AI hallucinations became a headline story when Google’s AI Overviews told people that cats can teleport and suggested eating rocks for health.
Those bizarre moments spread fast because they’re easy to point at and laugh about.
But that’s not the kind of AI hallucination most marketers deal with. The tools you probably use, like ChatGPT or Claude, likely won’t produce anything that bizarre. Their misses are sneakier, like outdated numbers or confident explanations that fall apart once you start looking under the hood.
In a fast-moving industry like digital marketing, it’s easy to miss those subtle errors.
This made us curious: How often is AI actually getting it wrong? What types of questions trip it up? And how are marketers handling the fallout?
To find out, we tested 600 prompts across major large language model (LLM) platforms and surveyed 565 marketers to understand how often AI gets things wrong. You’ll see how these mistakes show up in real workflows and what you can do to catch hallucinations before they hurt your work.
Key Takeaways
- Nearly half of marketers (47.1 percent) encounter AI inaccuracies several times a week, and over 70 percent spend hours fact-checking each week.
- More than a third (36.5 percent) say hallucinated or incorrect AI content has gone live publicly, most often due to false facts, broken source links, or inappropriate language.
- In our LLM test, ChatGPT had the highest accuracy (59.7 percent), but even the best models made errors, especially on multi-part reasoning, niche topics, or real-time questions.
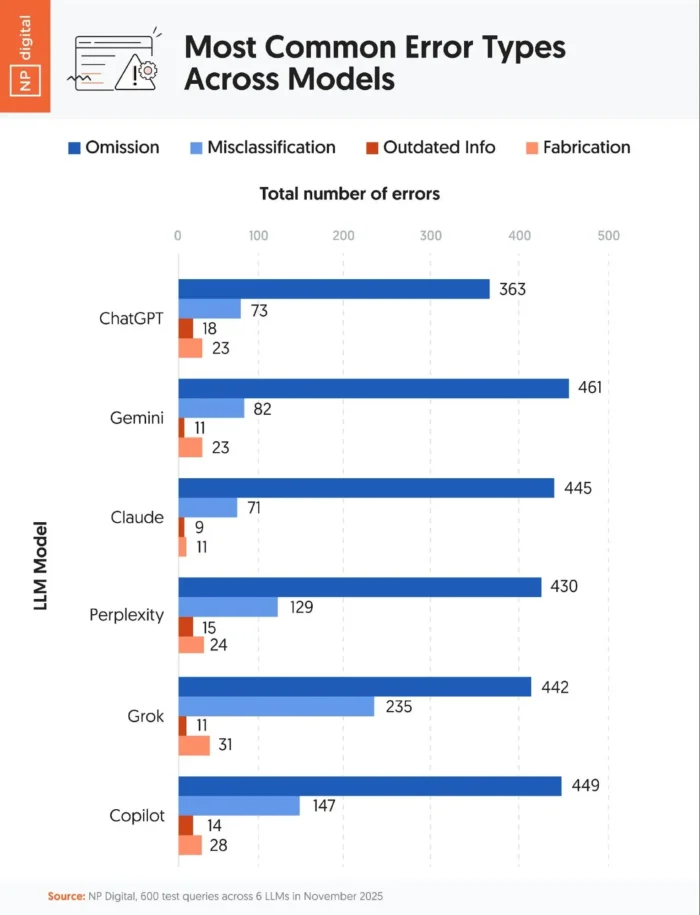
- The most common hallucination types were fabrication, omission, outdated info, and misclassification—often delivered with confident language.
- Despite knowledge of hallucinations, 23 percent of marketers feel confident using AI outputs without review. Most teams add extra approval layers or assign dedicated fact-checkers to their processes.
What Do We Know About AI Hallucinations and Errors?
An AI hallucination happens when a model gives you an answer that sounds correct but isn’t. We’re talking about made-up facts or claims that don’t stand up to fact-checking or a quick Google search.
And they’re not rare.
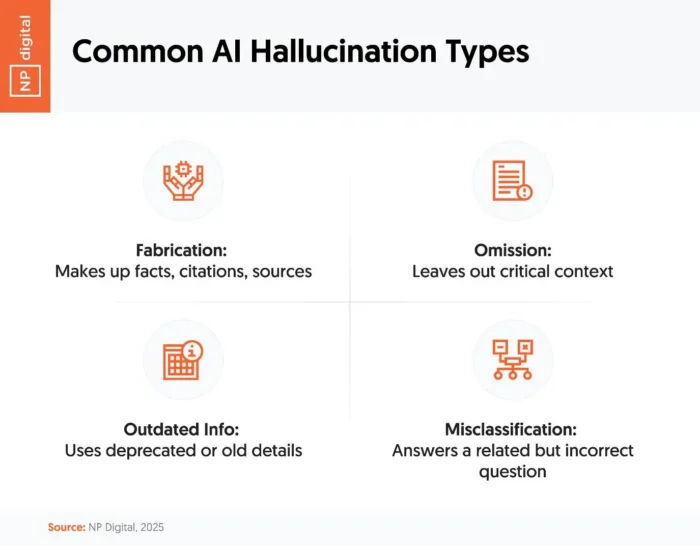
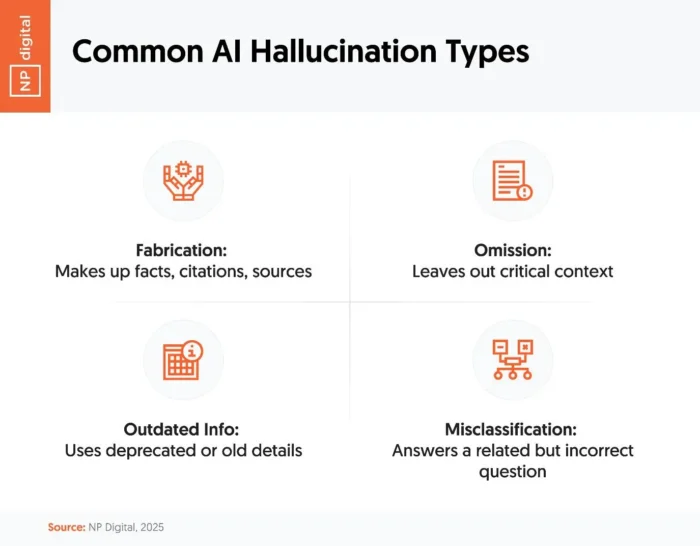
In our research, over 43% of marketers say hallucinated or false information has slipped past review and gone public. These errors come in a few common forms:
- Fabrication: The AI simply makes something up.
- Omission: It skips critical context or details.
- Outdated info: It shares data that’s no longer accurate.
- Misclassification: It answers the wrong question, or only part of it.
Hallucinations tend to happen when prompts are too vague or require multi-step reasoning. Sometimes the AI model tries to fill the gaps with whatever seems plausible.
AI hallucinations aren’t new, but our dependence on these tools is. As they become part of everyday workflows, the cost of a single incorrect answer increases.
Once you recognize the patterns behind these mistakes, you can catch them early and keep them out of your content.
AI Hallucination Examples
AI hallucinations can be ridiculous or dangerously subtle. These real AI hallucination examples give you a sense of the range:
- Fabricated legal citations: Recent reporting shows a growing number of lawyers relying on AI-generated filings, only to learn that the cases or citations don’t exist. Courts are now flagging these hallucinations at an alarming rate.
- Health misinformation: Revisiting our example from earlier, Google’s AI Overviews once claimed eating rocks had health benefits in an error that briefly went viral.
- Fake academic references: Some LLMs will list fake studies or broken source links if asked for citations. A peer-reviewed Nature study found that ChatGPT frequently produced academic citations that look legitimate but reference papers that don’t exist.
- Factual contradictions: Some tools have answered simple yes/no questions with completely contradictory statements in the same paragraph.
- Outdated or misattributed data: Models can pull statistics from the wrong year or tie them to the wrong sources. And that creates problems once those numbers sneak into presentations or content.
Our Surveys/Methodology
To get a clear picture of how AI hallucinations show up in real-world marketing work, we pulled data from two original sources:
- Marketers survey: We surveyed 565 U.S.-based digital marketers using AI in their workflows. The questions covered how often they spot errors, what kinds of mistakes they see, and how their teams are adjusting to AI-assisted content. We also asked about public slip-ups, trust in AI, and whether they want clearer industry standards.
- LLM accuracy test: We built a set of 600 prompts across five categories: SEO/marketing, general business, industry-specific verticals, consumer queries, and control questions with a known correct answer. We then tested them across six major AI platforms: ChatGPT, Gemini, Claude, Perplexity, Grok, and Copilot. Humans graded each output, classifying them as fully correct, partially correct, or incorrect. For partially correct or incorrect outputs, we also logged the error type (omission, outdated info, fabrication, or misclassification).
For this report, we focused only on text-based hallucinations and content errors, not visual or video generation. The insights that follow combine both data sets to show how hallucinations happen and what marketers should watch for across tools and task types.
How AI Hallucinations and Errors Impact Digital Marketers

We asked marketers how AI errors show up in their work, and the results were clear: Hallucinations are far from a rarity.
Nearly half of marketers (47.1 percent) encounter AI inaccuracies multiple times a week. And more than 70 percent say they spend one to five hours each week just fact-checking AI-generated output. That’s a lot of time spent fixing “helpful” content.
Those misses don’t always stay hidden.
More than a third (36.5 percent) say hallucinated content has made it all the way to the public. Another 39.8 percent have had close calls where bad AI info almost went live.
And it’s not just teams spotting the problems. More than half of marketers (57.7 percent) say clients or stakeholders have questioned the quality of AI-assisted outputs.
These aren’t minor formatting issues, either. When mistakes make it through, the most common offenders are:
- Inappropriate or brand-unsafe content (53.9 percent)
- Completely false or hallucinated information (43.5 percent)
- Formatting glitches that break the user experience (42.5 percent)
So where does it break down?
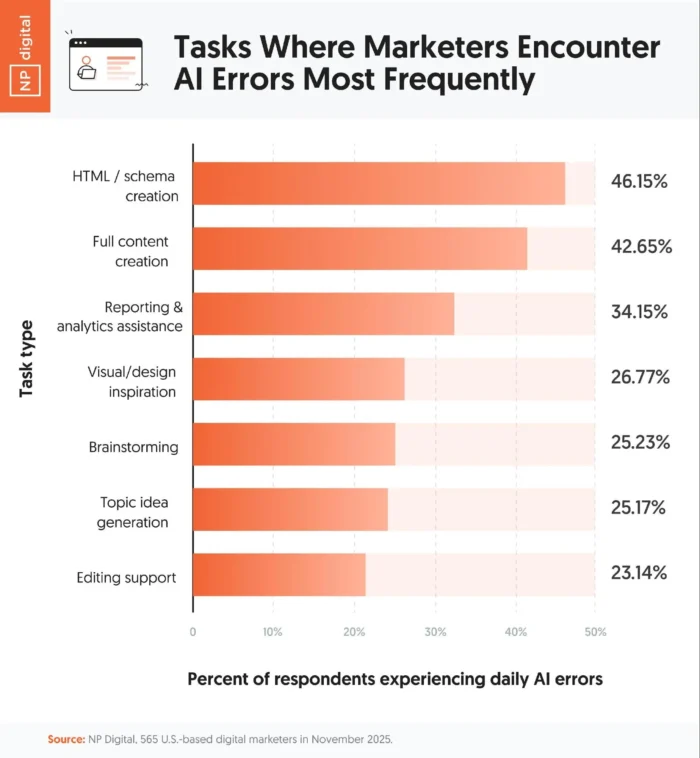
AI errors are most common in tasks that require structure or precision. Here are the daily error rates by task:
- HTML or schema creation: 46.2 percent
- Full content writing: 42.7 percent
- Reporting and analytics: 34.2 percent
Brainstorming or idea generation had far fewer issues, with each landing at right about 25 percent.
When we looked at confidence levels, only 23 percent of marketers felt fully comfortable using AI output without review. The rest? They were either cautious or not confident at all.
Teams hit hardest by public-facing AI mistakes include:
- Digital PR (33.3 percent)
- Content marketing (20.8 percent)
- Paid media (17.8 percent)
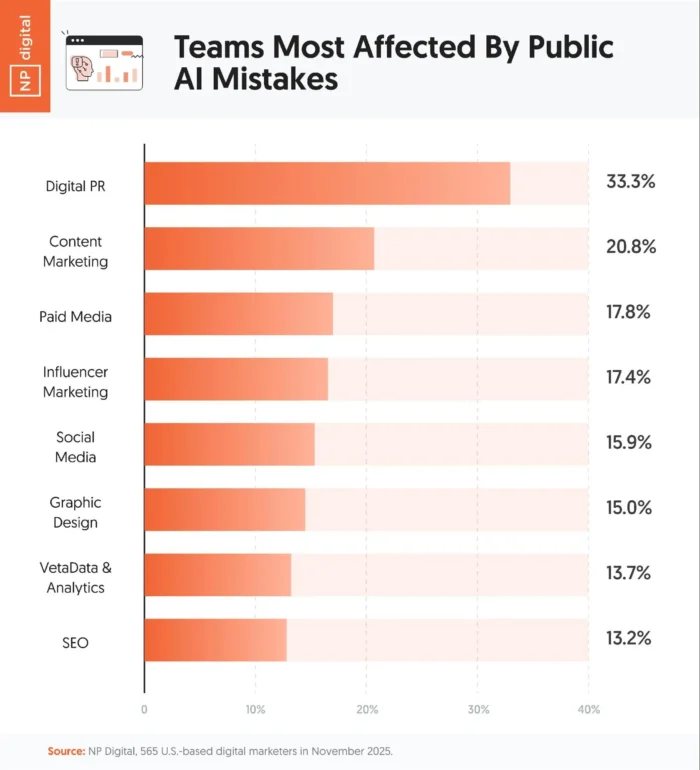
These are the same departments most likely to face direct brand damage when AI gets it wrong.
AI can save you time, but it also creates a lot of cleanup without checks in place. And most marketers feel the pressure to catch hallucinations before clients or customers do.
AI Hallucinations and Errors: How Do the Top LLMs Stack Up?
To figure out how often leading AI platforms hallucinate, we tested 600 prompts across six major models: ChatGPT, Claude, Gemini, Perplexity, Grok, and Copilot.
Each model received the same set of queries across five categories: marketing/SEO, general business, industry-specific use cases, consumer questions, and fact-checkable control prompts. Human reviewers graded each response for accuracy and completeness.
Here’s how they performed:
- ChatGPT delivered the highest percentage of fully correct answers at 59.7 percent, with the lowest rate of serious hallucinations. Most of its mistakes were subtle, like misinterpreting the question rather than fabricating facts.
- Claude was the most consistent. While it scored slightly lower on fully correct responses (55.1 percent), it had the lowest overall error rate at just 6.2 percent. When it missed, it usually left something out rather than getting it wrong.
- Gemini performed well on simple prompts (51.3 percent fully correct) but tended to skip over complex or multi-step answers. Its most common error was omission.
- Perplexity showed strength in fast-moving fields like crypto and AI, thanks to its strong real-time retrieval features. But that speed came with risk: 12.2 percent of responses were incorrect, often due to misclassifications or minor fabrications.
- Copilot sat in the middle of the pack. It gave safe, brief answers. While that’s good for overviews, it often misses the deeper context.
- Grok struggled across the board. It had the highest error rate at 21.8 percent and the lowest percentage of fully correct answers (39.6 percent). Hallucinations, contradictions, and vague outputs were common.

So, what does this mean for marketers?
Well, most teams aren’t expecting perfection. According to our survey, 77.7 percent of marketers will accept some level of AI inaccuracy, likely because the speed and efficiency gains still outweigh the cleanup.
The takeaway isn’t that one model is flawless. It’s that every tool has its strengths and weaknesses. Knowing each platform’s tendencies helps you know when (and how) to pull a human into the loop and what to be on guard against.
What Question Types Gave LLMs The Most Trouble
Some questions are harder for AI to handle than others. In our testing, three prompt types consistently tripped up all the models, regardless of how accurate they were overall:
- Multi-part prompts: When asked to explain a concept and give an example, many tools did only half the job. They either defined the term or gave an example, but not both. This was a common source of partial answers and context gaps.
- Recently updated or real-time topics: If the ask was about something that changed in the last few months (like a Google algorithm update or an AI model release), responses were often inaccurate or completely fabricated. Some tools made confident claims using outdated info that sounded fresh.
- Niche or domain-specific questions: Verticals like crypto, legal, SaaS, or even SEO created problems for most LLMs. In these cases, tools either made up terminology or gave vague responses that missed key industry context.
Even models like Claude and ChatGPT, which scored relatively high for accuracy, showed cracks when asked to handle layered prompts that required nuance or specialized knowledge.
Knowing which types of prompts increase the risk of hallucination is the first step in writing better ones and catching issues before they cost you.
AI Hallucination Tells to Look Out For
AI hallucinations don’t always scream “wrong.” In fact, the most dangerous ones sound reasonable (at least until you check the details). Still, there are patterns worth watching for:
Here are the red flags that showed up most often across the models we tested:
- No source, or a broken one: If an AI gives you a link, check it. A lot of hallucinated answers include made-up or outdated citations that don’t exist when you click.
- Answers to the wrong questions: Some models misinterpret the prompt and go off in a related (but incorrect) direction. If the response feels slightly off topic, dig deeper.
- Big claims with no specifics: Watch for sweeping statements without specific stats or dates. That’s often a sign it’s filling in blanks with plausible-sounding fluff.
- Stats with no attribution: Hallucinated numbers are a common issue. If the stat sounds surprising or overly convenient, verify it with a trusted source.
- Contradictions inside the same answer: We experienced cases where an AI said one thing in the first paragraph and contradicted itself by the end. That’s a major warning sign.
- “Real” examples that don’t exist: Some hallucinations involve fake product names, companies, case studies, or legal precedents. These details feel legit, but a quick search reveals no facts to verify these claims.
The more complex your prompt, the more important it is to sanity-check the output. If something feels even slightly off, assume it’s worth a second look. After all, subtle hallucinations are the ones most likely to slip through the cracks.
Best Practices for Avoiding AI Hallucinations and Errors
You can’t eliminate AI hallucinations completely, but you can make it a lot less likely they slip through. Here’s how to stay ahead of the risk:
- Always request and verify sources: Some models will confidently provide links that look legit but don’t exist. Others reference real studies or stats, but take them out of context. Before you copy/paste, click through. This matters even more for AI SEO work, where accuracy and citation quality directly affect rankings and trust.
- Fine-tune your prompts: Vague prompts are hallucination magnets, so be clear about what you want the model to reference or avoid. That might mean building prompt template libraries or using follow-up prompts to guide models more effectively. That’s exactly what LLM optimization (LLMO) focuses on.
- Assign a dedicated fact-checker: Our survey results showed this to be one of the most effective internal safeguards. Human review might take more time, but it’s how you keep hallucinated claims from damaging trust or a brand’s credibility.
- Set clear internal guidelines: Many teams now treat AI like a junior content assistant: It can draft, synthesize, and suggest, but humans own the final version. That means reviewing and fact-checking outputs and correcting anything that doesn’t hold up. This approach lines up with the data. Nearly half (48.3 percent) of marketers support industry-wide standards for responsible AI use.
- Add a final review layer every time: Even fast-moving brands are building in one more layer of review for AI-assisted work. In fact, the most common adjustment marketers reported making was adding a new round of content review to catch AI errors. That said, 23 percent of respondents reported skipping human review if they trust the tool enough. That’s a risky move.
- Don’t blindly trust brand-safe output: AI can sound polished even when it’s wrong. In our LLM testing, some of the most confidently written outputs were factually incorrect or missing key context. If it feels too clean, double-check it.
FAQs
What are AI hallucinations?
AI hallucinations occur when an AI tool gives you an answer that sounds accurate, but it’s not. These mistakes can include made-up facts, fake citations, or outdated info packaged in confident language.
Why Does AI hallucinate?
AI models don’t “know” facts. They generate responses based on patterns in the data they were trained on. When there’s a gap or ambiguity, the model fills it in with what sounds most likely (even if it’s completely wrong).
What causes AI hallucinations?
Hallucinations usually happen when prompts are vague, complex, or involve topics the model hasn’t seen enough data on. They’re also more common in fast-changing fields like SEO and crypto.
Can you stop AI from hallucinating?
Not entirely. Even the best models make things up sometimes. That’s because LLMs are built to generate language, not verify facts. Occasional hallucinations are baked into how they work.
How can you reduce AI hallucinations?
Use more specific prompts, request citation sources, and always double-check the output for accuracy. Add a human review step before anything goes live. The more structure and context you give the AI, the fewer hallucinations you’ll run into.
Conclusion
AI is powerful, but it’s not perfect.
Our research shows that hallucinations happen regularly, even with the best tools. From made-up stats to misinterpreted prompts, the risks are real. That’s especially the case for fast-moving marketers.
If you’re using AI to create content or guide strategy, knowing where these tools fall short is like a cheat code.
The best defense? Smarter prompts, tighter reviews, and clear internal guidelines that treat AI as a co-pilot (not the driver).
Want help building a more reliable AI workflow? Talk to our team at NP Digital if you’re ready to scale content without compromising accuracy. Also, you can check out the full report here on the NP Digital website.