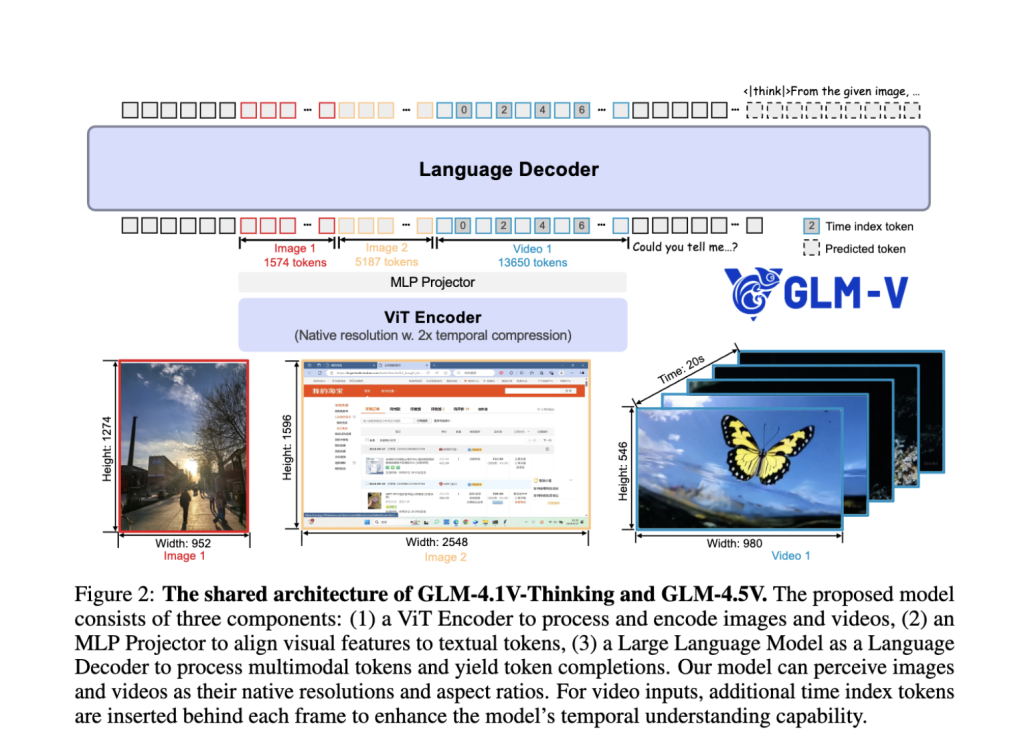
GPT-5 is OpenAI’s latest and most powerful AI large language model (LLM) to date. The company calls it the smartest, fastest, most useful model yet, with built-in thinking and PhD‑level intelligence. When an AI model is truly capable, its effectiveness depends on how users use it in their everyday tasks and how well they take advantage of its intelligence. One of the best ways to use an artificial intelligence (AI) model efficiently is by writing effective prompts that AI can understand rather than get hallucinated by.
Thankfully, to help you get the best out of the latest GPT-5 model, OpenAI has released a GPT-5 Prompting Guide. The cookbook is a practical prompt engineering guide by OpenAI for the latest GPT-5 model to help you get the best results.
This guide will help you get a more predictable, more useful AI that can plan work, follow instructions precisely, and ship clean code without drama. The model is more proactive than older systems, so the guide leans into controls that help you decide when GPT-5 should go on its own and when it should slow down and ask.
A Smarter, More Capable AI
So, what makes GPT-5 such a game-changer? It’s not just about being able to answer more questions or write longer blocks of text. The improvements are far more profound. One of the most significant advancements is the massive reduction in “hallucinations,” the term for when an AI generates false or misleading information. This means we can trust the answers we get from GPT-5 to a much greater degree, making it a more reliable tool for everything from research to creative writing.
What’s actually new—and why it matters
We always hear companies make claims, so what’s actually new and why does that matter?
Agentic control without chaos
GPT-5 can operate anywhere on the spectrum from tightly scripted helper to independent problem-solver. The guide shows how to dial “agentic eagerness” up or down.
For example: Reduce exploration with a lower reasoning_effort, or push persistence with prompts that tell the model to keep going until the task is truly done. That makes long, tool-heavy workflows feel less random and more repeatable.
Clearly defining criteria in your prompt for how you want the AI model to explore the problem space can reduce the model’s need to explore and reason about too many ideas.
Example prompt:
You are a research assistant helping me create a 2-page market trends summary.
- Use reasoning_effort: low
- Do not explore topics outside the 2023–2025 data.
- Stop if you cannot find at least 3 credible sources.
- Keep going until you've fully summarized the 3 trends and written the final draft.
Progress you can follow (tool preambles)
Long tasks build trust when the model explains what it’s doing. The guide encourages short “preambles” before and during tool calls: restate the goal, outline the plan, narrate key steps, then summarize what changed. This doesn’t add fluff; it helps humans review and step in without derailing momentum.
Example prompt:
Your job is to clean and analyze a CSV file.
Before you start, restate the task in one sentence and outline the steps you will take.
When using a tool, explain what you're doing in 1–2 sentences before calling it.
After each step, summarize the result in under 50 words.
Right-sized thinking (reasoning effort)
The reasoning_effort parameter is your depth dial: keep it moderate for routine tasks, raise it for multi-step or tricky problems, and crucially break big tasks into distinct turns so the model plans and checks work in stages. That structure improves both quality and speed.
Example prompt:
You are solving a logic puzzle.
- Use reasoning_effort: high
- Explain your reasoning before giving the final answer.
- If the puzzle takes more than 5 steps to solve, break it into stages and confirm with me after each stage.
Better multi-step flows with the Responses API
If you’re building tools or agents around GPT-5, the Responses API lets the model reuse its prior reasoning instead of re-planning from scratch. OpenAI reports measurable gains just by making that switch (they cite a Tau-Bench Retail bump from ~73.9% to ~78.2% when passing prior reasoning), which means in practice to lower cost, faster latency, and more stable behavior.
Example prompt:
{
"model": "gpt-5",
"previous_response_id": "resp_12345",
"input": "Now summarize the insights from the analysis above in bullet points."
}
Coding with GPT-5
GPT-5 can build new apps or make large, multi-file edits, but the standout tip is to codify taste and standards:
- Frameworks: Next.js (TypeScript), React, HTML
- Styling / UI: Tailwind CSS, shadcn/ui, Radix Themes
- Icons: Material Symbols, Heroicons, Lucide
- Animation: Motion
- Fonts: San Serif, Inter, Geist, Mona Sans, IBM Plex Sans, Manrope
The GPT-5 model can hunt for context (like installed packages) without needing special prompts, and a short “code editing rules” block encourages it to follow your house style.
Example prompt:
You are editing an existing React app.
- Follow BEM CSS naming.
- Use Tailwind for styling.
- Place all new components in /src/components/ui.
- Maintain camelCase for function names.
- Use only hooks for state management.
Now, add a responsive navbar with a dropdown menu that matches the existing color palette.
A practical pattern from Cursor
Cursor, an AI code editor that tested GPT-5 early, found a useful balance:
- Set verbosity low for regular text so the assistant stays concise, but ask for high verbosity inside code tools so diffs are readable with clear variable names.
They also learned to soften old “analyze everything” prompts, which made earlier models thorough but nudged GPT-5 to overuse tools. The fix—structured sections and clearer scope—reduced unnecessary calls and kept autonomy high.
Example prompt:
Global setting: verbosity=low
When providing code edits:
- Switch verbosity to high
- Include full diffs with comments explaining each change
- Use descriptive variable names
Two separate dials: thinking vs. talking (verbosity)
GPT-5 adds a verbosity parameter that controls the length of the final answer (separate from how hard it thinks). Keep a concise global default, then override locally where detail matters. For example, tasks such as code explanations or audit trails. You can also steer verbosity with plain language inside the prompt.
Example prompt:
Verbosity: low
Task: Summarize this 20-page report in 200 words.
If I type "explain more", increase verbosity, and give a detailed breakdown.
Instruction precision matters
GPT-5 follows directions with “surgical” accuracy, which is powerful and at the same time unforgiving. If your prompt includes conflicts (“never schedule without consent” next to “auto-assign before contacting”), the model wastes tokens reconciling rules. Clean hierarchies and explicit exceptions fix that. The guide even shows a healthcare example and how rewriting it makes reasoning faster and clearer. Use OpenAI’s prompt optimizer to spot these issues.
Example prompt (❌ bad):
Never schedule meetings without consent.
Always schedule the earliest available time.
Fixed prompt (✅ good):
Only schedule meetings with explicit consent.
If consent is given, choose the earliest available time.
Minimal reasoning for speed
There’s also a minimal-effort mode: the fastest option that still benefits from the reasoning model pattern. It shines on latency-sensitive tasks when paired with a short “why” summary, clear tool preambles, and an explicit plan.
The model spends fewer reasoning tokens on figuring out how to solve the problem before writing the answer, and won’t do as much step-by-step planning inside its hidden reasoning process. If you still want it to complete a multi-step task or follow a structured approach, you have to build that structure into your prompt. For example:
- Explicitly list the steps you want it to take.
- Provide templates, headings, or formats that it should fill in.
- State exactly what information goes where and in what order.
This “scaffolding” works like the outline of a building: it gives the model a clear frame to follow when it’s not spending much time figuring things out for itself.
If you don’t provide that, minimal reasoning mode might give you a shallow, incomplete, or disorganized answer—because it’s skipping the deeper planning phase.
Example prompt:
Minimal reasoning
Extract all email addresses from the following text and output as a comma-separated list.
Do not include any other text.
Formatting defaults and overrides
By default, API responses aren’t in Markdown. If your app expects headings, lists, and code fences, say so—briefly and precisely—and refresh that instruction every few turns in long chats to keep the formatting consistent.
Example prompt:
Output your response in Markdown format.
- Use H2 headings
- Bullet points for lists
- Code blocks with language tags for code snippets
Metaprompting with GPT-5
When a prompt underperforms, ask GPT-5 to critique it: what to add, delete, or clarify to elicit the behavior you want, without removing everything that already works. It’s a low-effort way to improve the prompts you rely on daily.
Example prompt:
Here is my current prompt: "Write a friendly product description for our coffee shop."
Critique this prompt and suggest 3 specific changes that would make the output warmer, more detailed, and in a consistent brand voice.
Why this matters
The main idea of the guide is to maintain control without micromanaging. You set a small number of dials—how much to think, how much to say, how persistent to be—and describe your environment with just enough detail for the model to blend in. In return, you get better hand-offs, fewer stalls, and code or documents that feel like they were made by your team. Most importantly, the fixes are the kind you can try this afternoon: trim a conflicting line, add a persistence clause, split a big job into steps, or move to the Responses API if you’re doing tool-based work.
In Conclusion:
Good prompts aren’t fancy—they’re specific. GPT-5 rewards that specificity: clear stop conditions, right-sized reasoning, a steady narration of what it’s doing, and a tidy set of rules for how work should look when it’s done. Treat the guide as a checklist, not a lecture. Start small, measure, and keep your prompts short, scoped, and consistent. The payoff is an assistant that feels less like a chat window and more like a reliable teammate, one you can trust to plan, execute, and finish the job.
🤝
For Partnership/Promotion on AI Tools Club, please check out our
partnership page.
↗️ GPT-5 Prompting Guide
AI Tools Club

 August 13, 2025
August 13, 2025
 Star us on GitHub
Star us on GitHub Join our ML Subreddit
Join our ML Subreddit  Sponsor us
Sponsor us