August 9, 2025
August 9, 2025Truth Social’s New AI Chatbot Is Donald Trump’s Media Diet Incarnate
Truth Search AI appears to rely heavily on conservative outlet Fox News to answer even the most basic questions.Feed: Artificial Intelligence Latest
 August 9, 2025
August 9, 2025Truth Search AI appears to rely heavily on conservative outlet Fox News to answer even the most basic questions.Feed: Artificial Intelligence Latest
 August 8, 2025
August 8, 2025On August 14, bring your questions about OpenAI’s latest model, GPT-5, and what it means for the future of chatbots.Feed: Artificial Intelligence Latest
 August 8, 2025
August 8, 2025In this episode of Uncanny Valley, we’re talking about why some chatbot subscriptions are so expensive and how these premium prices were determined on vibes more than anything substantial.Feed: Artificial Intelligence Latest
 August 8, 2025
August 8, 2025
By 2025, 75% of sales teams will rely on AI-native tools. Early adopters are already seeing 20% more revenue with 15% higher conversion rates. The market is racing toward a $37 billion valuation, making 2025 the year AI moves from nice-to-have to must-have.
Why now? AI eliminates the busywork that slows you down. Data entry, prospect research, follow-ups—all handled automatically. You get real-time insights that help close deals faster. Sales reps gain back hours every week, outreach becomes personally relevant at scale, and forecasting accuracy jumps dramatically.
This guide covers ten AI tools driving these results. You’ll see exactly how each platform delivers measurable gains, from route optimization that cuts drive time to email coaching that boosts reply rates. Pricing is included, plus a practical tip you can test immediately with each tool.
Choosing the right AI sales tool comes down to six key factors that separate real results from marketing hype:
Every tool earned its spot by excelling across these pillars. The best AI sales platforms automate data entry, surface predictive insights, and enable conversational AI interactions. Teams using these technologies report productivity gains in the 20-25% range and up to 20% revenue increases.
Category tags like “Best for field sales” or “Best for real-time email coaching” help you skip straight to solutions that solve your biggest pain points. Each tag reflects the primary workflow that tool streamlines—whether that’s route planning, email follow-up, or data enrichment.
Every section includes an implementation tip to help you test value quickly. Try rolling out SPOTIO in one territory or mastering Superhuman shortcuts—these pilot approaches let you benchmark time saved and build a business case before scaling company-wide.
You’re short on time and need to find the right AI tool fast. This table shows you exactly what each platform does best and what it costs.
|
Tool |
Best for category |
Starting price |
Signature AI feature |
|
Superhuman |
Lightning-fast, AI-native email workflow |
$30 per user / month |
Instant reply generation |
|
Grammarly |
Polished, high-impact sales messaging |
Free |
Real-time tone detection |
|
Coda |
Building custom sales workflows & dashboards |
Free |
AI blocks that automate tasks |
|
Apollo.io |
All-in-one sales intelligence & engagement |
Free |
Predictive prospect recommendations |
|
Clay |
Data enrichment & hyper-personalization |
Custom / Contact sales |
Automated firmographic enrichment |
|
HubSpot Sales Hub |
CRM for scaling teams |
Free |
AI predictive forecasting |
|
Gong.io |
Revenue intelligence |
Custom |
AI Composer |
|
InsightSquared |
AI-driven sales forecasting |
Custom / Contact sales |
Machine-learning pipeline scoring |
|
Regie.ai |
Autonomous sales prospecting |
$29 per user / month |
Generative sequence creation |
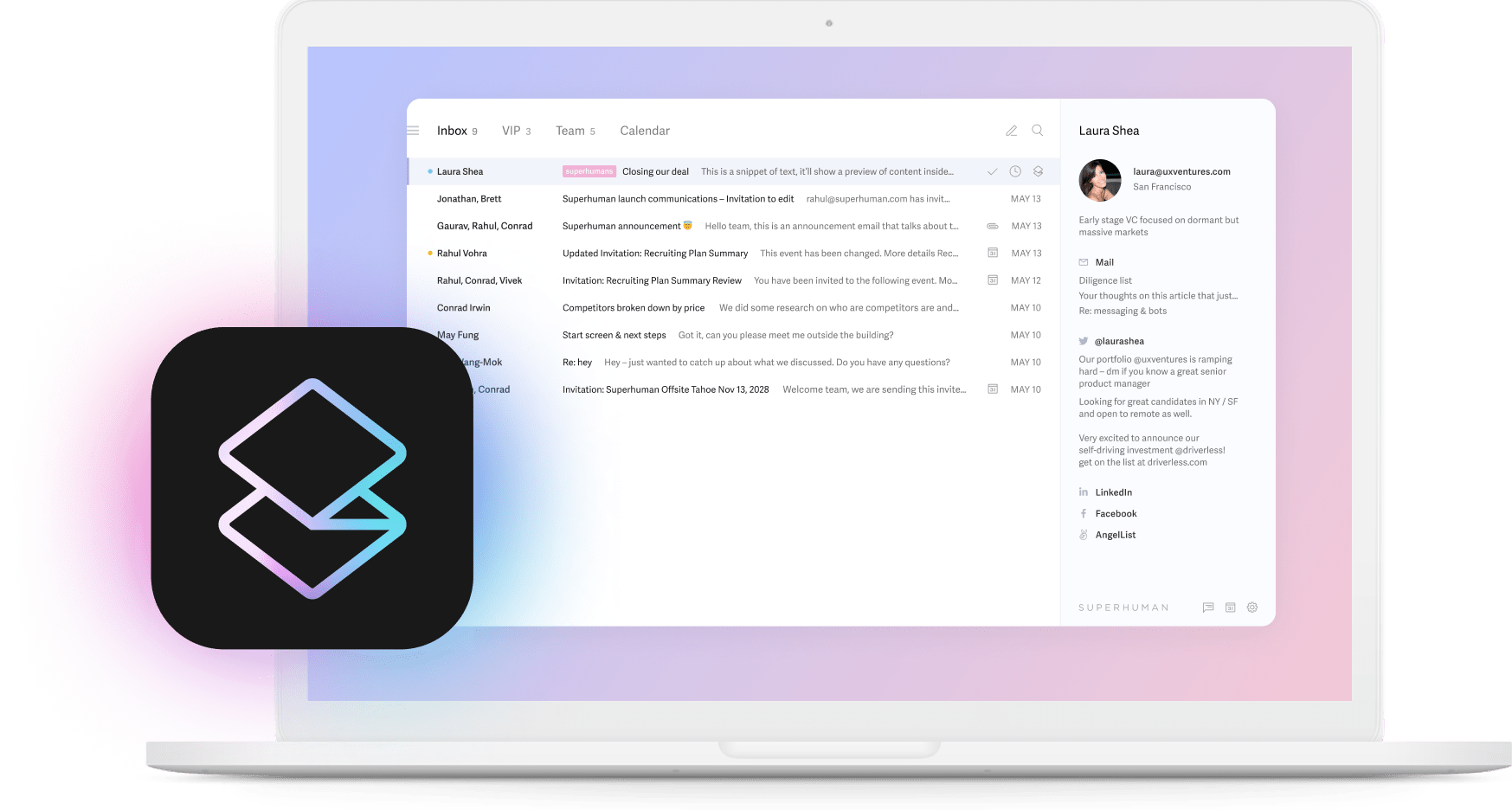
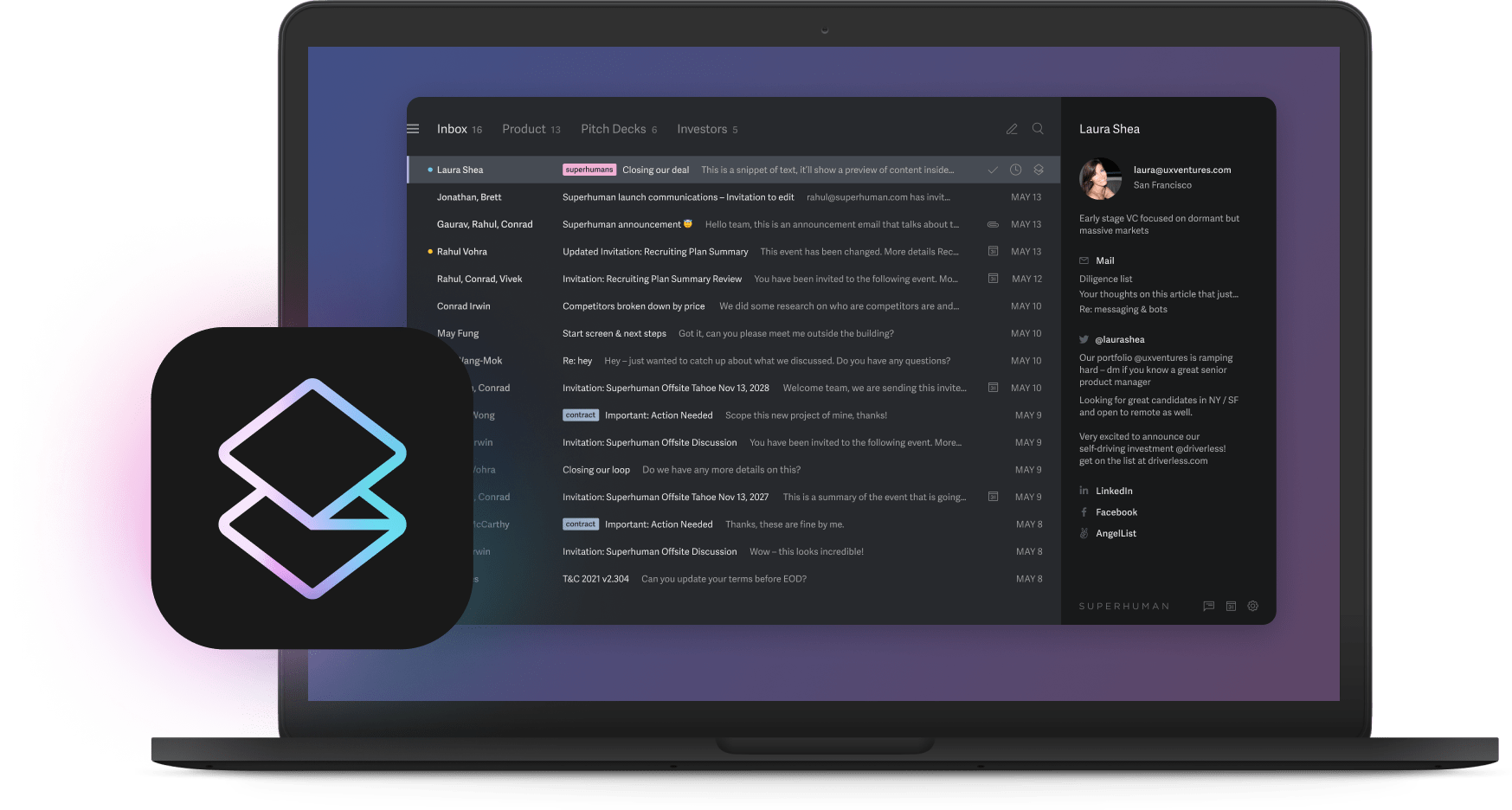
You spend hours triaging email when you could be closing deals. Superhuman turns that bottleneck into a competitive edge, helping teams save 4 hours every week, reply 12 hours faster, and handle twice as many emails in the same time. Your inbox feels lighter, and every follow-up lands sooner.
Superhuman AI kicks in the moment you start drafting. It studies past messages to that contact, mirrors your tone, and suggests a response that sounds like you. You’ll see Instant Reply, which will draft three replies at the bottom of the latest message. You can hit Tab to cycle and preview each response.
Then use Ask AI to surface deal details buried in email conversations. Everything happens inside your inbox, so you never lose momentum switching between tools.
Organizing your email becomes effortless with Split Inbox. Priority conversations like active opportunities and VIP customers float to the top, while noise slips into dedicated sections you can ignore until later. Auto Summarize compresses long threads into a single sentence so you can scan context at a glance, and Auto Reminders nudge you when a prospect hasn’t replied, keeping deals from stalling.
Collaboration moves just as fast with Thread Sharing, allowing you to pull RevOps or legal into a conversation with one click, giving stakeholders full context while you stay in flow. Teams using these features report spending less time in their inboxes, replying to more emails, and experiencing faster response times during pilot programs. Leaders also note shorter deal cycles, attributing this to fewer internal back-and-forths, according to user testimonials and Superhuman’s reports.
Superhuman connects with Salesforce, HubSpot, and popular calendars, enabling automatic email logging, streamlined CRM updates, and integrated scheduling. At $30 per seat per month, it fits into most sales tech budgets without heavy implementation work.
Implementation tip: Book a 45-minute shortcut workshop for your team. Mastering keyboard commands is the fastest route to Inbox Zero, and reps often reclaim a full hour the very first day.
Pros
Cons
Your prospects decide in seconds whether to trust your outreach. Grammarly’s AI tools make those seconds count by catching errors, sharpening language, and flagging tone issues before you hit send.
The platform scans each sentence as you type, highlighting wordiness, passive voice, and off-brand phrasing in real time. Tone detection alerts you when messages sound too formal or not formal enough, while delivery suggestions cut filler that slows readers down. The result? Concise, on-brand copy that keeps prospects engaged.
Grammarly integrates directly into Gmail, Outlook, and LinkedIn so reps never leave their selling screen. Business and Enterprise plans unlock shared style guides—set your preferred terms, tone, and formatting once, and every rep gets inline nudges that enforce brand consistency. This simple switch cuts editing cycles and contributes to improved team productivity.
Pricing stays approachable. Start free with core suggestions, then move to Business at $12 per seat monthly for advanced tone checks, analytics, and the crucial style guide. Enterprise tiers add single sign-on and deeper reporting.
Implementation tip: Draft your style guide before rollout. Define your tone (confident, friendly), ban specific phrases, and set preferred calls to action. Activate the guide on day one so Grammarly enforces it automatically, freeing leaders from constant copy reviews.
Pros
Cons
Grammarly turns polished writing into a competitive edge, giving your team the confidence and consistency to close more deals with fewer edits.
Picture a single doc that thinks like a database, talks to your CRM, and automates half the busywork that keeps you from selling. That’s Coda. By mixing flexible pages with relational tables, it turns scattered spreadsheets, notes, and playbooks into one living workspace that adapts to the way you sell.
The magic starts with Packs, which let you pull real-time opportunity data from Salesforce, sync calendars, or post deal updates to Slack with just a few clicks. Need to tweak the flow? Just drag a column, add a formula, and the entire dashboard updates instantly. When Coda’s AI blocks join the party, meeting notes summarize themselves and surface next-step suggestions, part of the workflow automation trend reshaping sales.
Sales teams use Coda to run live quota dashboards that refresh the moment pipeline data changes, build interactive playbooks so every rep follows the same discovery path and objection handling tips, and track pipeline health in one view that rolls up weighted forecasts, renewal dates, and at-risk deals.
Pricing stays straightforward: the Free plan covers smaller teams, while Pro and Team tiers run about $10–$30 per person each month. Enterprise plans include advanced governance and priority support.
Implementation tip: import a sample of your CRM data first, then set up automations that trigger follow-up tasks, send reminder emails, or update opportunity stages. This quick win shows reps how Coda removes manual data entry and builds momentum for broader adoption.
Pros
Cons
Apollo.io combines prospecting, engagement, and deal intelligence into one AI-native platform. You spend less time hunting for leads and more time closing deals. The platform starts with a 275-million-contact database, then uses algorithms to find companies that match your ideal customer profile. It ranks each prospect by real-time intent signals like website visits, hiring trends, and tech-stack changes, so you know exactly who’s ready to buy.
Once you identify a prospect, Apollo.io tracks every email, call, and meeting. Engagement scores update automatically, giving you live feedback on interest levels without manual data entry. Add automated A/B testing for subject lines and send times, and you get measurable results that contribute to the improved performance many AI-equipped teams report.
Pricing stays reasonable with a free Starter tier covering basic search and outreach. The Growth plan costs $39 per customer monthly and unlocks advanced intent filters, automated sequences, and deeper CRM integrations. Enterprise options scale further with custom enrichment and governance controls.
Implementation tip: turn on buyer-intent filters during week one. Sort prospects by “high intent” and route them to your top closers. Most teams see immediate improvements in close rates after implementing this filter.
Pros
Cons
Apollo.io’s combination of data depth, intent analytics, and automated outreach makes it ideal when you want one platform to find, qualify, and engage the right buyers without juggling multiple tools.
Clay turns scattered prospect data into complete profiles so you can talk to every lead like you’ve known them for years. It automatically pulls company details, tech stacks, funding news, and hiring trends from dozens of sources, then syncs everything to your CRM instantly. No more jumping between LinkedIn, Crunchbase, and half-empty contact records.
This rich data fuels truly personal outreach at scale. Teams using similar data enrichment see improved results because every email references specific pain points and growth signals. Your sequences become conversations, not cold pitches.
Clay uses credit-based pricing, allowing you to buy credits monthly and spend them only when enriching records. Costs scale with your volume, not team size.
Implementation tip: Connect Clay to your email sequencer and map enrichment fields like “recent funding” or “tech stack” directly into email variables. Your sequences update automatically as Clay refreshes data, keeping every touchpoint current.
Pros
Cons
Scaling a sales org brings sprawling pipelines, extra handoffs, and high-stakes forecasting. HubSpot Sales Hub meets that complexity with an AI-native stack that connects your entire revenue operation in one Smart CRM.
Predictive forecasting crunches historical, behavioral, and intent data to project revenue in real time. Deal health signals flag stalled opportunities while AI Playbooks surface next-best actions inside each record, so reps stay focused on deals that can close this quarter. Smart CRM keeps every interaction synced across marketing, service, and finance, ending the copy-and-paste cycle that slows growing teams.
The impact shows up quickly as teams report significant productivity increases and shorter sales cycles after rollout. With most sales organizations expected to use AI tools by 2025, joining that majority now protects pipeline accuracy and frees leaders to coach rather than chase data.
Pricing starts with a free plan for core contact management, then moves to Starter, Professional, and Enterprise tiers as automation, forecasting, and reporting sophistication expand. Each paid tier includes expanded support options and access to a marketplace of native integrations for dialers, quoting apps, and BI platforms. Actual pricing and support offerings may vary; consult HubSpot’s website for current details.
Implementation works best when you begin with HubSpot’s free CRM. Import a single region or business unit first, switch on predictive forecasting, and compare win rates against teams still living in spreadsheets. Early wins build momentum and make the business case for a full upgrade clear.
Pros
Cons
HubSpot Sales Hub turns sprawling processes into one connected motion, giving scaling teams the visibility and precision needed to hit aggressive targets.
Your revenue team makes critical decisions based on incomplete data. Gong changes that entirely by capturing and analyzing every customer interaction (calls, emails, meetings) then surfaces the insights that actually close deals.
The platform’s AI analyzes conversations for buying signals, competitive mentions, and deal risks you’d otherwise miss. It automatically updates your CRM with accurate data from actual conversations, ending the guesswork in pipeline reviews. Sales managers get instant visibility into which deals need attention and why.
Gong’s pricing reflects its enterprise focus: platform fees start at $5,000 annually, plus $1,360-$1,600 per user. Implementation typically takes 3-6 months with professional services ranging from $7,500-$30,000.
Implementation tip: Start with your top-performing team. Use their conversation data to identify winning patterns, then scale those insights across the organization. Most teams see 16% win rate improvements within the first quarter.
Pros
Cons
If you need clear visibility into next quarter’s numbers, InsightSquared delivers. The platform applies machine-learning scoring to every deal, then rolls those scores into dynamic projections you can trust. You gain the confidence to invest, hire, or pivot before it’s too late.
InsightSquared ingests historical performance, activity data, and intent signals to predict pipeline health and quota attainment. As deals progress, the AI model flags slippage risks, recommends next steps, and recalculates the forecast in real time. You move from spreadsheet guesswork to a living forecast that sharpens every time your team sends an email or logs a call.
Pricing is custom, reflecting the depth of analytics and the level of support required. Most teams begin with an initial assessment that maps data sources, business rules, and reporting needs.
Implementation tip: connect InsightSquared directly to your CRM and communication tools so the model trains on clean, up-to-date information. Continuous data sync tightens projections and prevents the “garbage in, garbage out” problem that plagues legacy reporting.
Pros
Cons
With an accurate, always-on forecast, you stop managing by instinct and start steering growth with data. InsightSquared turns every deal update into a sharper prediction, freeing you to focus on strategy instead of spreadsheet gymnastics.
Prospecting eats up your entire day before you know it. Regie.ai changes that completely by drafting, scheduling, and fine-tuning entire outbound sequences for you, learning from every email you send.
The platform pulls your buyer personas, product messaging, and past wins to write multi-touch sequences that sound human. It pushes them straight to your email or sales tool and helps optimize subject lines, calls to action, and send times. Users can adjust and improve messaging, but the system does not automatically rewrite content based on built-in tests.
Pricing for Regie.ai varies by plan and team size. For the most accurate rates, teams should check the official pricing page or contact their sales team. One license can replace hours of manual copywriting and spreadsheet testing.
Implementation tip: Start with at least two subject lines and two email bodies per step. Let Regie.ai run those four versions for two weeks, then keep the winners and try new ideas in the next cycle. This keeps your open and reply rates climbing.
Pros
Cons
Start by identifying what’s actually slowing down your sales process. Are your reps drowning in data entry? Is your forecast accuracy all over the place? Does your outreach sound like it came from a template factory? Once you know your biggest pain points, you can focus on AI tools built to solve those specific problems.
Next, get clear on what success looks like. Companies using AI sales tools typically see significant revenue increases, higher conversion rates, and productivity gains as reps spend less time on busywork. Set your baseline metrics now so you can measure real impact later.
When evaluating tools, focus on five key factors: core AI capability, ease of setup, how well it scales with your team, pricing that makes sense, and whether the company has a solid roadmap for 2025.
Start small with your highest-impact opportunities. Run a four-week pilot with a few reps and track everything. If your forecast accuracy starts hitting the benchmarks that top-performing teams achieve, you’ve found a winner.
Think about integration from day one. Choose platforms that connect natively to your CRM so you don’t create data quality headaches. If your current data is messy, budget time for cleanup first. Clean data creates better AI recommendations.
Your team will only use tools that actually make their lives easier. Look for intuitive interfaces and solid training programs. Find your early adopters who can help coach others through the transition.
Finally, think beyond the sticker price. That “free” tool might get expensive fast as you add users. Conversely, a pricier solution could replace three separate tools and save money overall. Rank your options by impact per dollar spent.
With most sales teams expected to use AI tools by 2025, choosing the right stack today sets you up to outpace the competition tomorrow. Focus on solving your biggest problems first, then build from there.
Even adopting a few of these tools delivers measurable results. Teams using AI report significant improvements in performance, with automated data capture, predictive insights, and personalized content eliminating hours of admin work while accelerating deal cycles. You spend more time on conversations that close deals.
Your next step is straightforward: identify the biggest bottlenecks in your pipeline, match them to the tools designed to solve those specific problems, pilot one or two high-impact solutions, and scale what delivers the fastest results. Save this guide and revisit it each quarter—2025 brings new features, better integrations, and more ways to turn AI into revenue.
Superhuman Blog
 August 8, 2025
August 8, 2025
Artificial Intelligence
 August 8, 2025
August 8, 2025
Contrastive Language-Image Pre-training (CLIP) has become important for modern vision and multimodal models, enabling applications such as zero-shot image classification and serving as vision encoders in MLLMs. However, most CLIP variants, including Meta CLIP, are limited to English-only data curation, ignoring a significant amount of non-English content from the worldwide web. Scaling CLIP to include multilingual data has two challenges: (a) the lack of an efficient method to curate non-English data at scale and (b) the decline of English performance when adding multilingual data, also known as the curse of multilinguality. These issues hinder the development of unified models optimized for both English and non-English tasks.
Methods like OpenAI CLIP and Meta CLIP depend on English-centric curation, and distillation-based approaches introduce biases from external teacher models. SigLIP and SigLIP 2 attempt to utilize data from Google Image Search, but their dependency on proprietary sources limits scalability. Multilingual CLIP models, such as M-CLIP and mCLIP, adopt distillation techniques, using English-only CLIP as a vision encoder and training multilingual text encoders with low-quality data. Moreover, hybrid methods such as SLIP and LiT combine language supervision with self-supervised learning (SSL) for balancing semantic alignment and visual representation. Despite these efforts, none of the methods has resolved the core issues.
Researchers from Meta, MIT, Princeton University, and New York University have proposed Meta CLIP 2, the first method to train CLIP models from scratch using native worldwide image-text pairs without relying on external resources like private data, machine translation, or distillation. It removes the performance trade-offs between English and non-English data by designing and jointly scaling metadata, data curation, model capacity, and training. Meta CLIP 2 maximizes compatibility with OpenAI CLIP’s architecture, ensuring generalizability to CLIP and its variants. Moreover, its recipe introduces three innovations for scaling to worldwide: (a) scalable metadata across 300+ languages, (b) a per-language curation algorithm for balanced concept distribution, and (c) an advanced training framework.

To address the first challenge, researchers used globally curated data, and to tackle the second, they developed a worldwide CLIP training framework. This framework follows OpenAI and Meta CLIP’s training settings and model architecture, including three additions: a multilingual text tokenizer, scaling of seen training pairs, and an analysis of minimal viable model capacity. To ensure generalizability, the training setup uses OpenAI CLIP’s ViT-L/14 and Meta CLIP’s ViT-H/14 models, with modifications for multilingual support. Moreover, studies on the minimal model expressivity reveal that even OpenAI’s ViT-L/14 struggles with the curse due to limited capacity, whereas ViT-H/14 serves as an inflection point, achieving notable gains in both English and non-English tasks.
Meta Clip 2 outperforms its English-only (1.0×) and non-English (1.3×) counterparts in both English and multilingual tasks when trained on ViT-H/14 with worldwide data and scaled seen pairs. However, the curse persists in non-scaled settings or with smaller models like ViT-L/14. Transitioning from English-centric metadata to worldwide equivalents is essential. For example, removing the English filter on alt-texts leads to a 0.6% drop in ImageNet accuracy, highlighting the role of language isolation. Replacing English metadata with merged worldwide metadata initially lowers English performance but boosts multilingual capabilities. Evaluations on zero-shot classification and few-shot geo-localization benchmarks show that scaling from 13B English to 29B worldwide pairs improves results, except for saturated performance in GeoDE.

In conclusion, researchers introduced Meta CLIP 2, the first CLIP model trained from scratch on worldwide image-text pairs. It shows that scaling metadata, curation, and training capacity can break the “curse of multilinguality”, enabling mutual benefits for English and non-English performance. Meta CLIP 2 (ViT-H/14) outperforms its English-only counterpart on zero-shot ImageNet (80.5% → 81.3%) and excels on multilingual benchmarks such as XM3600, Babel-IN, and CVQA with a single unified model. By open-sourcing its metadata, curation methods, and training code, Meta CLIP 2 enables the research community to move beyond English-centric approaches and embrace the potential of the worldwide multimodal web.
Check out the Paper and GitHub Page. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post Meta CLIP 2: The First Contrastive Language-Image Pre-training (CLIP) Trained with Worldwide Image-Text Pairs from Scratch appeared first on MarkTechPost.
MarkTechPost
August 8, 2025
In this tutorial, we begin by showcasing the power of OpenAI Agents as the driving force behind our multi-agent research system. We set up our Colab environment with the OpenAI API key, installed the OpenAI Agents SDK, and then defined custom function tools, web_search, analyze_data, and save_research, to harness the agents’ capabilities. We instantiate three specialized OpenAI Agents (Research Specialist, Data Analyst, and Research Coordinator), each with clear, role-specific instructions and tool access. We demonstrate how these agents collaborate asynchronously and synchronously, maintain session memory for continuity, and allow rapid experimentation through helper functions. Check out the Full Codes here.
!pip install openai-agents python-dotenv
import asyncio
import json
from datetime import datetime
from agents import Agent, Runner, function_tool, SQLiteSession
import os
os.environ['OPENAI_API_KEY'] = 'Use Your Own API Key'We install openai-agents and python-dotenv, then import asyncio, json, datetime, and the core SDK primitives (Agent, Runner, function_tool, SQLiteSession). We set OPENAI_API_KEY in the environment so we can immediately run our agents in this runtime. Check out the Full Codes here.
@function_tool
def web_search(query: str, max_results: int = 3) -> str:
"""Simulate web search results for demonstration"""
results = [
f"Result 1 for '{query}': Latest findings show significant developments...",
f"Result 2 for '{query}': Research indicates new approaches in this field...",
f"Result 3 for '{query}': Expert analysis suggests important implications..."
]
return f"Search results for '{query}':n" + "n".join(results[:max_results])
@function_tool
def analyze_data(data: str, analysis_type: str = "summary") -> str:
"""Analyze provided data with different analysis types"""
analyses = {
"summary": f"Summary: The data contains {len(data.split())} key points with main themes around innovation and efficiency.",
"detailed": f"Detailed Analysis: Breaking down the {len(data)} characters of data reveals patterns in methodology and conclusions.",
"trends": f"Trend Analysis: Current data suggests upward trajectory with 3 major inflection points identified."
}
return analyses.get(analysis_type, "Analysis complete: Standard evaluation performed.")
@function_tool
def save_research(title: str, content: str, category: str = "general") -> str:
"""Save research findings to a structured format"""
timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
research_entry = {
"title": title,
"content": content,
"category": category,
"timestamp": timestamp,
"id": f"research_{len(content) % 1000}"
}
return f" Research saved: '{title}' in category '{category}' at {timestamp}"
Research saved: '{title}' in category '{category}' at {timestamp}"We define three function tools for our agents: web_search simulates quick results, analyze_data returns summary/detailed/trend insights, and save_research stores findings with a timestamped ID. We use them to gather signals, turn text into insights, and persist outputs for later steps. Check out the Full Codes here.
research_agent = Agent(
name="Research Specialist",
instructions="""You are an expert researcher who:
- Conducts thorough web searches on any topic
- Analyzes information critically and objectively
- Identifies key insights and patterns
- Always uses tools to gather and analyze data before responding""",
tools=[web_search, analyze_data]
)
analyst_agent = Agent(
name="Data Analyst",
instructions="""You are a senior data analyst who:
- Takes research findings and performs deep analysis
- Identifies trends, patterns, and actionable insights
- Creates structured summaries and recommendations
- Uses analysis tools to enhance understanding""",
tools=[analyze_data, save_research]
)
coordinator_agent = Agent(
name="Research Coordinator",
instructions="""You are a research coordinator who:
- Manages multi-step research projects
- Delegates tasks to appropriate specialists
- Synthesizes findings from multiple sources
- Makes final decisions on research direction
- Handoff to research_agent for initial data gathering
- Handoff to analyst_agent for detailed analysis""",
handoffs=[research_agent, analyst_agent],
tools=[save_research]
)
We define three OpenAI Agents with clear roles: the Research Specialist gathers and synthesizes information, the Data Analyst deep-dives and saves structured outputs, and the Research Coordinator orchestrates handoffs and final decisions. Together, we delegate, analyze with tools, and produce actionable summaries end-to-end. Check out the Full Codes here.
async def run_advanced_research_workflow():
"""Demonstrates a complete multi-agent research workflow"""
session = SQLiteSession("research_session_001")
print(" Starting Advanced Multi-Agent Research System")
print("=" * 60)
research_topic = "artificial intelligence in healthcare 2024"
print(f"n
Starting Advanced Multi-Agent Research System")
print("=" * 60)
research_topic = "artificial intelligence in healthcare 2024"
print(f"n PHASE 1: Initiating research on '{research_topic}'")
result1 = await Runner.run(
coordinator_agent,
f"I need comprehensive research on '{research_topic}'. Please coordinate a full research workflow including data gathering, analysis, and final report generation.",
session=session
)
print(f"Coordinator Response: {result1.final_output}")
print(f"n
PHASE 1: Initiating research on '{research_topic}'")
result1 = await Runner.run(
coordinator_agent,
f"I need comprehensive research on '{research_topic}'. Please coordinate a full research workflow including data gathering, analysis, and final report generation.",
session=session
)
print(f"Coordinator Response: {result1.final_output}")
print(f"n PHASE 2: Requesting detailed trend analysis")
result2 = await Runner.run(
coordinator_agent,
"Based on the previous research, I need a detailed trend analysis focusing on emerging opportunities and potential challenges. Save the final analysis for future reference.",
session=session
)
print(f"Analysis Response: {result2.final_output}")
print(f"n
PHASE 2: Requesting detailed trend analysis")
result2 = await Runner.run(
coordinator_agent,
"Based on the previous research, I need a detailed trend analysis focusing on emerging opportunities and potential challenges. Save the final analysis for future reference.",
session=session
)
print(f"Analysis Response: {result2.final_output}")
print(f"n PHASE 3: Direct specialist analysis")
result3 = await Runner.run(
analyst_agent,
"Perform a detailed analysis of the healthcare AI market, focusing on regulatory challenges and market opportunities. Categorize this as 'market_analysis'.",
session=session
)
print(f"Specialist Response: {result3.final_output}")
print("n Research workflow completed successfully!")
return result1, result2, result3
async def run_focused_analysis():
"""Shows focused single-agent capabilities"""
print("n
PHASE 3: Direct specialist analysis")
result3 = await Runner.run(
analyst_agent,
"Perform a detailed analysis of the healthcare AI market, focusing on regulatory challenges and market opportunities. Categorize this as 'market_analysis'.",
session=session
)
print(f"Specialist Response: {result3.final_output}")
print("n Research workflow completed successfully!")
return result1, result2, result3
async def run_focused_analysis():
"""Shows focused single-agent capabilities"""
print("n FOCUSED ANALYSIS DEMO")
print("-" * 40)
result = await Runner.run(
research_agent,
"Research in quantum computing and analyze the key breakthroughs from 2024.",
max_turns=5
)
print(f"Focused Analysis Result: {result.final_output}")
return result
def quick_research_sync(topic: str):
"""Synchronous research for quick queries"""
print(f"n
FOCUSED ANALYSIS DEMO")
print("-" * 40)
result = await Runner.run(
research_agent,
"Research in quantum computing and analyze the key breakthroughs from 2024.",
max_turns=5
)
print(f"Focused Analysis Result: {result.final_output}")
return result
def quick_research_sync(topic: str):
"""Synchronous research for quick queries"""
print(f"n QUICK SYNC RESEARCH: {topic}")
print("-" * 40)
result = Runner.run_sync(
research_agent,
f"Quickly research {topic} and provide 3 key insights."
)
print(f"Quick Result: {result.final_output}")
return result
QUICK SYNC RESEARCH: {topic}")
print("-" * 40)
result = Runner.run_sync(
research_agent,
f"Quickly research {topic} and provide 3 key insights."
)
print(f"Quick Result: {result.final_output}")
return resultWe run a full multi-agent workflow with session memory (three phases coordinated by the coordinator and analyst). We perform a focused single-agent analysis with a turn cap, and finally, we trigger a quick synchronous research helper for fast, three-insight summaries. Check out the Full Codes here.
async def main():
"""Main function demonstrating all capabilities"""
print(" OpenAI Agents SDK - Advanced Tutorial")
print("Building a Multi-Agent Research System")
print("=" * 60)
try:
await run_advanced_research_workflow()
await run_focused_analysis()
quick_research_sync("blockchain adoption in enterprise")
print("n
OpenAI Agents SDK - Advanced Tutorial")
print("Building a Multi-Agent Research System")
print("=" * 60)
try:
await run_advanced_research_workflow()
await run_focused_analysis()
quick_research_sync("blockchain adoption in enterprise")
print("n Tutorial completed successfully!")
print("nKey Features Demonstrated:")
print(" Multi-agent coordination with handoffs")
print(" Custom function tools")
print(" Session memory for conversation continuity")
print(" Async and sync execution patterns")
print(" Structured workflows with max_turns control")
print(" Specialized agent roles and capabilities")
except Exception as e:
print(f"
Tutorial completed successfully!")
print("nKey Features Demonstrated:")
print(" Multi-agent coordination with handoffs")
print(" Custom function tools")
print(" Session memory for conversation continuity")
print(" Async and sync execution patterns")
print(" Structured workflows with max_turns control")
print(" Specialized agent roles and capabilities")
except Exception as e:
print(f" Error: {e}")
print("nTroubleshooting tips:")
print("- Ensure OPENAI_API_KEY is set correctly")
print("- Check internet connection")
print("- Verify openai-agents package is installed")
if __name__ == "__main__":
import nest_asyncio
nest_asyncio.apply()
asyncio.run(main())
def create_custom_agent(name: str, role: str, tools_list: list = None):
"""Helper function to create custom agents quickly"""
return Agent(
name=name,
instructions=f"You are a {role} who provides expert assistance.",
tools=tools_list or []
)
custom_agent = create_custom_agent("Code Reviewer", "senior software engineer", [analyze_data])
result = Runner.run_sync(custom_agent, "Review this Python code for best practices")
print("n
Error: {e}")
print("nTroubleshooting tips:")
print("- Ensure OPENAI_API_KEY is set correctly")
print("- Check internet connection")
print("- Verify openai-agents package is installed")
if __name__ == "__main__":
import nest_asyncio
nest_asyncio.apply()
asyncio.run(main())
def create_custom_agent(name: str, role: str, tools_list: list = None):
"""Helper function to create custom agents quickly"""
return Agent(
name=name,
instructions=f"You are a {role} who provides expert assistance.",
tools=tools_list or []
)
custom_agent = create_custom_agent("Code Reviewer", "senior software engineer", [analyze_data])
result = Runner.run_sync(custom_agent, "Review this Python code for best practices")
print("n Tutorial Notes:")
print("- Modify research topics and agent instructions to explore different use cases")
print("- Add your own custom tools using the @function_tool decorator")
print("- Experiment with different agent handoff patterns")
print("- Use sessions for multi-turn conversations")
print("- Perfect for Colab - just add your OpenAI API key and run!")
Tutorial Notes:")
print("- Modify research topics and agent instructions to explore different use cases")
print("- Add your own custom tools using the @function_tool decorator")
print("- Experiment with different agent handoff patterns")
print("- Use sessions for multi-turn conversations")
print("- Perfect for Colab - just add your OpenAI API key and run!")We orchestrate the end-to-end demo with main(), running the multi-agent workflow, a focused analysis, and a quick sync task, while handling errors and logging key features. We also provide a helper to spin up custom agents and show a synchronous “Code Reviewer” example for immediate feedback.
In conclusion, we wrap up the Advanced OpenAI Agents tutorial by highlighting the core strengths of this framework: coordinated multi-agent collaboration, extensible custom tools, persistent session memory, and flexible execution modes. We encourage you to expand on these foundations by adding new tools, crafting custom agent roles, and experimenting with different handoff strategies. We emphasize that this modular architecture empowers you to build sophisticated AI-driven research pipelines with minimal boilerplate.
Check out the Full Codes here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post A Code Implementation to Build a Multi-Agent Research System with OpenAI Agents, Function Tools, Handoffs, and Session Memory appeared first on MarkTechPost.
MarkTechPost
 August 8, 2025
August 8, 2025
Artificial Intelligence
August 8, 2025
We build an advanced LangGraph multi-agent system that leverages Google’s free-tier Gemini model for end-to-end research workflows. In this tutorial, we start by installing the necessary libraries, LangGraph, LangChain-Google-GenAI, and LangChain-Core, then walk through defining a structured state, simulating research and analysis tools, and wiring up three specialized agents: Research, Analysis, and Report. Along the way, we show how to simulate web searches, perform data analysis, and orchestrate messages between agents to produce a polished executive report. Check out the Full Codes here.
!pip install -q langgraph langchain-google-genai langchain-core
import os
from typing import TypedDict, Annotated, List, Dict, Any
from langgraph.graph import StateGraph, END
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.messages import BaseMessage, HumanMessage, AIMessage
import operator
import json
os.environ["GOOGLE_API_KEY"] = "Use Your Own API Key"
class AgentState(TypedDict):
messages: Annotated[List[BaseMessage], operator.add]
current_agent: str
research_data: dict
analysis_complete: bool
final_report: str
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash", temperature=0.7)We install the LangGraph and LangChain-Google-GenAI packages and import the core modules we need to orchestrate our multi-agent workflow. We set our Google API key, define the AgentState TypedDict to structure messages and workflow state, and initialize the Gemini-1.5-Flash model with a 0.7 temperature for balanced responses. Check out the Full Codes here.
def simulate_web_search(query: str) -> str:
"""Simulated web search - replace with real API in production"""
return f"Search results for '{query}': Found relevant information about {query} including recent developments, expert opinions, and statistical data."
def simulate_data_analysis(data: str) -> str:
"""Simulated data analysis tool"""
return f"Analysis complete: Key insights from the data include emerging trends, statistical patterns, and actionable recommendations."
def research_agent(state: AgentState) -> AgentState:
"""Agent that researches a given topic"""
messages = state["messages"]
last_message = messages[-1].content
search_results = simulate_web_search(last_message)
prompt = f"""You are a research agent. Based on the query: "{last_message}"
Here are the search results: {search_results}
Conduct thorough research and gather relevant information. Provide structured findings with:
1. Key facts and data points
2. Current trends and developments
3. Expert opinions and insights
4. Relevant statistics
Be comprehensive and analytical in your research summary."""
response = llm.invoke([HumanMessage(content=prompt)])
research_data = {
"topic": last_message,
"findings": response.content,
"search_results": search_results,
"sources": ["academic_papers", "industry_reports", "expert_analyses"],
"confidence": 0.88,
"timestamp": "2024-research-session"
}
return {
"messages": state["messages"] + [AIMessage(content=f"Research completed on '{last_message}': {response.content}")],
"current_agent": "analysis",
"research_data": research_data,
"analysis_complete": False,
"final_report": ""
}We define simulate_web_search and simulate_data_analysis as placeholder tools that mock retrieving and analyzing information, then implement research_agent to invoke these simulations, prompt Gemini for a structured research summary, and update our workflow state with the findings. We encapsulate the entire research phase in a single function that advances the agent to the analysis stage once the simulated search and structured LLM output are complete. Check out the Full Codes here.
def analysis_agent(state: AgentState) -> AgentState:
"""Agent that analyzes research data and extracts insights"""
research_data = state["research_data"]
analysis_results = simulate_data_analysis(research_data.get('findings', ''))
prompt = f"""You are an analysis agent. Analyze this research data in depth:
Topic: {research_data.get('topic', 'Unknown')}
Research Findings: {research_data.get('findings', 'No findings')}
Analysis Results: {analysis_results}
Provide deep insights including:
1. Pattern identification and trend analysis
2. Comparative analysis with industry standards
3. Risk assessment and opportunities
4. Strategic implications
5. Actionable recommendations with priority levels
Be analytical and provide evidence-based insights."""
response = llm.invoke([HumanMessage(content=prompt)])
return {
"messages": state["messages"] + [AIMessage(content=f"Analysis completed: {response.content}")],
"current_agent": "report",
"research_data": state["research_data"],
"analysis_complete": True,
"final_report": ""
}
def report_agent(state: AgentState) -> AgentState:
"""Agent that generates final comprehensive reports"""
research_data = state["research_data"]
analysis_message = None
for msg in reversed(state["messages"]):
if isinstance(msg, AIMessage) and "Analysis completed:" in msg.content:
analysis_message = msg.content.replace("Analysis completed: ", "")
break
prompt = f"""You are a professional report generation agent. Create a comprehensive executive report based on:
 Research Topic: {research_data.get('topic')}
Research Findings: {research_data.get('findings')}
Research Topic: {research_data.get('topic')}
Research Findings: {research_data.get('findings')}
 Analysis Results: {analysis_message or 'Analysis pending'}
Generate a well-structured, professional report with these sections:
## EXECUTIVE SUMMARY
## KEY RESEARCH FINDINGS
[Detail the most important discoveries and data points]
## ANALYTICAL INSIGHTS
[Present deep analysis, patterns, and trends identified]
## STRATEGIC RECOMMENDATIONS
[Provide actionable recommendations with priority levels]
## RISK ASSESSMENT & OPPORTUNITIES
[Identify potential risks and opportunities]
## CONCLUSION & NEXT STEPS
[Summarize and suggest follow-up actions]
Make the report professional, data-driven, and actionable."""
response = llm.invoke([HumanMessage(content=prompt)])
return {
"messages": state["messages"] + [AIMessage(content=f"
Analysis Results: {analysis_message or 'Analysis pending'}
Generate a well-structured, professional report with these sections:
## EXECUTIVE SUMMARY
## KEY RESEARCH FINDINGS
[Detail the most important discoveries and data points]
## ANALYTICAL INSIGHTS
[Present deep analysis, patterns, and trends identified]
## STRATEGIC RECOMMENDATIONS
[Provide actionable recommendations with priority levels]
## RISK ASSESSMENT & OPPORTUNITIES
[Identify potential risks and opportunities]
## CONCLUSION & NEXT STEPS
[Summarize and suggest follow-up actions]
Make the report professional, data-driven, and actionable."""
response = llm.invoke([HumanMessage(content=prompt)])
return {
"messages": state["messages"] + [AIMessage(content=f" FINAL REPORT GENERATED:nn{response.content}")],
"current_agent": "complete",
"research_data": state["research_data"],
"analysis_complete": True,
"final_report": response.content
}
FINAL REPORT GENERATED:nn{response.content}")],
"current_agent": "complete",
"research_data": state["research_data"],
"analysis_complete": True,
"final_report": response.content
}We implement analysis_agent to take the simulated research findings, run them through our mock data analysis tool, prompt Gemini to produce in-depth insights and strategic recommendations, then transition the workflow to the report stage. We built report_agent to extract the latest analysis and craft a structured executive report via Gemini, with sections ranging from summary to next steps. We then mark the workflow as complete by storing the final report in the state. Check out the Full Codes here.
def should_continue(state: AgentState) -> str:
"""Determine which agent should run next based on current state"""
current_agent = state.get("current_agent", "research")
if current_agent == "research":
return "analysis"
elif current_agent == "analysis":
return "report"
elif current_agent == "report":
return END
else:
return END
workflow = StateGraph(AgentState)
workflow.add_node("research", research_agent)
workflow.add_node("analysis", analysis_agent)
workflow.add_node("report", report_agent)
workflow.add_conditional_edges(
"research",
should_continue,
{"analysis": "analysis", END: END}
)
workflow.add_conditional_edges(
"analysis",
should_continue,
{"report": "report", END: END}
)
workflow.add_conditional_edges(
"report",
should_continue,
{END: END}
)
workflow.set_entry_point("research")
app = workflow.compile()
def run_research_assistant(query: str):
"""Run the complete research workflow"""
initial_state = {
"messages": [HumanMessage(content=query)],
"current_agent": "research",
"research_data": {},
"analysis_complete": False,
"final_report": ""
}
print(f" Starting Multi-Agent Research on: '{query}'")
print("=" * 60)
current_state = initial_state
print(" Research Agent: Gathering information...")
current_state = research_agent(current_state)
print(" Research phase completed!n")
print(" Analysis Agent: Analyzing findings...")
current_state = analysis_agent(current_state)
print(" Analysis phase completed!n")
print(" Report Agent: Generating comprehensive report...")
final_state = report_agent(current_state)
print(" Report generation completed!n")
print("=" * 60)
print(" MULTI-AGENT WORKFLOW COMPLETED SUCCESSFULLY!")
print("=" * 60)
final_report = final_state['final_report']
print(f"n COMPREHENSIVE RESEARCH REPORT:n")
print(final_report)
return final_stateWe construct a StateGraph, add our three agents as nodes with conditional edges dictated by should_continue, set the entry point to “research,” and compile the graph into an executable workflow. We then define run_research_assistant() to initialize the state, sequentially invoke each agent, research, analysis, and report, print status updates, and return the final report. Check out the Full Codes here.
if __name__ == "__main__":
print(" Advanced LangGraph Multi-Agent System Ready!")
print(" Remember to set your GOOGLE_API_KEY!")
example_queries = [
"Impact of renewable energy on global markets",
"Future of remote work post-pandemic"
]
print(f"n
Remember to set your GOOGLE_API_KEY!")
example_queries = [
"Impact of renewable energy on global markets",
"Future of remote work post-pandemic"
]
print(f"n Example queries you can try:")
for i, query in enumerate(example_queries, 1):
print(f" {i}. {query}")
print(f"n Usage: run_research_assistant('Your research question here')")
result = run_research_assistant("What are emerging trends in sustainable technology?")
Example queries you can try:")
for i, query in enumerate(example_queries, 1):
print(f" {i}. {query}")
print(f"n Usage: run_research_assistant('Your research question here')")
result = run_research_assistant("What are emerging trends in sustainable technology?")We define the entry point that kicks off our multi-agent system, displaying a readiness message, example queries, and reminding us to set the Google API key. We showcase sample prompts to demonstrate how to interact with the research assistant and then execute a test run on “emerging trends in sustainable technology,” printing the end-to-end workflow output.
In conclusion, we reflect on how this modular setup empowers us to rapidly prototype complex workflows. Each agent encapsulates a distinct phase of intelligence gathering, interpretation, and delivery, allowing us to swap in real APIs or extend the pipeline with new tools as our needs evolve. We encourage you to experiment with custom tools, adjust the state structure, and explore alternate LLMs. This framework is designed to grow with your research and product goals. As we iterate, we continually refine our agents’ prompts and capabilities, ensuring that our multi-agent system remains both robust and adaptable to any domain.
Check out the Full Codes here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post A Coding Implementation to Advanced LangGraph Multi-Agent Research Pipeline for Automated Insights Generation appeared first on MarkTechPost.
MarkTechPost
 August 8, 2025
August 8, 2025
OpenAI has officially launched GPT-5, and it is better than we expected. OpenAI’s long-anticipated GPT-5 is no longer a rumor; it’s live on ChatGPT for everyone (yes, even the free users) and on the API for developers. GPT-5 is called the company’s smartest, fastest, and most useful model yet, with built-in thinking. The AI model comes with sharper reasoning, a bigger memory, and a clear push toward agent-style autonomy, all while staying accessible to everyday users.
Unlike last year’s GPT-4o, which wowed with real-time voice, GPT-5 focuses on doing deeper work with fewer hints. Microsoft switched Copilot’s new “smart mode“ to GPT-5 within hours of launch, letting the assistant dynamically pick the right model for quick chats, dense legal questions, or end-to-end coding jobs. GitHub Copilot users on paid plans can toggle GPT-5 today, and the model is rolling into Azure AI Foundry for developers who want to mix and match models behind the scenes.
OpenAI’s new model, GPT-5, introduces a suite of enhancements that could change user experience, designed to be more intelligent, safer, and personalized.


OpenAI also rolled out updates to ChatGPT, now powered by GPT-5:

Enterprise users get new toys too. GPT-5 powers higher-quality work by connecting with your company’s files and apps like Google Drive, SharePoint, and more, while keeping data secure through existing permissions. It’s being rolled out on the ChatGPT Team right away, with ChatGPT Enterprise and Edu getting access later in August.
GPT-5 isn’t just faster and smarter; it is more like a collaborative and integrated partner that can help you write more human-like emails, debug code, and look for strategic business advice. GPT-5 with its advanced reasoning, personalization, and safety features, is more useful, reliable, and accessible to everyone. Once we have access to the new AI model, we can test it ourselves and find out just how much more human-like and genuinely helpful AI can become.
AI Tools Club