doc', f'Source {i}'))
print(f" {i}. {ctx_name}")
else:
print(" Sorry, I couldn't find an answer to that question.")
return response
return query
interactive_query = create_interactive_agent()
print("n Interactive agent ready! You can now ask custom questions:")
print("Example: await interactive_query('How do transformers handle long sequences?')")
def print_usage_tips():
"""Print helpful usage tips"""
tips = """
USAGE TIPS FOR PAPERQA2 WITH GEMINI:
1.
Interactive agent ready! You can now ask custom questions:")
print("Example: await interactive_query('How do transformers handle long sequences?')")
def print_usage_tips():
"""Print helpful usage tips"""
tips = """
USAGE TIPS FOR PAPERQA2 WITH GEMINI:
1.  Question Formulation:
- Be specific about what you want to know
- Ask about comparisons, mechanisms, or implications
- Use domain-specific terminology
2.
Question Formulation:
- Be specific about what you want to know
- Ask about comparisons, mechanisms, or implications
- Use domain-specific terminology
2.  Model Configuration:
- Gemini 1.5 Flash is free and reliable
- Adjust temperature (0.0-1.0) for creativity vs precision
- Use smaller chunk_size for better processing
3. Document Management:
- Add PDFs to the papers directory
- Use meaningful filenames
- Mix different types of papers for better coverage
4.
Model Configuration:
- Gemini 1.5 Flash is free and reliable
- Adjust temperature (0.0-1.0) for creativity vs precision
- Use smaller chunk_size for better processing
3. Document Management:
- Add PDFs to the papers directory
- Use meaningful filenames
- Mix different types of papers for better coverage
4.  Performance Optimization:
- Limit concurrent requests for free tier
- Use smaller evidence_k values for faster responses
- Cache results by saving the agent state
5. Advanced Usage:
- Chain multiple questions for deeper analysis
- Use comparative analysis for research reviews
- Combine with other tools for complete workflows
Performance Optimization:
- Limit concurrent requests for free tier
- Use smaller evidence_k values for faster responses
- Cache results by saving the agent state
5. Advanced Usage:
- Chain multiple questions for deeper analysis
- Use comparative analysis for research reviews
- Combine with other tools for complete workflows
 Example Questions to Try:
- "Compare the attention mechanisms in BERT vs GPT models"
- "What are the computational bottlenecks in transformer training?"
- "How has pre-training evolved from word2vec to modern LLMs?"
- "What are the key innovations that made transformers successful?"
"""
print(tips)
print_usage_tips()
def save_analysis_results(results: dict, filename: str = "paperqa_analysis.txt"):
"""Save analysis results to a file"""
with open(filename, 'w', encoding='utf-8') as f:
f.write("PaperQA2 Analysis Resultsn")
f.write("=" * 50 + "nn")
for question, response in results.items():
f.write(f"Question: {question}n")
f.write("-" * 30 + "n")
if response:
answer_text = getattr(response, 'answer', str(response))
f.write(f"Answer: {answer_text}n")
contexts = getattr(response, 'contexts', getattr(response, 'context', []))
if contexts:
f.write(f"nSources ({len(contexts)}):n")
for i, ctx in enumerate(contexts, 1):
ctx_name = getattr(ctx, 'name', getattr(ctx, 'doc', f'Source {i}'))
f.write(f" {i}. {ctx_name}n")
else:
f.write("Answer: No response availablen")
f.write("n" + "="*50 + "nn")
print(f"
Example Questions to Try:
- "Compare the attention mechanisms in BERT vs GPT models"
- "What are the computational bottlenecks in transformer training?"
- "How has pre-training evolved from word2vec to modern LLMs?"
- "What are the key innovations that made transformers successful?"
"""
print(tips)
print_usage_tips()
def save_analysis_results(results: dict, filename: str = "paperqa_analysis.txt"):
"""Save analysis results to a file"""
with open(filename, 'w', encoding='utf-8') as f:
f.write("PaperQA2 Analysis Resultsn")
f.write("=" * 50 + "nn")
for question, response in results.items():
f.write(f"Question: {question}n")
f.write("-" * 30 + "n")
if response:
answer_text = getattr(response, 'answer', str(response))
f.write(f"Answer: {answer_text}n")
contexts = getattr(response, 'contexts', getattr(response, 'context', []))
if contexts:
f.write(f"nSources ({len(contexts)}):n")
for i, ctx in enumerate(contexts, 1):
ctx_name = getattr(ctx, 'name', getattr(ctx, 'doc', f'Source {i}'))
f.write(f" {i}. {ctx_name}n")
else:
f.write("Answer: No response availablen")
f.write("n" + "="*50 + "nn")
print(f" Results saved to: {filename}")
print(" Tutorial complete! You now have a fully functional PaperQA2 AI Agent with Gemini.")
Results saved to: {filename}")
print(" Tutorial complete! You now have a fully functional PaperQA2 AI Agent with Gemini.")We create an interactive query helper that allows us to ask custom questions on demand and optionally view cited sources. We also print practical usage tips and add a saver that writes every Q&A with source names to a results file, wrapping up the tutorial with a ready-to-use workflow.
In conclusion, we successfully created a fully functional AI research assistant that leverages the speed and versatility of Gemini with the robust paper processing capabilities of PaperQA2. We can now interactively explore scientific papers, run targeted queries, and even perform in-depth comparative analyses with minimal effort. This setup enhances our ability to digest complex research and also streamlines the entire literature review process, enabling us to focus on insights rather than manual searching.
Check out the Full Codes here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post Building an Advanced PaperQA2 Research Agent with Google Gemini for Scientific Literature Analysis appeared first on MarkTechPost.
MarkTechPost
August 10, 2025
AI agents are at a pivotal moment: simply calling a language model is no longer enough for production-ready solutions. In 2025, intelligent automation depends on orchestrated, agentic workflows—modular coordination blueprints that transform isolated AI calls into systems of autonomous, adaptive, and self-improving agents. Here’s how nine workflow patterns can unlock the next generation of scalable, robust AI agents.
Most failed agent implementations rely on “single-step thinking”—expecting one model call to solve complex, multi-part problems. AI agents succeed when their intelligence is orchestrated across multi-step, parallel, routed, and self-improving workflows. According to Gartner, by 2028, at least 33% of enterprise software will depend on agentic AI, but overcoming the 85% failure rate requires these new paradigms.
Tasks are decomposed into step-by-step subgoals where each LLM’s output becomes the next step’s input. Ideal for complex customer support agents, assistants, and pipelines that require context preservation throughout multi-turn conversations.
Agents autonomously plan multi-step workflows, execute each stage sequentially, review outcomes, and adjust as needed. This adaptive “plan–do–check–act” loop is vital for business process automation and data orchestration, providing resilience against failures and offering granular control over progress.
Splitting a large task into independent sub-tasks for concurrent execution by multiple agents or LLMs. Popular for code review, candidate evaluation, A/B testing, and building guardrails, parallelization drastically reduces time to resolution and improves consensus accuracy.
A central “orchestrator” agent breaks tasks down, assigns work to specialized “workers,” then synthesizes results. This pattern powers retrieval-augmented generation (RAG), coding agents, and sophisticated multi-modal research by leveraging specialization.
Input classification decides which specialized agent should handle each part of a workflow, achieving separation of concerns and dynamic task assignment. This is the backbone of multi-domain customer support and debate systems, where routing enables scalable expertise.
Agents collaborate in a continuous loop: one generates solutions, the other evaluates and suggests improvements. This enables real-time data monitoring, iterative coding, and feedback-driven design—improving quality with every cycle.
Agents self-review their performance after each run, learning from errors, feedback, and changing requirements. Reflection elevates agents from static performers to dynamic learners, essential for long-term automation in data-centric environments, such as app building or regulatory compliance.
Extensions of ReACT allow agents to plan, substitute strategies, and compress workflow logic—reducing computational overhead and aiding fine-tuning, especially in deep search and multi-step Q&A domains.
Agents continuously operate in loops, leveraging tool feedback and environmental signals for perpetual self-improvement. This is at the heart of autonomous evaluations and dynamic guardrail systems, allowing agents to operate reliably with minimal intervention.
Agentic workflows are no longer a future concept—they are the cornerstone of today’s leading AI teams. By mastering these nine patterns, developers and architects can unlock scalable, resilient, and adaptive AI systems that thrive in real-world production. The shift from single-step execution to orchestrated intelligence marks the dawn of enterprise-wide automation, making agentic thinking a required skill for the age of autonomous AI.
Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post 9 Agentic AI Workflow Patterns Transforming AI Agents in 2025 appeared first on MarkTechPost.
MarkTechPost
 August 9, 2025
August 9, 2025
Vibe coding in 2025 has completely changed how we used to build software with advanced large language models (LLMs); anyone can now turn plain-English ideas directly into working code. In this article, we’ve listed the top 50 AI vibe coding tools for everyone in 2025 that can make software creation easier than ever, perfect for beginners launching new projects or pros updating legacy code, and entrepreneurs and product teams for creating minimum viable product (MVPs)—even from your favorite café.
Coined by AI thought leader Andrej Karpathy, “vibe coding” is an innovative way of programming where artificial intelligence (AI) can create functional code by interpreting natural language prompts. Instead of memorizing complex syntax or spending hours debugging, simply describe what you want and let AI do the heavy lifting.
AI vibe coding platforms analyze your requirements and deliver code, which could be a snippet, a full function, or even an entire production-ready application. This approach lowers the barriers to software development, welcoming non-coders and helping experienced developers’ productivity by automating repetitive programming tasks.
Before diving into our comprehensive list, it’s key to recognize what makes the top vibe coding tools stand out:
Selecting the perfect vibe coding tool depends on your individual needs and goals. Here’s a simple framework to help you make the right choice:
Here’s a comprehensive list of the 50 best vibe coding tools available in 2025:
While vibe coding offers many benefits, it also raises important ethical questions that developers should consider:
To get the most out of your vibe coding tools, follow these tips:
AI vibe coding could be more than just a passing trend that could fundamentally change how we approach software development and actually build apps. By reducing the mental effort of coding, these 50 vibe coding tools allow developers to focus on what truly matters: solving real-world problems and creating innovative solutions. Pick the vibe coding tool that meshes with your stack, integrate it thoughtfully, and let the “vibe” translate your next big idea into shipping code.
*Affiliate: We do make a small profit from the sales of this AI product through affiliate marketing. This is not an official list; we have tried to mention as many tools as possible.
AI Tools Club
 August 9, 2025
August 9, 2025
Artificial Intelligence
 August 9, 2025
August 9, 2025
Artificial Intelligence
 Star us on GitHub
Star us on GitHub Join our ML Subreddit
Join our ML Subreddit  Sponsor us
Sponsor us  Discuss on Hacker News
Discuss on Hacker News 